NASH: Neural Architecture and Accelerator Search for Multiplication-Reduced Hybrid Models

0
Sign in to get full access
Overview
- Introduces a novel approach called NASH (Neural Architecture and Accelerator Search) for jointly optimizing neural network architectures and hardware accelerators to create efficient "multiplication-reduced hybrid models"
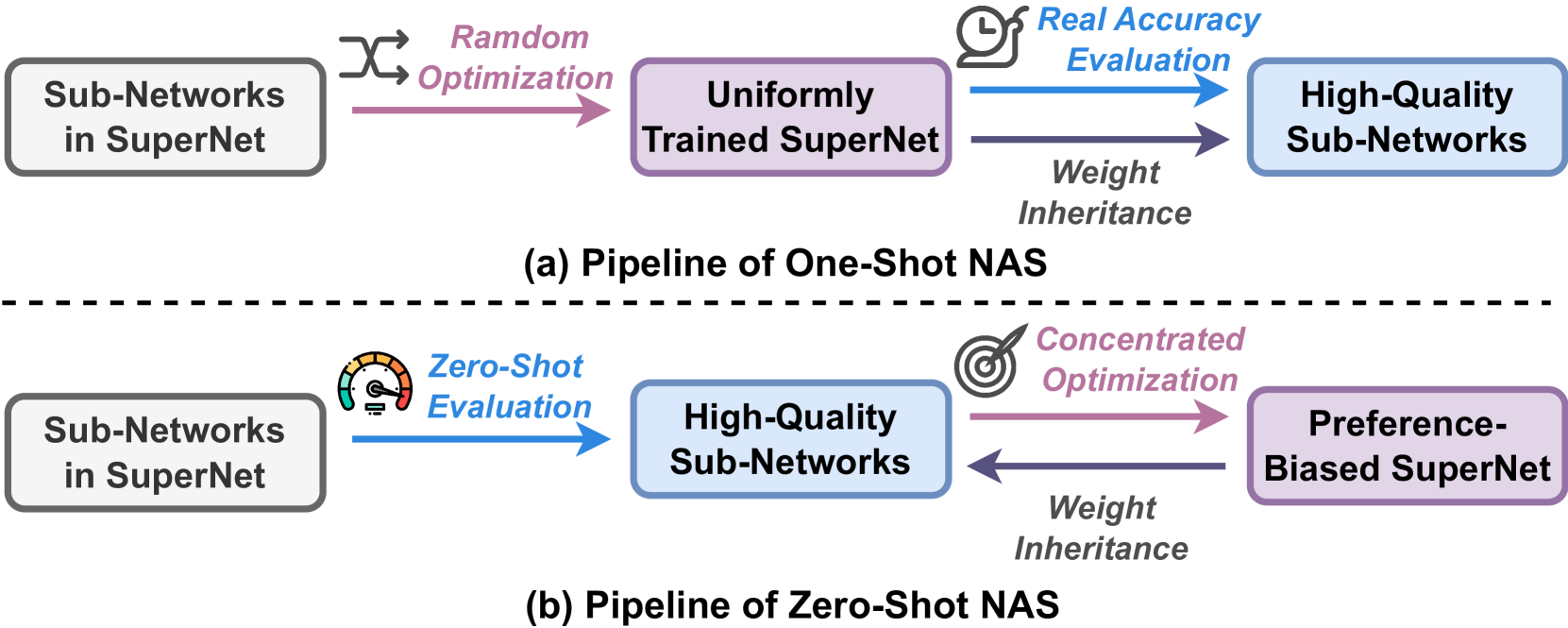
- Enables "zero-shot" search to find optimal models and accelerators without training, by leveraging predictive models
- Key innovations include co-searching neural architectures and hardware accelerators, and joint algorithm-hardware optimization
Plain English Explanation
The paper describes a new method called NASH (Neural Architecture and Accelerator Search) that aims to design efficient deep learning models by simultaneously optimizing the neural network architecture and the hardware accelerator that will run the model. The key idea is to create "multiplication-reduced hybrid models" - neural networks that have fewer computationally expensive multiplication operations, which can then be efficiently executed on specialized hardware.
Rather than training many different model and accelerator combinations, the researchers developed a "zero-shot" search approach that uses predictive models to estimate the performance of candidate architectures and accelerators without actually training them. This allows them to efficiently explore a large design space to find the optimal combination of model and hardware.
The co-search of neural architectures and hardware accelerators, along with the joint optimization of the algorithm and hardware, are the core innovations of this work. This integrated approach allows them to create highly efficient deep learning solutions that are tailored to the target hardware.
Technical Explanation
The key technical components of NASH are:
-
Neural Architecture Search: The researchers use a differentiable neural architecture search (NAS) approach to explore a large space of candidate neural network architectures. This allows them to efficiently search for models with reduced multiplication operations.
-
Accelerator Search: In parallel, NASH searches for the optimal hardware accelerator to run the neural network. This includes parameters like the number and type of processing elements, memory configurations, and other architectural choices.
-
Joint Optimization: NASH co-optimizes the neural network architecture and the hardware accelerator using a multi-objective optimization approach. This ensures that the final model and accelerator are well-matched and work together efficiently.
-
Predictive Performance Modeling: Instead of training each candidate model and accelerator combination, NASH uses predictive models to estimate their performance. This "zero-shot" search enables rapid exploration of the large design space.
The researchers demonstrate the effectiveness of NASH on a range of computer vision and natural language processing tasks, showing that it can produce highly efficient models that outperform standard approaches.
Critical Analysis
The paper provides a strong technical contribution in the area of joint neural architecture and hardware accelerator search. The key strengths are:
- The "zero-shot" search approach, enabled by the predictive performance modeling, is a clever way to efficiently explore the vast design space without expensive training.
- The integrated co-search and co-optimization of the neural network and accelerator is a novel and impactful innovation that can lead to significantly more efficient deep learning solutions.
However, some potential limitations or areas for further research include:
- The predictive performance models used in the zero-shot search may have biases or inaccuracies that could impact the quality of the final designs.
- The search space and optimization objectives considered in this work may not capture all the relevant factors for real-world deployment, such as energy efficiency, cost, and reliability.
- Extending the approach to more diverse hardware accelerator types and neural network architectures beyond the ones explored in the paper could further broaden its applicability.
Overall, the NASH approach represents an important step forward in the joint optimization of deep learning models and their underlying hardware, and the ideas presented in this work could have significant implications for the development of efficient and sustainable AI systems.
Conclusion
The NASH paper introduces a novel method for simultaneously optimizing neural network architectures and hardware accelerators to create highly efficient "multiplication-reduced hybrid models". By leveraging predictive performance modeling to enable a "zero-shot" search, NASH can rapidly explore a large design space and find the optimal combination of model and accelerator.
This integrated approach to algorithm and hardware co-optimization represents an important advancement in the field of efficient deep learning, with the potential to lead to more sustainable and powerful AI systems. The ideas presented in this work could have far-reaching implications for the future of machine learning and its real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
NASH: Neural Architecture and Accelerator Search for Multiplication-Reduced Hybrid Models
Yang Xu, Huihong Shi, Zhongfeng Wang
The significant computational cost of multiplications hinders the deployment of deep neural networks (DNNs) on edge devices. While multiplication-free models offer enhanced hardware efficiency, they typically sacrifice accuracy. As a solution, multiplication-reduced hybrid models have emerged to combine the benefits of both approaches. Particularly, prior works, i.e., NASA and NASA-F, leverage Neural Architecture Search (NAS) to construct such hybrid models, enhancing hardware efficiency while maintaining accuracy. However, they either entail costly retraining or encounter gradient conflicts, limiting both search efficiency and accuracy. Additionally, they overlook the acceleration opportunity introduced by accelerator search, yielding sub-optimal hardware performance. To overcome these limitations, we propose NASH, a Neural architecture and Accelerator Search framework for multiplication-reduced Hybrid models. Specifically, as for NAS, we propose a tailored zero-shot metric to pre-identify promising hybrid models before training, enhancing search efficiency while alleviating gradient conflicts. Regarding accelerator search, we innovatively introduce coarse-to-fine search to streamline the search process. Furthermore, we seamlessly integrate these two levels of searches to unveil NASH, obtaining the optimal model and accelerator pairing. Experiments validate our effectiveness, e.g., when compared with the state-of-the-art multiplication-based system, we can achieve $uparrow$$2.14times$ throughput and $uparrow$$2.01times$ FPS with $uparrow$$0.25%$ accuracy on CIFAR-100, and $uparrow$$1.40times$ throughput and $uparrow$$1.19times$ FPS with $uparrow$$0.56%$ accuracy on Tiny-ImageNet. Codes are available at url{https://github.com/xuyang527/NASH.}
Read more9/10/2024

0
Accel-NASBench: Sustainable Benchmarking for Accelerator-Aware NAS
Afzal Ahmad, Linfeng Du, Zhiyao Xie, Wei Zhang
One of the primary challenges impeding the progress of Neural Architecture Search (NAS) is its extensive reliance on exorbitant computational resources. NAS benchmarks aim to simulate runs of NAS experiments at zero cost, remediating the need for extensive compute. However, existing NAS benchmarks use synthetic datasets and model proxies that make simplified assumptions about the characteristics of these datasets and models, leading to unrealistic evaluations. We present a technique that allows searching for training proxies that reduce the cost of benchmark construction by significant margins, making it possible to construct realistic NAS benchmarks for large-scale datasets. Using this technique, we construct an open-source bi-objective NAS benchmark for the ImageNet2012 dataset combined with the on-device performance of accelerators, including GPUs, TPUs, and FPGAs. Through extensive experimentation with various NAS optimizers and hardware platforms, we show that the benchmark is accurate and allows searching for state-of-the-art hardware-aware models at zero cost.
Read more6/19/2024

0
Multi-Objective Neural Architecture Search for In-Memory Computing
Md Hasibul Amin, Mohammadreza Mohammadi, Ramtin Zand
In this work, we employ neural architecture search (NAS) to enhance the efficiency of deploying diverse machine learning (ML) tasks on in-memory computing (IMC) architectures. Initially, we design three fundamental components inspired by the convolutional layers found in VGG and ResNet models. Subsequently, we utilize Bayesian optimization to construct a convolutional neural network (CNN) model with adaptable depths, employing these components. Through the Bayesian search algorithm, we explore a vast search space comprising over 640 million network configurations to identify the optimal solution, considering various multi-objective cost functions like accuracy/latency and accuracy/energy. Our evaluation of this NAS approach for IMC architecture deployment spans three distinct image classification datasets, demonstrating the effectiveness of our method in achieving a balanced solution characterized by high accuracy and reduced latency and energy consumption.
Read more6/12/2024

0
Multi-Objective Hardware Aware Neural Architecture Search using Hardware Cost Diversity
Nilotpal Sinha, Peyman Rostami, Abd El Rahman Shabayek, Anis Kacem, Djamila Aouada
Hardware-aware Neural Architecture Search approaches (HW-NAS) automate the design of deep learning architectures, tailored specifically to a given target hardware platform. Yet, these techniques demand substantial computational resources, primarily due to the expensive process of assessing the performance of identified architectures. To alleviate this problem, a recent direction in the literature has employed representation similarity metric for efficiently evaluating architecture performance. Nonetheless, since it is inherently a single objective method, it requires multiple runs to identify the optimal architecture set satisfying the diverse hardware cost constraints, thereby increasing the search cost. Furthermore, simply converting the single objective into a multi-objective approach results in an under-explored architectural search space. In this study, we propose a Multi-Objective method to address the HW-NAS problem, called MO-HDNAS, to identify the trade-off set of architectures in a single run with low computational cost. This is achieved by optimizing three objectives: maximizing the representation similarity metric, minimizing hardware cost, and maximizing the hardware cost diversity. The third objective, i.e. hardware cost diversity, is used to facilitate a better exploration of the architecture search space. Experimental results demonstrate the effectiveness of our proposed method in efficiently addressing the HW-NAS problem across six edge devices for the image classification task.
Read more4/22/2024