Nearest Neighbor Speculative Decoding for LLM Generation and Attribution

0

Sign in to get full access
Overview
- This paper introduces a novel technique called "Nearest Neighbor Speculative Decoding" (NNSD) for generating and attributing text using large language models (LLMs).
- NNSD aims to improve the quality and coherence of LLM-generated text by leveraging nearest neighbor search to guide the model's output.
- The authors demonstrate NNSD's effectiveness in several applications, including text generation, summarization, and authorship attribution.
Plain English Explanation
The paper explores a new way to generate and analyze text using large language models (LLMs) - computer systems trained on vast amounts of text data to understand and produce human-like language. The key idea behind this new technique, called "Nearest Neighbor Speculative Decoding" (NNSD), is to use the model's own knowledge to guide and refine the text it generates.
Normally, LLMs generate text by predicting the next word based on the previous words in the sequence. NNSD takes this a step further by looking at the model's "nearest neighbors" - similar passages of text in its training data - and using those to inform the model's next predictions. This helps the generated text be more coherent and natural-sounding, since it's drawing on relevant examples the model has seen before.
The paper demonstrates how NNSD can be applied to various text-related tasks, like generating summaries, attributing authorship, and producing high-quality text from scratch. By leveraging the model's internal knowledge in this way, the authors show that NNSD can outperform standard LLM techniques in terms of the fluency and faithfulness of the generated text.
Technical Explanation
The core idea behind Nearest Neighbor Speculative Decoding (NNSD) is to guide the output of large language models (LLMs) by incorporating information from the model's nearest neighbor passages during the decoding process. This builds on prior work in retrieval-augmented language model training and speculative decoding.
The authors first describe how NNSD works in the context of text generation. Given a prompt, the model performs a nearest neighbor search to find the most similar passages in its training data. It then uses these nearest neighbors to inform the next token predictions, biasing the model towards text that is more coherent and faithful to the provided context.
The paper also explores applying NNSD to other tasks, such as summarization and authorship attribution. In these cases, the nearest neighbor search is used to guide the model's output towards text that is more aligned with the desired task.
Through extensive experiments, the authors demonstrate that NNSD can significantly improve the quality and coherence of LLM-generated text across a range of applications. They also discuss some potential limitations and areas for future research, such as the computational overhead of the nearest neighbor search and the need for more sophisticated retrieval mechanisms.
Critical Analysis
The paper presents a well-designed and thorough exploration of the Nearest Neighbor Speculative Decoding (NNSD) technique. The authors provide a clear and compelling motivation for leveraging the model's internal knowledge to guide its text generation, and the experimental results support the effectiveness of their approach.
One potential limitation discussed in the paper is the computational overhead of the nearest neighbor search, which could limit the practical applicability of NNSD, especially for real-time text generation. The authors suggest that more efficient retrieval mechanisms or hardware acceleration could help address this issue, but further research would be needed to fully explore these possibilities.
Another area that could benefit from additional investigation is the sensitivity of NNSD to the quality and diversity of the model's training data. If the nearest neighbor passages used to guide the generation are not representative or sufficiently diverse, the technique may struggle to produce coherent and meaningful text. Exploring ways to mitigate this issue, such as through data augmentation or more advanced retrieval methods, could be a fruitful direction for future work.
Overall, the Nearest Neighbor Speculative Decoding approach represents a promising step forward in leveraging large language models for high-quality text generation and analysis. The authors have made a compelling case for the technique's potential, and their work lays the groundwork for further advancements in this area.
Conclusion
The paper introduces a novel technique called Nearest Neighbor Speculative Decoding (NNSD) that aims to improve the quality and coherence of text generated by large language models (LLMs). By incorporating information from the model's nearest neighbor passages during the decoding process, NNSD can guide the output towards more faithful and natural-sounding text.
The authors demonstrate the effectiveness of NNSD across several applications, including text generation, summarization, and authorship attribution. Their results suggest that this approach can significantly outperform standard LLM techniques in terms of the fluency and faithfulness of the generated text.
While the paper highlights some potential limitations, such as the computational overhead of the nearest neighbor search, the overall contribution of the Nearest Neighbor Speculative Decoding technique is significant. As large language models continue to play a growing role in various text-based applications, innovations like NNSD will be crucial in unlocking their full potential and ensuring the quality and reliability of the generated content.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Nearest Neighbor Speculative Decoding for LLM Generation and Attribution
Minghan Li, Xilun Chen, Ari Holtzman, Beidi Chen, Jimmy Lin, Wen-tau Yih, Xi Victoria Lin
Large language models (LLMs) often hallucinate and lack the ability to provide attribution for their generations. Semi-parametric LMs, such as kNN-LM, approach these limitations by refining the output of an LM for a given prompt using its nearest neighbor matches in a non-parametric data store. However, these models often exhibit slow inference speeds and produce non-fluent texts. In this paper, we introduce Nearest Neighbor Speculative Decoding (NEST), a novel semi-parametric language modeling approach that is capable of incorporating real-world text spans of arbitrary length into the LM generations and providing attribution to their sources. NEST performs token-level retrieval at each inference step to compute a semi-parametric mixture distribution and identify promising span continuations in a corpus. It then uses an approximate speculative decoding procedure that accepts a prefix of the retrieved span or generates a new token. NEST significantly enhances the generation quality and attribution rate of the base LM across a variety of knowledge-intensive tasks, surpassing the conventional kNN-LM method and performing competitively with in-context retrieval augmentation. In addition, NEST substantially improves the generation speed, achieving a 1.8x speedup in inference time when applied to Llama-2-Chat 70B.
Read more6/3/2024
💬
0
On Retrieval Augmentation and the Limitations of Language Model Training
Ting-Rui Chiang, Xinyan Velocity Yu, Joshua Robinson, Ollie Liu, Isabelle Lee, Dani Yogatama
Augmenting a language model (LM) with $k$-nearest neighbors ($k$NN) retrieval on its training data alone can decrease its perplexity, though the underlying reasons for this remain elusive. In this work, we rule out one previously posited possibility -- the softmax bottleneck. We then create a new dataset to evaluate LM generalization ability in the setting where training data contains additional information that is not causally relevant. This task is challenging even for GPT-3.5 Turbo. We show that, for both GPT-2 and Mistral 7B, $k$NN retrieval augmentation consistently improves performance in this setting. Finally, to make $k$NN retrieval more accessible, we propose using a multi-layer perceptron model that maps datastore keys to values as a drop-in replacement for traditional retrieval. This reduces storage costs by over 25x.
Read more4/3/2024
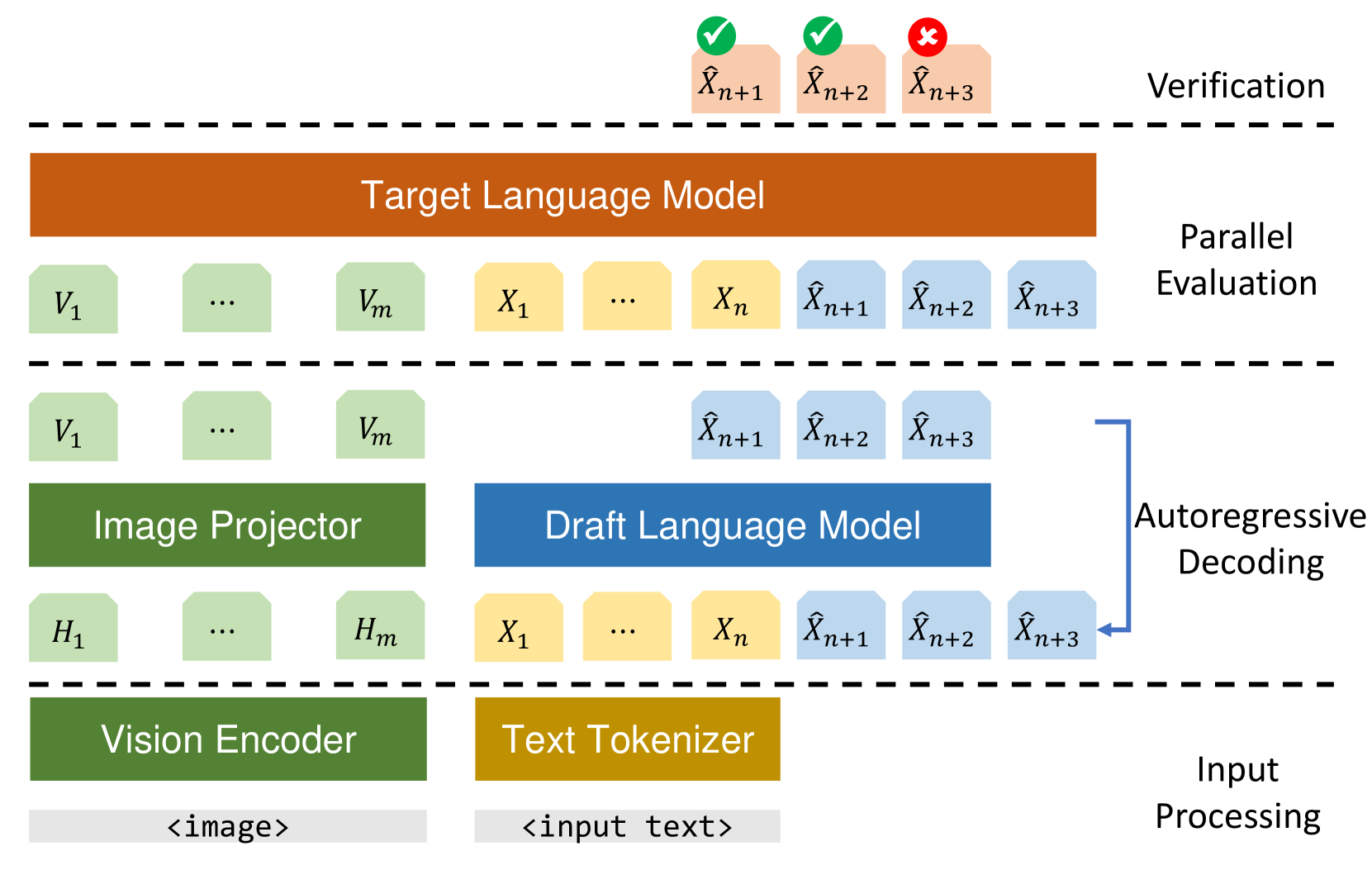
0
On Speculative Decoding for Multimodal Large Language Models
Mukul Gagrani, Raghavv Goel, Wonseok Jeon, Junyoung Park, Mingu Lee, Christopher Lott
Inference with Multimodal Large Language Models (MLLMs) is slow due to their large-language-model backbone which suffers from memory bandwidth bottleneck and generates tokens auto-regressively. In this paper, we explore the application of speculative decoding to enhance the inference efficiency of MLLMs, specifically the LLaVA 7B model. We show that a language-only model can serve as a good draft model for speculative decoding with LLaVA 7B, bypassing the need for image tokens and their associated processing components from the draft model. Our experiments across three different tasks show that speculative decoding can achieve a memory-bound speedup of up to 2.37$times$ using a 115M parameter language model that we trained from scratch. Additionally, we introduce a compact LLaVA draft model incorporating an image adapter, which shows marginal performance gains in image captioning while maintaining comparable results in other tasks.
Read more4/16/2024

0
Efficient k-Nearest-Neighbor Machine Translation with Dynamic Retrieval
Yan Gao, Zhiwei Cao, Zhongjian Miao, Baosong Yang, Shiyu Liu, Min Zhang, Jinsong Su
To achieve non-parametric NMT domain adaptation, $k$-Nearest-Neighbor Machine Translation ($k$NN-MT) constructs an external datastore to store domain-specific translation knowledge, which derives a $k$NN distribution to interpolate the prediction distribution of the NMT model via a linear interpolation coefficient $lambda$. Despite its success, $k$NN retrieval at each timestep leads to substantial time overhead. To address this issue, dominant studies resort to $k$NN-MT with adaptive retrieval ($k$NN-MT-AR), which dynamically estimates $lambda$ and skips $k$NN retrieval if $lambda$ is less than a fixed threshold. Unfortunately, $k$NN-MT-AR does not yield satisfactory results. In this paper, we first conduct a preliminary study to reveal two key limitations of $k$NN-MT-AR: 1) the optimization gap leads to inaccurate estimation of $lambda$ for determining $k$NN retrieval skipping, and 2) using a fixed threshold fails to accommodate the dynamic demands for $k$NN retrieval at different timesteps. To mitigate these limitations, we then propose $k$NN-MT with dynamic retrieval ($k$NN-MT-DR) that significantly extends vanilla $k$NN-MT in two aspects. Firstly, we equip $k$NN-MT with a MLP-based classifier for determining whether to skip $k$NN retrieval at each timestep. Particularly, we explore several carefully-designed scalar features to fully exert the potential of the classifier. Secondly, we propose a timestep-aware threshold adjustment method to dynamically generate the threshold, which further improves the efficiency of our model. Experimental results on the widely-used datasets demonstrate the effectiveness and generality of our model.footnote{Our code is available at url{https://github.com/DeepLearnXMU/knn-mt-dr}.
Read more6/11/2024