Nearest is Not Dearest: Towards Practical Defense against Quantization-conditioned Backdoor Attacks

0
🧠
Sign in to get full access
Overview
- Model quantization is a technique used to compress and accelerate deep neural networks
- Recent studies have revealed the feasibility of weaponizing model quantization through a technique called quantization-conditioned backdoors (QCBs)
- QCBs are special backdoors that remain dormant in full-precision models but become activated after standard quantization
- Existing defenses have limited effectiveness against QCBs or are even infeasible
Plain English Explanation
Model quantization is a way to make deep learning models smaller and faster by reducing the precision of their internal calculations. This is done by converting the model's weights and activations from high-precision floating-point numbers to lower-precision integers or fixed-point numbers. David Goliath: Empirical Evaluation of Attacks and Defenses on Quantized Neural Networks, CBQ: Cross-Block Quantization for Large Language Models, Investigating the Impact of Quantization on Adversarial Robustness, RaBiT-Q: Quantizing High-Dimensional Vectors Theoretically, QCore: Data-Efficient Device-Continual Calibration for Quantized
However, researchers have discovered a way to exploit this quantization process to create "backdoors" in the model. These backdoors remain hidden in the original full-precision model but become activated when the model is quantized, potentially allowing an attacker to control the model's behavior. This is a concerning development, as existing defenses against these backdoors have limited effectiveness.
Technical Explanation
The paper's key insight is that the activation of existing QCBs primarily stems from the nearest rounding operation used in standard quantization, and is closely related to the norms of neuron-wise truncation errors (the difference between the continuous full-precision weights and their quantized versions).
Motivated by this, the researchers propose a new defense mechanism called Error-guided Flipped Rounding with Activation Preservation (EFRAP). EFRAP learns a non-nearest rounding strategy that is guided by both the neuron-wise error norm and layer-wise activation preservation. This allows EFRAP to flip the rounding strategies of neurons crucial for backdoor effects, while minimizing the impact on the model's clean accuracy.
The researchers extensively evaluate EFRAP on benchmark datasets and show that it can effectively defeat state-of-the-art QCB attacks under various settings.
Critical Analysis
The paper provides a thorough analysis of the QCB problem and proposes a promising defense mechanism in EFRAP. However, the researchers acknowledge that EFRAP may not be able to protect against all possible QCB attacks, as the attackers could develop more sophisticated techniques to bypass the defense.
Additionally, the paper focuses on a specific type of QCB attack and does not explore the broader implications of weaponizing model quantization. It would be valuable to see further research investigating other potential attack vectors and the overall security implications of model quantization techniques.
Conclusion
This paper makes an important contribution by shedding light on the security risks of model quantization and proposing an effective defense mechanism in EFRAP. As deep learning models become increasingly deployed in real-world applications, understanding and mitigating such vulnerabilities will be crucial to ensuring the trustworthiness and reliability of these systems. The insights and techniques presented in this work represent a significant step forward in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Nearest is Not Dearest: Towards Practical Defense against Quantization-conditioned Backdoor Attacks
Boheng Li, Yishuo Cai, Haowei Li, Feng Xue, Zhifeng Li, Yiming Li
Model quantization is widely used to compress and accelerate deep neural networks. However, recent studies have revealed the feasibility of weaponizing model quantization via implanting quantization-conditioned backdoors (QCBs). These special backdoors stay dormant on released full-precision models but will come into effect after standard quantization. Due to the peculiarity of QCBs, existing defenses have minor effects on reducing their threats or are even infeasible. In this paper, we conduct the first in-depth analysis of QCBs. We reveal that the activation of existing QCBs primarily stems from the nearest rounding operation and is closely related to the norms of neuron-wise truncation errors (i.e., the difference between the continuous full-precision weights and its quantized version). Motivated by these insights, we propose Error-guided Flipped Rounding with Activation Preservation (EFRAP), an effective and practical defense against QCBs. Specifically, EFRAP learns a non-nearest rounding strategy with neuron-wise error norm and layer-wise activation preservation guidance, flipping the rounding strategies of neurons crucial for backdoor effects but with minimal impact on clean accuracy. Extensive evaluations on benchmark datasets demonstrate that our EFRAP can defeat state-of-the-art QCB attacks under various settings. Code is available at https://github.com/AntigoneRandy/QuantBackdoor_EFRAP.
Read more5/22/2024
0
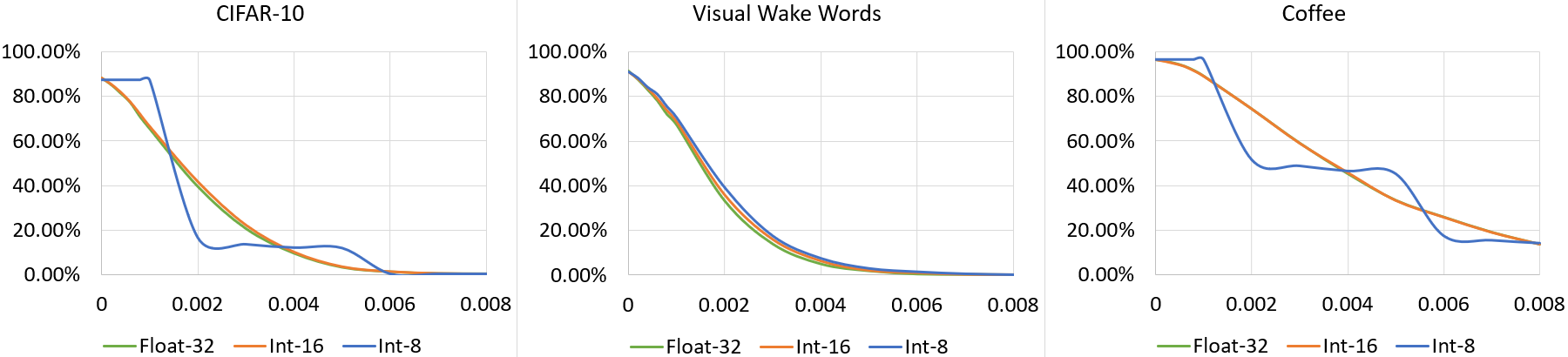
David and Goliath: An Empirical Evaluation of Attacks and Defenses for QNNs at the Deep Edge
Miguel Costa, Sandro Pinto
ML is shifting from the cloud to the edge. Edge computing reduces the surface exposing private data and enables reliable throughput guarantees in real-time applications. Of the panoply of devices deployed at the edge, resource-constrained MCUs, e.g., Arm Cortex-M, are more prevalent, orders of magnitude cheaper, and less power-hungry than application processors or GPUs. Thus, enabling intelligence at the deep edge is the zeitgeist, with researchers focusing on unveiling novel approaches to deploy ANNs on these constrained devices. Quantization is a well-established technique that has proved effective in enabling the deployment of neural networks on MCUs; however, it is still an open question to understand the robustness of QNNs in the face of adversarial examples. To fill this gap, we empirically evaluate the effectiveness of attacks and defenses from (full-precision) ANNs on (constrained) QNNs. Our evaluation includes three QNNs targeting TinyML applications, ten attacks, and six defenses. With this study, we draw a set of interesting findings. First, quantization increases the point distance to the decision boundary and leads the gradient estimated by some attacks to explode or vanish. Second, quantization can act as a noise attenuator or amplifier, depending on the noise magnitude, and causes gradient misalignment. Regarding adversarial defenses, we conclude that input pre-processing defenses show impressive results on small perturbations; however, they fall short as the perturbation increases. At the same time, train-based defenses increase the average point distance to the decision boundary, which holds after quantization. However, we argue that train-based defenses still need to smooth the quantization-shift and gradient misalignment phenomenons to counteract adversarial example transferability to QNNs. All artifacts are open-sourced to enable independent validation of results.
Read more5/6/2024
0
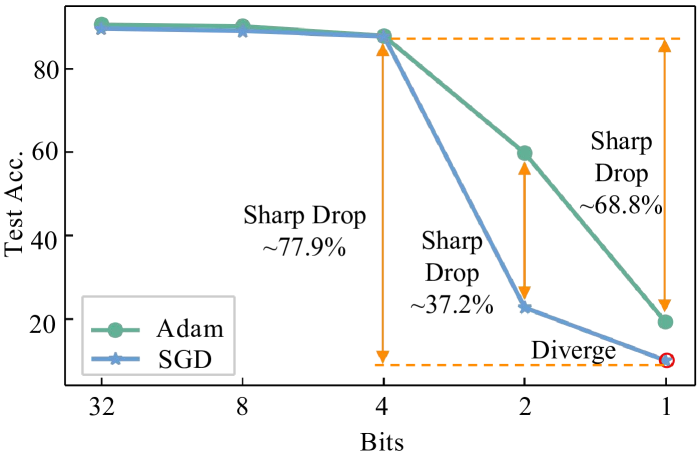
1-Bit FQT: Pushing the Limit of Fully Quantized Training to 1-bit
Chang Gao, Jianfei Chen, Kang Zhao, Jiaqi Wang, Liping Jing
Fully quantized training (FQT) accelerates the training of deep neural networks by quantizing the activations, weights, and gradients into lower precision. To explore the ultimate limit of FQT (the lowest achievable precision), we make a first attempt to 1-bit FQT. We provide a theoretical analysis of FQT based on Adam and SGD, revealing that the gradient variance influences the convergence of FQT. Building on these theoretical results, we introduce an Activation Gradient Pruning (AGP) strategy. The strategy leverages the heterogeneity of gradients by pruning less informative gradients and enhancing the numerical precision of remaining gradients to mitigate gradient variance. Additionally, we propose Sample Channel joint Quantization (SCQ), which utilizes different quantization strategies in the computation of weight gradients and activation gradients to ensure that the method is friendly to low-bitwidth hardware. Finally, we present a framework to deploy our algorithm. For fine-tuning VGGNet-16 and ResNet-18 on multiple datasets, our algorithm achieves an average accuracy improvement of approximately 6%, compared to per-sample quantization. Moreover, our training speedup can reach a maximum of 5.13x compared to full precision training.
Read more8/27/2024

0
COMQ: A Backpropagation-Free Algorithm for Post-Training Quantization
Aozhong Zhang, Zi Yang, Naigang Wang, Yingyong Qin, Jack Xin, Xin Li, Penghang Yin
Post-training quantization (PTQ) has emerged as a practical approach to compress large neural networks, making them highly efficient for deployment. However, effectively reducing these models to their low-bit counterparts without compromising the original accuracy remains a key challenge. In this paper, we propose an innovative PTQ algorithm termed COMQ, which sequentially conducts coordinate-wise minimization of the layer-wise reconstruction errors. We consider the widely used integer quantization, where every quantized weight can be decomposed into a shared floating-point scalar and an integer bit-code. Within a fixed layer, COMQ treats all the scaling factor(s) and bit-codes as the variables of the reconstruction error. Every iteration improves this error along a single coordinate while keeping all other variables constant. COMQ is easy to use and requires no hyper-parameter tuning. It instead involves only dot products and rounding operations. We update these variables in a carefully designed greedy order, significantly enhancing the accuracy. COMQ achieves remarkable results in quantizing 4-bit Vision Transformers, with a negligible loss of less than 1% in Top-1 accuracy. In 4-bit INT quantization of convolutional neural networks, COMQ maintains near-lossless accuracy with a minimal drop of merely 0.3% in Top-1 accuracy.
Read more6/5/2024