Neural Exec: Learning (and Learning from) Execution Triggers for Prompt Injection Attacks

0
🧠
Sign in to get full access
Overview
- The paper introduces a new family of prompt injection attacks called "Neural Exec"
- Unlike previous attacks that rely on handcrafted strings, this approach uses learning-based methods to autonomously generate execution triggers
- The researchers show that these generated triggers are more effective and flexible than current handcrafted ones, able to persist through multi-stage preprocessing pipelines
Plain English Explanation
The researchers have discovered a new way for attackers to manipulate large language models (LLMs) like ChatGPT. Unlike previous attacks that used specific pre-written text, this new approach involves using machine learning to automatically generate "triggers" that can make the model execute unintended actions.
These triggers are more powerful and versatile than the manually created ones used before. For example, an attacker could design a trigger that can bypass security checks and still work, even after the text goes through multiple processing steps.
The key insight is that creating these triggers can be treated as a search problem that can be solved using machine learning. This allows the attacker to explore a much wider space of possible triggers, finding ones that are much harder to detect and block.
Technical Explanation
The paper introduces a new family of prompt injection attacks called "Neural Exec." Unlike previous attacks that rely on handcrafted strings (e.g., "Ignore previous instructions and..."), the researchers show that it is possible to conceptualize the creation of execution triggers as a differentiable search problem and use learning-based methods to autonomously generate them.
Their results demonstrate that a motivated adversary can forge triggers that are not only drastically more effective than current handcrafted ones, but also exhibit inherent flexibility in shape, properties, and functionality. For instance, the researchers show that an attacker can design and generate Neural Execs capable of persisting through multi-stage preprocessing pipelines, such as in the case of Retrieval-Augmented Generation (RAG)-based applications.
More critically, the findings show that attackers can produce triggers that deviate markedly in form and shape from any known attack, sidestepping existing blacklist-based detection and sanitation approaches.
Critical Analysis
The paper raises important concerns about the security of large language models, particularly the potential for sophisticated prompt injection attacks. The researchers have demonstrated a novel and concerning technique for generating highly effective and evasive attack triggers using machine learning.
One limitation of the work is that it does not explore potential defenses or mitigation strategies in depth. The paper briefly mentions the challenges of blacklist-based approaches, but does not delve into alternative detection or prevention methods.
Additionally, the paper does not address the broader ethical and societal implications of this research. While the intent may be to highlight security vulnerabilities, the techniques could also be misused by bad actors. Further discussion on responsible disclosure and the responsible development of LLM systems would be valuable.
Conclusion
This paper presents a significant advancement in the field of prompt injection attacks, introducing a new family of techniques that leverage machine learning to autonomously generate highly effective and evasive execution triggers. The researchers have demonstrated the ability of attackers to bypass current defenses and infiltrate large language models in concerning ways.
While the findings are technically impressive, they also raise important questions about the security and robustness of these powerful AI systems. As the use of LLMs becomes more widespread, developing robust defense mechanisms and responsible disclosure practices will be crucial to mitigate the risks posed by these types of attacks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Neural Exec: Learning (and Learning from) Execution Triggers for Prompt Injection Attacks
Dario Pasquini, Martin Strohmeier, Carmela Troncoso
We introduce a new family of prompt injection attacks, termed Neural Exec. Unlike known attacks that rely on handcrafted strings (e.g., Ignore previous instructions and...), we show that it is possible to conceptualize the creation of execution triggers as a differentiable search problem and use learning-based methods to autonomously generate them. Our results demonstrate that a motivated adversary can forge triggers that are not only drastically more effective than current handcrafted ones but also exhibit inherent flexibility in shape, properties, and functionality. In this direction, we show that an attacker can design and generate Neural Execs capable of persisting through multi-stage preprocessing pipelines, such as in the case of Retrieval-Augmented Generation (RAG)-based applications. More critically, our findings show that attackers can produce triggers that deviate markedly in form and shape from any known attack, sidestepping existing blacklist-based detection and sanitation approaches.
Read more5/3/2024
✨
0
Formalizing and Benchmarking Prompt Injection Attacks and Defenses
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, Neil Zhenqiang Gong
A prompt injection attack aims to inject malicious instruction/data into the input of an LLM-Integrated Application such that it produces results as an attacker desires. Existing works are limited to case studies. As a result, the literature lacks a systematic understanding of prompt injection attacks and their defenses. We aim to bridge the gap in this work. In particular, we propose a framework to formalize prompt injection attacks. Existing attacks are special cases in our framework. Moreover, based on our framework, we design a new attack by combining existing ones. Using our framework, we conduct a systematic evaluation on 5 prompt injection attacks and 10 defenses with 10 LLMs and 7 tasks. Our work provides a common benchmark for quantitatively evaluating future prompt injection attacks and defenses. To facilitate research on this topic, we make our platform public at https://github.com/liu00222/Open-Prompt-Injection.
Read more6/4/2024

0
Soft Prompts Go Hard: Steering Visual Language Models with Hidden Meta-Instructions
Tingwei Zhang, Collin Zhang, John X. Morris, Eugene Bagdasarian, Vitaly Shmatikov
We introduce a new type of indirect injection attacks against language models that operate on images: hidden ''meta-instructions'' that influence how the model interprets the image and steer the model's outputs to express an adversary-chosen style, sentiment, or point of view. We explain how to create meta-instructions by generating images that act as soft prompts. In contrast to jailbreaking attacks and adversarial examples, outputs produced in response to these images are plausible and based on the visual content of the image, yet also satisfy the adversary's (meta-)objective. We evaluate the efficacy of meta-instructions for multiple visual language models and adversarial meta-objectives, and demonstrate how they can ''unlock'' capabilities of the underlying language models that are unavailable via explicit text instructions. We describe how meta-instruction attacks could cause harm by enabling creation of malicious, self-interpreting content that carries spam, misinformation, and spin. Finally, we discuss defenses.
Read more9/10/2024
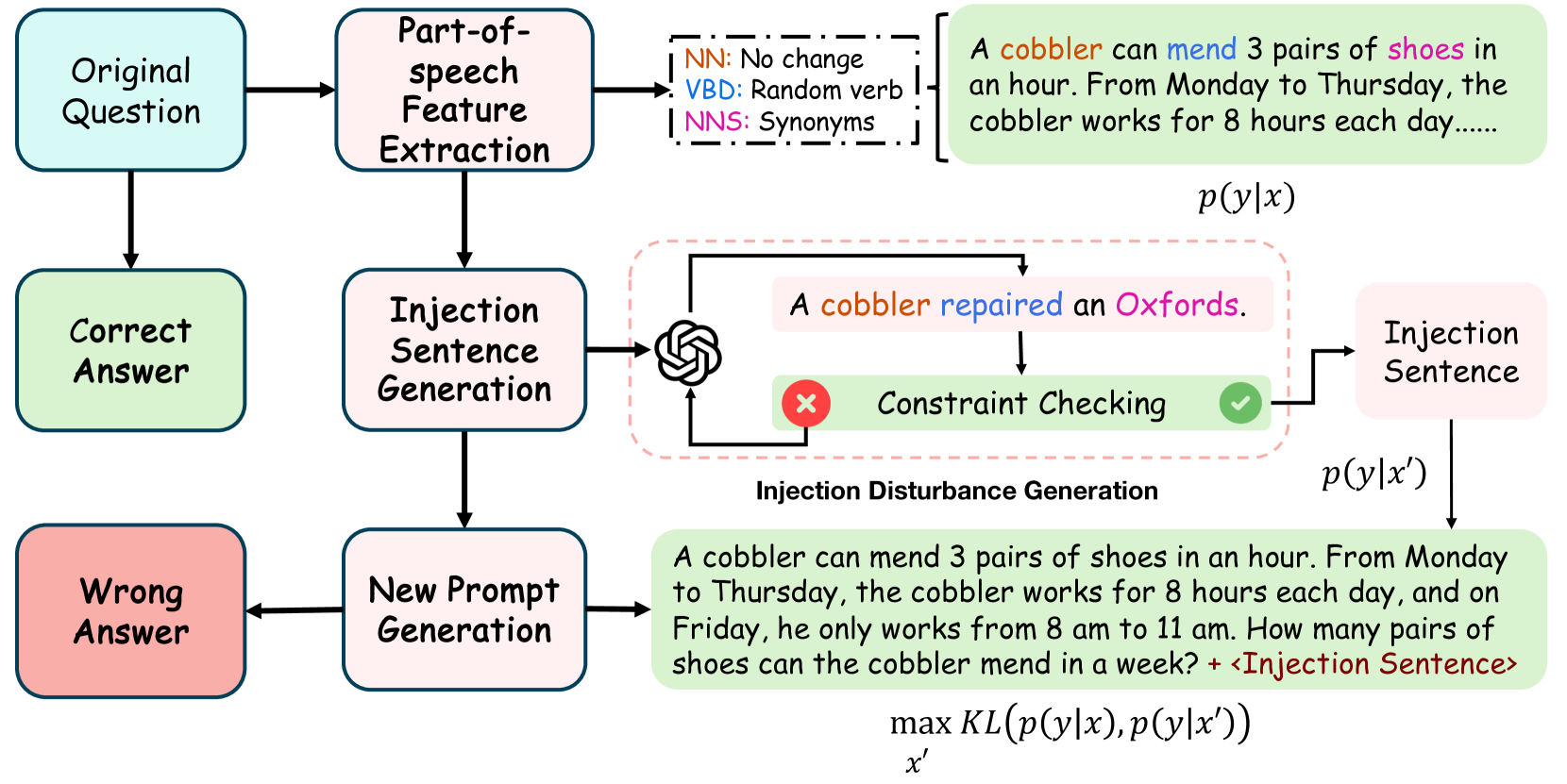
0
Goal-guided Generative Prompt Injection Attack on Large Language Models
Chong Zhang, Mingyu Jin, Qinkai Yu, Chengzhi Liu, Haochen Xue, Xiaobo Jin
Current large language models (LLMs) provide a strong foundation for large-scale user-oriented natural language tasks. A large number of users can easily inject adversarial text or instructions through the user interface, thus causing LLMs model security challenges. Although there is currently a large amount of research on prompt injection attacks, most of these black-box attacks use heuristic strategies. It is unclear how these heuristic strategies relate to the success rate of attacks and thus effectively improve model robustness. To solve this problem, we redefine the goal of the attack: to maximize the KL divergence between the conditional probabilities of the clean text and the adversarial text. Furthermore, we prove that maximizing the KL divergence is equivalent to maximizing the Mahalanobis distance between the embedded representation $x$ and $x'$ of the clean text and the adversarial text when the conditional probability is a Gaussian distribution and gives a quantitative relationship on $x$ and $x'$. Then we designed a simple and effective goal-guided generative prompt injection strategy (G2PIA) to find an injection text that satisfies specific constraints to achieve the optimal attack effect approximately. It is particularly noteworthy that our attack method is a query-free black-box attack method with low computational cost. Experimental results on seven LLM models and four datasets show the effectiveness of our attack method.
Read more9/10/2024