Navigate Beyond Shortcuts: Debiased Learning through the Lens of Neural Collapse
2405.05587
0
0

Abstract
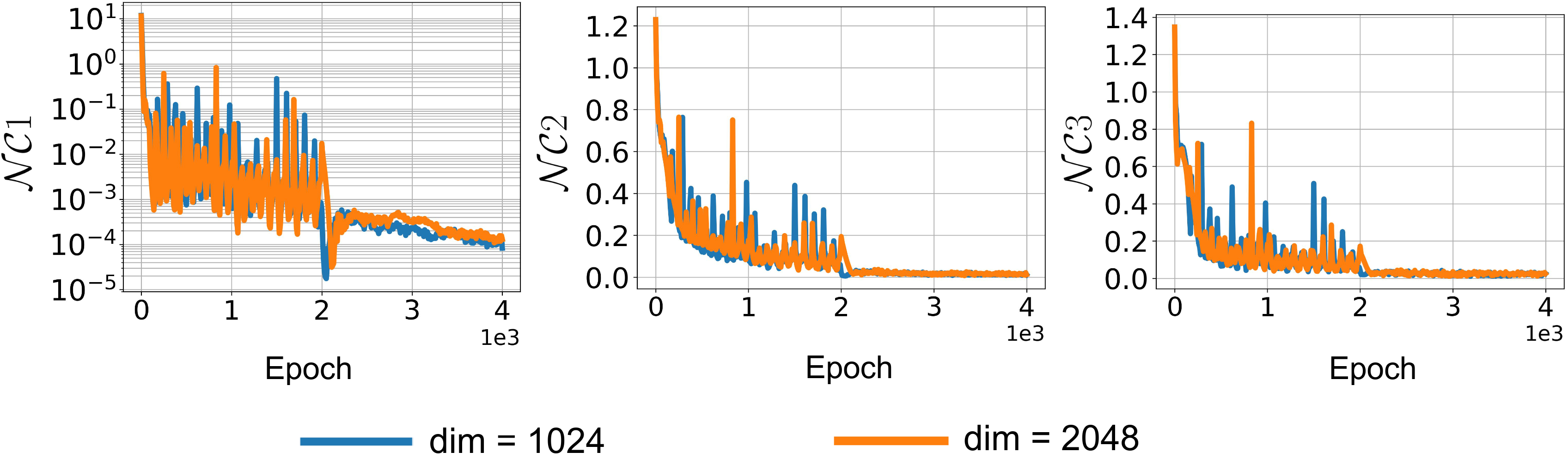
Recent studies have noted an intriguing phenomenon termed Neural Collapse, that is, when the neural networks establish the right correlation between feature spaces and the training targets, their last-layer features, together with the classifier weights, will collapse into a stable and symmetric structure. In this paper, we extend the investigation of Neural Collapse to the biased datasets with imbalanced attributes. We observe that models will easily fall into the pitfall of shortcut learning and form a biased, non-collapsed feature space at the early period of training, which is hard to reverse and limits the generalization capability. To tackle the root cause of biased classification, we follow the recent inspiration of prime training, and propose an avoid-shortcut learning framework without additional training complexity. With well-designed shortcut primes based on Neural Collapse structure, the models are encouraged to skip the pursuit of simple shortcuts and naturally capture the intrinsic correlations. Experimental results demonstrate that our method induces better convergence properties during training, and achieves state-of-the-art generalization performance on both synthetic and real-world biased datasets.
Create account to get full access
Overview
- The paper explores how neural networks can learn to make predictions beyond simple "shortcuts" by leveraging the phenomenon of "neural collapse" during training.
- It builds on prior research on progressive feedforward collapse, low-dimensional observations in deep learning, and understanding neural plasticity through collapse.
- The authors propose a technique called "OccamNets" to mitigate dataset biases by favoring simpler neural network models, drawing on insights from the OccamNets paper.
- The paper also explores how activating hidden spatial invariance can help neural networks learn more robust and generalizable representations.
Plain English Explanation
Neural networks are powerful machine learning models that can learn to make predictions from data. However, they sometimes learn "shortcuts" - relying on superficial patterns in the training data rather than learning the underlying principles that generate the data.
This paper explores how the phenomenon of "neural collapse" during training can help neural networks overcome these shortcuts and learn more robust and generalizable representations. Neural collapse refers to the observation that as neural networks are trained, the activations in their hidden layers gradually converge towards a low-dimensional subspace.
The authors propose a technique called "OccamNets" that leverages this neural collapse to favor simpler neural network models, which are less prone to learning shortcuts. By encouraging the network to use the simplest possible representation to solve the task, OccamNets can help mitigate dataset biases and improve the network's ability to generalize.
The paper also explores how activating "hidden spatial invariance" - the network's ability to recognize patterns regardless of their spatial arrangement - can further enhance the network's robustness and generalization. By tilting or transforming the input images, the network can learn to focus on the relevant features rather than relying on superficial cues.
Overall, this research provides insights into how neural networks can learn beyond simple shortcuts by harnessing the principles of neural collapse and spatial invariance. These techniques have the potential to improve the reliability and real-world applicability of AI systems.
Technical Explanation
The paper begins by discussing the challenge of neural networks learning "shortcuts" - relying on superficial patterns in the training data rather than learning the underlying generative principles. This can lead to poor generalization to new, unseen data.
To address this issue, the authors build on prior research on progressive feedforward collapse and low-dimensional observations in deep learning. They observe that during training, neural network activations tend to converge towards a low-dimensional subspace, a phenomenon known as "neural collapse."
The authors propose a technique called "OccamNets" that leverages this neural collapse to favor simpler neural network models, which are less prone to learning shortcuts. OccamNets draw inspiration from the OccamNets paper, which showed that favoring simpler models can help mitigate dataset biases.
Additionally, the paper explores how activating hidden spatial invariance can further enhance the network's robustness and generalization. By transforming the input images (e.g., tilting them), the network is forced to focus on the relevant features rather than relying on superficial cues, leading to more robust and generalizable representations.
The authors conduct experiments on various datasets and tasks to validate their approach, demonstrating that OccamNets and spatial invariance can indeed help neural networks learn beyond simple shortcuts and improve their generalization capabilities.
Critical Analysis
The paper presents a compelling approach to addressing the challenge of neural networks learning shortcuts, leveraging the principles of neural collapse and spatial invariance. The authors' focus on favoring simpler models through OccamNets is a promising direction, as it aligns with the broader goal of developing more reliable and interpretable AI systems.
One potential limitation of the study is the need for further investigation into the generalizability of the proposed techniques across a wider range of tasks and datasets. While the experiments demonstrate the effectiveness of OccamNets and spatial invariance on the tested scenarios, it would be valuable to explore their performance in more diverse and realistic settings.
Additionally, the paper could benefit from a deeper exploration of the underlying mechanisms that drive neural collapse and spatial invariance. A more comprehensive understanding of these phenomena could lead to further refinements and optimizations of the techniques presented.
It would also be interesting to see how the proposed approaches compare to or potentially complement other methods for mitigating dataset biases and improving generalization, such as domain adaptation or causal reasoning techniques.
Overall, the research presented in this paper represents an important step towards developing more robust and generalizable AI systems. By continuing to explore the principles of neural collapse and spatial invariance, the field can make progress in navigating beyond the limitations of simple shortcuts and building AI models that are truly capable of learning the underlying patterns in data.
Conclusion
This paper makes a valuable contribution to the field of machine learning by exploring how the phenomenon of neural collapse and the activation of hidden spatial invariance can help neural networks learn beyond simple shortcuts and develop more robust and generalizable representations.
The proposed OccamNets technique, which favors simpler neural network models, holds promise for mitigating dataset biases and improving the reliability of AI systems. By combining this approach with the insights from research on spatial invariance, the authors demonstrate a comprehensive strategy for enhancing the generalization capabilities of neural networks.
The findings presented in this paper have significant implications for the development of more trustworthy and real-world applicable AI technologies. As the field continues to grapple with the challenges of dataset biases and overfitting, the insights from this research can inform the design of future AI systems, ultimately leading to more reliable and impactful applications of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Neural Collapse for Cross-entropy Class-Imbalanced Learning with Unconstrained ReLU Feature Model
Hien Dang, Tho Tran, Tan Nguyen, Nhat Ho
0
0
The current paradigm of training deep neural networks for classification tasks includes minimizing the empirical risk that pushes the training loss value towards zero, even after the training error has been vanished. In this terminal phase of training, it has been observed that the last-layer features collapse to their class-means and these class-means converge to the vertices of a simplex Equiangular Tight Frame (ETF). This phenomenon is termed as Neural Collapse (NC). To theoretically understand this phenomenon, recent works employ a simplified unconstrained feature model to prove that NC emerges at the global solutions of the training problem. However, when the training dataset is class-imbalanced, some NC properties will no longer be true. For example, the class-means geometry will skew away from the simplex ETF when the loss converges. In this paper, we generalize NC to imbalanced regime for cross-entropy loss under the unconstrained ReLU feature model. We prove that, while the within-class features collapse property still holds in this setting, the class-means will converge to a structure consisting of orthogonal vectors with different lengths. Furthermore, we find that the classifier weights are aligned to the scaled and centered class-means with scaling factors depend on the number of training samples of each class, which generalizes NC in the class-balanced setting. We empirically prove our results through experiments on practical architectures and dataset.
6/7/2024
🧠
Neural Collapse versus Low-rank Bias: Is Deep Neural Collapse Really Optimal?
Peter S'uken'ik, Marco Mondelli, Christoph Lampert
0
0
Deep neural networks (DNNs) exhibit a surprising structure in their final layer known as neural collapse (NC), and a growing body of works has currently investigated the propagation of neural collapse to earlier layers of DNNs -- a phenomenon called deep neural collapse (DNC). However, existing theoretical results are restricted to special cases: linear models, only two layers or binary classification. In contrast, we focus on non-linear models of arbitrary depth in multi-class classification and reveal a surprising qualitative shift. As soon as we go beyond two layers or two classes, DNC stops being optimal for the deep unconstrained features model (DUFM) -- the standard theoretical framework for the analysis of collapse. The main culprit is a low-rank bias of multi-layer regularization schemes: this bias leads to optimal solutions of even lower rank than the neural collapse. We support our theoretical findings with experiments on both DUFM and real data, which show the emergence of the low-rank structure in the solution found by gradient descent.
5/24/2024
Kernel vs. Kernel: Exploring How the Data Structure Affects Neural Collapse
Vignesh Kothapalli, Tom Tirer
0
0
Recently, a vast amount of literature has focused on the Neural Collapse (NC) phenomenon, which emerges when training neural network (NN) classifiers beyond the zero training error point. The core component of NC is the decrease in the within class variability of the network's deepest features, dubbed as NC1. The theoretical works that study NC are typically based on simplified unconstrained features models (UFMs) that mask any effect of the data on the extent of collapse. In this paper, we provide a kernel-based analysis that does not suffer from this limitation. First, given a kernel function, we establish expressions for the traces of the within- and between-class covariance matrices of the samples' features (and consequently an NC1 metric). Then, we turn to focus on kernels associated with shallow NNs. First, we consider the NN Gaussian Process kernel (NNGP), associated with the network at initialization, and the complement Neural Tangent Kernel (NTK), associated with its training in the lazy regime. Interestingly, we show that the NTK does not represent more collapsed features than the NNGP for prototypical data models. As NC emerges from training, we then consider an alternative to NTK: the recently proposed adaptive kernel, which generalizes NNGP to model the feature mapping learned from the training data. Contrasting our NC1 analysis for these two kernels enables gaining insights into the effect of data distribution on the extent of collapse, which are empirically aligned with the behavior observed with practical training of NNs.
7/1/2024
🤔
Towards understanding neural collapse in supervised contrastive learning with the information bottleneck method
Siwei Wang, Stephanie E Palmer
0
0
Neural collapse describes the geometry of activation in the final layer of a deep neural network when it is trained beyond performance plateaus. Open questions include whether neural collapse leads to better generalization and, if so, why and how training beyond the plateau helps. We model neural collapse as an information bottleneck (IB) problem in order to investigate whether such a compact representation exists and discover its connection to generalization. We demonstrate that neural collapse leads to good generalization specifically when it approaches an optimal IB solution of the classification problem. Recent research has shown that two deep neural networks independently trained with the same contrastive loss objective are linearly identifiable, meaning that the resulting representations are equivalent up to a matrix transformation. We leverage linear identifiability to approximate an analytical solution of the IB problem. This approximation demonstrates that when class means exhibit $K$-simplex Equiangular Tight Frame (ETF) behavior (e.g., $K$=10 for CIFAR10 and $K$=100 for CIFAR100), they coincide with the critical phase transitions of the corresponding IB problem. The performance plateau occurs once the optimal solution for the IB problem includes all of these phase transitions. We also show that the resulting $K$-simplex ETF can be packed into a $K$-dimensional Gaussian distribution using supervised contrastive learning with a ResNet50 backbone. This geometry suggests that the $K$-simplex ETF learned by supervised contrastive learning approximates the optimal features for source coding. Hence, there is a direct correspondence between optimal IB solutions and generalization in contrastive learning.
6/28/2024