NavRL: Learning Safe Flight in Dynamic Environments

0

Sign in to get full access
Overview
- Introduces a reinforcement learning (RL) approach called NavRL for safe navigation of autonomous drones in dynamic environments
- Focuses on learning collision-free flight policies that can adapt to changing obstacles and conditions
- Demonstrates the effectiveness of NavRL through simulation experiments and real-world flight tests
Plain English Explanation
The paper presents a reinforcement learning method called NavRL that allows autonomous drones to navigate safely in dynamic environments. In these environments, the obstacles and conditions can change rapidly, so the drone needs to be able to adapt its flight path on the fly to avoid collisions.
The key idea behind NavRL is to train the drone using RL techniques to learn an optimal policy for collision-free flight. This involves rewarding the drone for actions that keep it away from obstacles and other hazards, while penalizing actions that lead to potential collisions. Over many training iterations, the drone learns to make the right decisions to navigate safely through the environment.
The paper demonstrates the effectiveness of NavRL through both simulation experiments and real-world flight tests. The results show that drones using the NavRL approach are able to navigate complex, dynamic environments without colliding with obstacles. This has important applications for tasks like autonomous drone delivery, search and rescue operations, and other scenarios where drones need to operate safely in unpredictable conditions.
Technical Explanation
The paper introduces the NavRL framework, which combines a deep reinforcement learning agent with a simulated drone environment to learn safe navigation policies. The RL agent uses a proximal policy optimization (PPO) algorithm to iteratively update its policy based on the rewards it receives for its actions.
The key architectural components of NavRL include:
- Simulated Drone Environment: A high-fidelity simulation of a drone operating in a dynamic 3D environment with moving obstacles.
- Observation Space: The RL agent's observation space includes the drone's current state (position, velocity, orientation) as well as the positions and velocities of nearby obstacles.
- Action Space: The agent can output thrust and torque commands to control the drone's motion.
- Reward Function: The reward function encourages the agent to navigate through the environment while avoiding collisions with obstacles.
Through extensive training in the simulated environment, the NavRL agent learns an optimal policy for safe flight. The paper evaluates this policy through both simulation experiments and real-world flight tests, demonstrating the agent's ability to navigate complex, dynamic environments without collisions.
Critical Analysis
The paper presents a promising approach for enabling safe autonomous drone flight in dynamic environments. The use of reinforcement learning allows the agent to learn effective navigation policies without requiring tedious manual programming or rule-based control.
However, the paper does acknowledge some limitations of the current NavRL framework:
- Simulation-to-Reality Gap: While the simulated environment is designed to be high-fidelity, there may still be discrepancies between the simulation and the real-world that could impact the agent's performance.
- Scalability: The paper only demonstrates NavRL in relatively small-scale environments. Scaling the approach to larger, more complex environments may present additional challenges.
- Generalization: The agent's learned policy may not generalize well to significantly different environments or tasks beyond basic navigation.
To address these limitations, the authors suggest several directions for future research, such as improving the simulation-to-reality transfer, exploring hierarchical RL approaches, and investigating ways to make the agent's policy more generalizable.
Overall, the NavRL paper represents an important step forward in the development of safe and adaptive autonomous drone navigation systems. While there is still work to be done, the results demonstrate the potential of reinforcement learning to enable more robust and capable autonomous flight in dynamic, real-world environments.
Conclusion
The NavRL paper presents a reinforcement learning-based approach for enabling autonomous drones to navigate safely in dynamic environments. By learning an optimal policy for collision-free flight, the NavRL agent is able to adapt to changing obstacles and conditions, as demonstrated through both simulation experiments and real-world flight tests.
This work has important implications for a wide range of applications involving autonomous drones, such as delivery, search and rescue, and environmental monitoring. The ability to navigate complex, unpredictable environments without collisions is a critical capability for unlocking the full potential of these robotic systems.
While the current NavRL framework has some limitations, the authors outline promising directions for future research to address these challenges. As the field of autonomous robotics continues to advance, methods like NavRL will play an increasingly important role in ensuring the safe and reliable operation of drones and other autonomous vehicles in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
NavRL: Learning Safe Flight in Dynamic Environments
Zhefan Xu, Xinming Han, Haoyu Shen, Hanyu Jin, Kenji Shimada
Safe flight in dynamic environments requires autonomous unmanned aerial vehicles (UAVs) to make effective decisions when navigating cluttered spaces with moving obstacles. Traditional approaches often decompose decision-making into hierarchical modules for prediction and planning. Although these handcrafted systems can perform well in specific settings, they might fail if environmental conditions change and often require careful parameter tuning. Additionally, their solutions could be suboptimal due to the use of inaccurate mathematical model assumptions and simplifications aimed at achieving computational efficiency. To overcome these limitations, this paper introduces the NavRL framework, a deep reinforcement learning-based navigation method built on the Proximal Policy Optimization (PPO) algorithm. NavRL utilizes our carefully designed state and action representations, allowing the learned policy to make safe decisions in the presence of both static and dynamic obstacles, with zero-shot transfer from simulation to real-world flight. Furthermore, the proposed method adopts a simple but effective safety shield for the trained policy, inspired by the concept of velocity obstacles, to mitigate potential failures associated with the black-box nature of neural networks. To accelerate the convergence, we implement the training pipeline using NVIDIA Isaac Sim, enabling parallel training with thousands of quadcopters. Simulation and physical experiments show that our method ensures safe navigation in dynamic environments and results in the fewest collisions compared to benchmarks in scenarios with dynamic obstacles.
Read more9/25/2024

0
Navigation in a simplified Urban Flow through Deep Reinforcement Learning
Federica Tonti, Jean Rabault, Ricardo Vinuesa
The increasing number of unmanned aerial vehicles (UAVs) in urban environments requires a strategy to minimize their environmental impact, both in terms of energy efficiency and noise reduction. In order to reduce these concerns, novel strategies for developing prediction models and optimization of flight planning, for instance through deep reinforcement learning (DRL), are needed. Our goal is to develop DRL algorithms capable of enabling the autonomous navigation of UAVs in urban environments, taking into account the presence of buildings and other UAVs, optimizing the trajectories in order to reduce both energetic consumption and noise. This is achieved using fluid-flow simulations which represent the environment in which UAVs navigate and training the UAV as an agent interacting with an urban environment. In this work, we consider a domain domain represented by a two-dimensional flow field with obstacles, ideally representing buildings, extracted from a three-dimensional high-fidelity numerical simulation. The presented methodology, using PPO+LSTM cells, was validated by reproducing a simple but fundamental problem in navigation, namely the Zermelo's problem, which deals with a vessel navigating in a turbulent flow, travelling from a starting point to a target location, optimizing the trajectory. The current method shows a significant improvement with respect to both a simple PPO and a TD3 algorithm, with a success rate (SR) of the PPO+LSTM trained policy of 98.7%, and a crash rate (CR) of 0.1%, outperforming both PPO (SR = 75.6%, CR=18.6%) and TD3 (SR=77.4% and CR=14.5%). This is the first step towards DRL strategies which will guide UAVs in a three-dimensional flow field using real-time signals, making the navigation efficient in terms of flight time and avoiding damages to the vehicle.
Read more9/27/2024
🏅
0
Research on Autonomous Robots Navigation based on Reinforcement Learning
Zixiang Wang, Hao Yan, Yining Wang, Zhengjia Xu, Zhuoyue Wang, Zhizhong Wu
Reinforcement learning continuously optimizes decision-making based on real-time feedback reward signals through continuous interaction with the environment, demonstrating strong adaptive and self-learning capabilities. In recent years, it has become one of the key methods to achieve autonomous navigation of robots. In this work, an autonomous robot navigation method based on reinforcement learning is introduced. We use the Deep Q Network (DQN) and Proximal Policy Optimization (PPO) models to optimize the path planning and decision-making process through the continuous interaction between the robot and the environment, and the reward signals with real-time feedback. By combining the Q-value function with the deep neural network, deep Q network can handle high-dimensional state space, so as to realize path planning in complex environments. Proximal policy optimization is a strategy gradient-based method, which enables robots to explore and utilize environmental information more efficiently by optimizing policy functions. These methods not only improve the robot's navigation ability in the unknown environment, but also enhance its adaptive and self-learning capabilities. Through multiple training and simulation experiments, we have verified the effectiveness and robustness of these models in various complex scenarios.
Read more8/15/2024
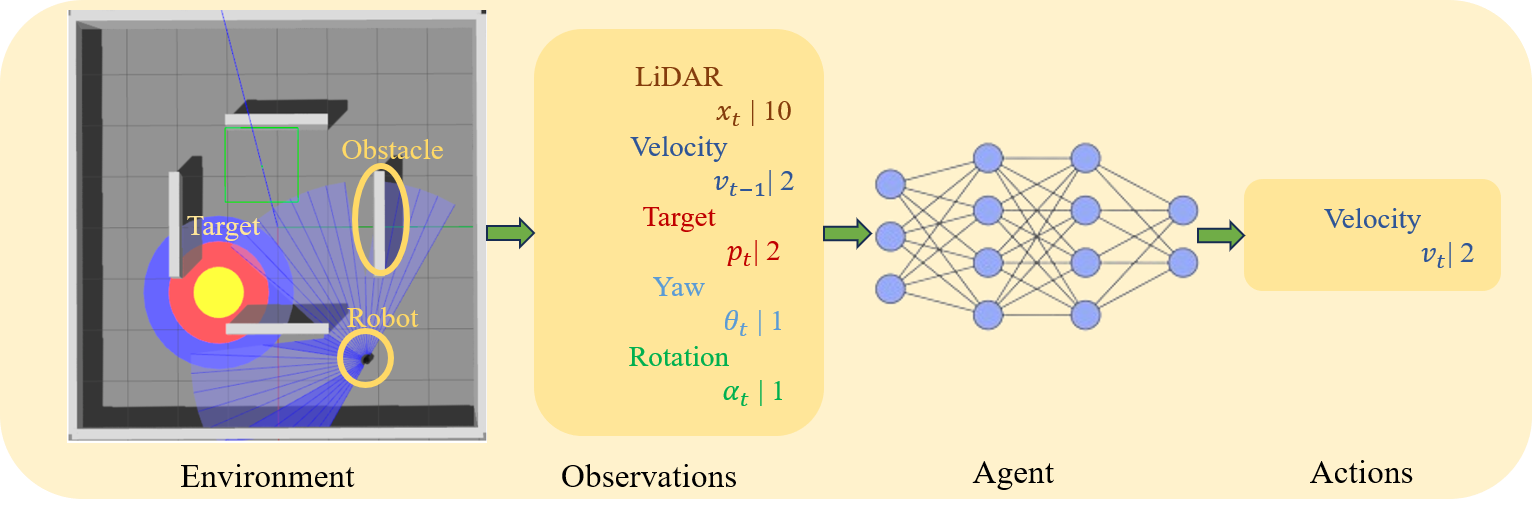
0
Deep Reinforcement Learning with Enhanced PPO for Safe Mobile Robot Navigation
Hamid Taheri, Seyed Rasoul Hosseini, Mohammad Ali Nekoui
Collision-free motion is essential for mobile robots. Most approaches to collision-free and efficient navigation with wheeled robots require parameter tuning by experts to obtain good navigation behavior. This study investigates the application of deep reinforcement learning to train a mobile robot for autonomous navigation in a complex environment. The robot utilizes LiDAR sensor data and a deep neural network to generate control signals guiding it toward a specified target while avoiding obstacles. We employ two reinforcement learning algorithms in the Gazebo simulation environment: Deep Deterministic Policy Gradient and proximal policy optimization. The study introduces an enhanced neural network structure in the Proximal Policy Optimization algorithm to boost performance, accompanied by a well-designed reward function to improve algorithm efficacy. Experimental results conducted in both obstacle and obstacle-free environments underscore the effectiveness of the proposed approach. This research significantly contributes to the advancement of autonomous robotics in complex environments through the application of deep reinforcement learning.
Read more8/9/2024