Research on Autonomous Robots Navigation based on Reinforcement Learning

0
🏅
Sign in to get full access
Overview
- This paper introduces an autonomous robot navigation method based on reinforcement learning.
- The authors use Deep Q Network (DQN) and Proximal Policy Optimization (PPO) models to optimize the path planning and decision-making process.
- The methods aim to improve the robot's navigation ability in unknown environments and enhance its adaptive and self-learning capabilities.
- Through experiments, the authors have verified the effectiveness and robustness of these models in various complex scenarios.
Plain English Explanation
Reinforcement learning is a type of machine learning that helps robots and other systems learn by trial and error. The robot interacts with its environment, taking actions and receiving rewards or penalties based on the results. Over time, the robot learns which actions lead to the best outcomes and can make better decisions.
In this research, the authors used two specific reinforcement learning techniques, Deep Q Network (DQN) and Proximal Policy Optimization (PPO), to help a robot navigate through complex environments.
The DQN method allows the robot to learn from high-dimensional sensor data, like camera images, to plan its path. The PPO method helps the robot explore its environment more efficiently and optimize its decision-making policy.
By combining these techniques, the researchers were able to create a robot that could navigate unknown environments more effectively and adapt to changing conditions. This could be useful for applications like search and rescue, warehouse automation, or self-driving cars.
Technical Explanation
The authors used Deep Q Network (DQN) and Proximal Policy Optimization (PPO) to optimize the robot's path planning and decision-making process.
DQN is a reinforcement learning algorithm that uses a deep neural network to approximate the Q-value function, which represents the expected long-term reward for each possible action in a given state. By combining the Q-value function with a deep neural network, DQN can handle high-dimensional state spaces, allowing the robot to plan paths in complex environments.
PPO is a policy gradient-based reinforcement learning method that optimizes the robot's policy function, which determines its actions. PPO enables the robot to explore and utilize environmental information more efficiently by continuously updating its policy based on feedback from the environment.
The authors conducted multiple training and simulation experiments to evaluate the effectiveness and robustness of their approach in various complex scenarios. The results demonstrate that the combination of DQN and PPO can significantly improve the robot's navigation ability in unknown environments and enhance its adaptive and self-learning capabilities.
Critical Analysis
The paper provides a comprehensive explanation of the reinforcement learning-based approach for autonomous robot navigation, including the technical details of the DQN and PPO models. However, the authors do not explicitly address some potential limitations or areas for further research.
For example, the paper does not discuss how the method might perform in real-world, dynamic environments with obstacles, moving targets, or other unpredictable factors. The simulation experiments were conducted in static, controlled scenarios, and it's unclear how well the approach would translate to more complex, real-world situations.
Additionally, the paper does not address the computational and memory requirements of the DQN and PPO models, which could be a practical concern for deploying these techniques on resource-constrained robotic platforms.
Further research could explore the robustness and scalability of the proposed approach, as well as investigate ways to improve its efficiency and applicability to a wider range of real-world robotic navigation tasks, such as adaptive speed planning for unmanned vehicles or quantum-enhanced robot navigation.
Conclusion
This research introduces an autonomous robot navigation method based on reinforcement learning, specifically utilizing Deep Q Network (DQN) and Proximal Policy Optimization (PPO) models. The authors demonstrate that this approach can improve the robot's navigation ability in unknown environments and enhance its adaptive and self-learning capabilities.
The findings of this work have the potential to contribute to the development of more robust and versatile autonomous navigation systems for a wide range of robotic applications, such as search and rescue operations, warehouse automation, and self-driving vehicles. Further research is needed to address the limitations and explore the scalability of the proposed methods in real-world, dynamic environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Research on Autonomous Robots Navigation based on Reinforcement Learning
Zixiang Wang, Hao Yan, Yining Wang, Zhengjia Xu, Zhuoyue Wang, Zhizhong Wu
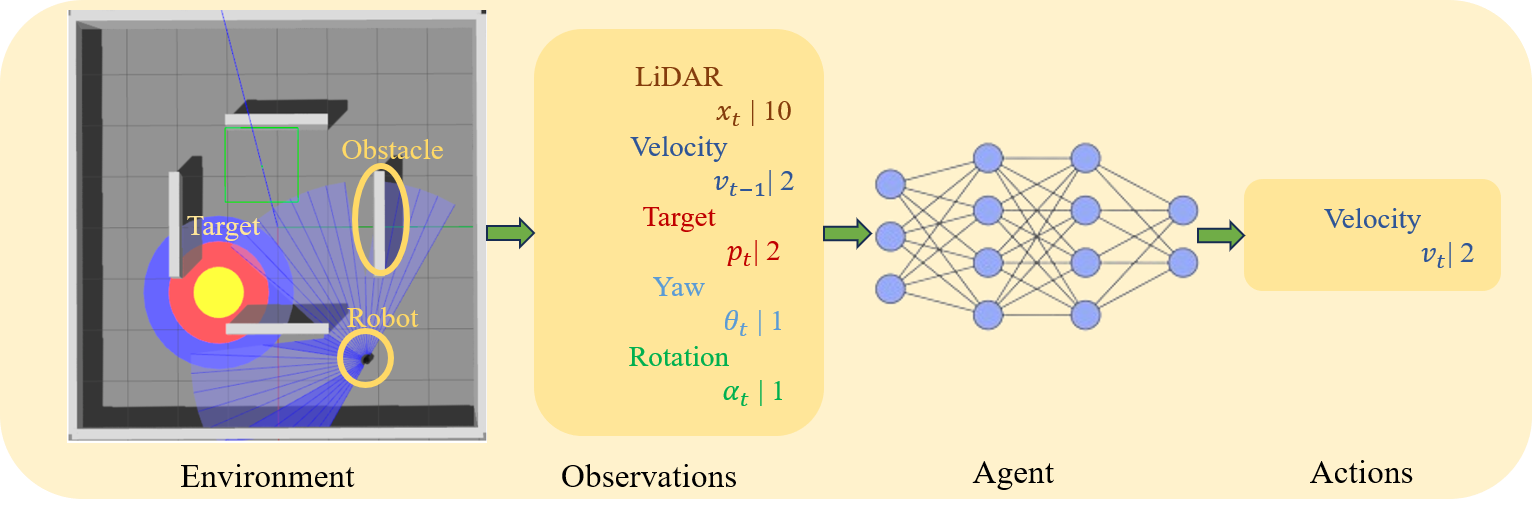
Reinforcement learning continuously optimizes decision-making based on real-time feedback reward signals through continuous interaction with the environment, demonstrating strong adaptive and self-learning capabilities. In recent years, it has become one of the key methods to achieve autonomous navigation of robots. In this work, an autonomous robot navigation method based on reinforcement learning is introduced. We use the Deep Q Network (DQN) and Proximal Policy Optimization (PPO) models to optimize the path planning and decision-making process through the continuous interaction between the robot and the environment, and the reward signals with real-time feedback. By combining the Q-value function with the deep neural network, deep Q network can handle high-dimensional state space, so as to realize path planning in complex environments. Proximal policy optimization is a strategy gradient-based method, which enables robots to explore and utilize environmental information more efficiently by optimizing policy functions. These methods not only improve the robot's navigation ability in the unknown environment, but also enhance its adaptive and self-learning capabilities. Through multiple training and simulation experiments, we have verified the effectiveness and robustness of these models in various complex scenarios.
Read more8/15/2024
0
Deep Reinforcement Learning with Enhanced PPO for Safe Mobile Robot Navigation
Hamid Taheri, Seyed Rasoul Hosseini, Mohammad Ali Nekoui
Collision-free motion is essential for mobile robots. Most approaches to collision-free and efficient navigation with wheeled robots require parameter tuning by experts to obtain good navigation behavior. This study investigates the application of deep reinforcement learning to train a mobile robot for autonomous navigation in a complex environment. The robot utilizes LiDAR sensor data and a deep neural network to generate control signals guiding it toward a specified target while avoiding obstacles. We employ two reinforcement learning algorithms in the Gazebo simulation environment: Deep Deterministic Policy Gradient and proximal policy optimization. The study introduces an enhanced neural network structure in the Proximal Policy Optimization algorithm to boost performance, accompanied by a well-designed reward function to improve algorithm efficacy. Experimental results conducted in both obstacle and obstacle-free environments underscore the effectiveness of the proposed approach. This research significantly contributes to the advancement of autonomous robotics in complex environments through the application of deep reinforcement learning.
Read more8/9/2024
🤿
0
Research on Autonomous Driving Decision-making Strategies based Deep Reinforcement Learning
Zixiang Wang, Hao Yan, Changsong Wei, Junyu Wang, Shi Bo, Minheng Xiao
The behavior decision-making subsystem is a key component of the autonomous driving system, which reflects the decision-making ability of the vehicle and the driver, and is an important symbol of the high-level intelligence of the vehicle. However, the existing rule-based decision-making schemes are limited by the prior knowledge of designers, and it is difficult to cope with complex and changeable traffic scenarios. In this work, an advanced deep reinforcement learning model is adopted, which can autonomously learn and optimize driving strategies in a complex and changeable traffic environment by modeling the driving decision-making process as a reinforcement learning problem. Specifically, we used Deep Q-Network (DQN) and Proximal Policy Optimization (PPO) for comparative experiments. DQN guides the agent to choose the best action by approximating the state-action value function, while PPO improves the decision-making quality by optimizing the policy function. We also introduce improvements in the design of the reward function to promote the robustness and adaptability of the model in real-world driving situations. Experimental results show that the decision-making strategy based on deep reinforcement learning has better performance than the traditional rule-based method in a variety of driving tasks.
Read more8/7/2024
🤿
0
Autonomous Navigation of Unmanned Vehicle Through Deep Reinforcement Learning
Letian Xu, Jiabei Liu, Haopeng Zhao, Tianyao Zheng, Tongzhou Jiang, Lipeng Liu
This paper explores the method of achieving autonomous navigation of unmanned vehicles through Deep Reinforcement Learning (DRL). The focus is on using the Deep Deterministic Policy Gradient (DDPG) algorithm to address issues in high-dimensional continuous action spaces. The paper details the model of a Ackermann robot and the structure and application of the DDPG algorithm. Experiments were conducted in a simulation environment to verify the feasibility of the improved algorithm. The results demonstrate that the DDPG algorithm outperforms traditional Deep Q-Network (DQN) and Double Deep Q-Network (DDQN) algorithms in path planning tasks.
Read more7/30/2024