Neural Scaling Laws From Large-N Field Theory: Solvable Model Beyond the Ridgeless Limit
2405.19398
0
0
Abstract
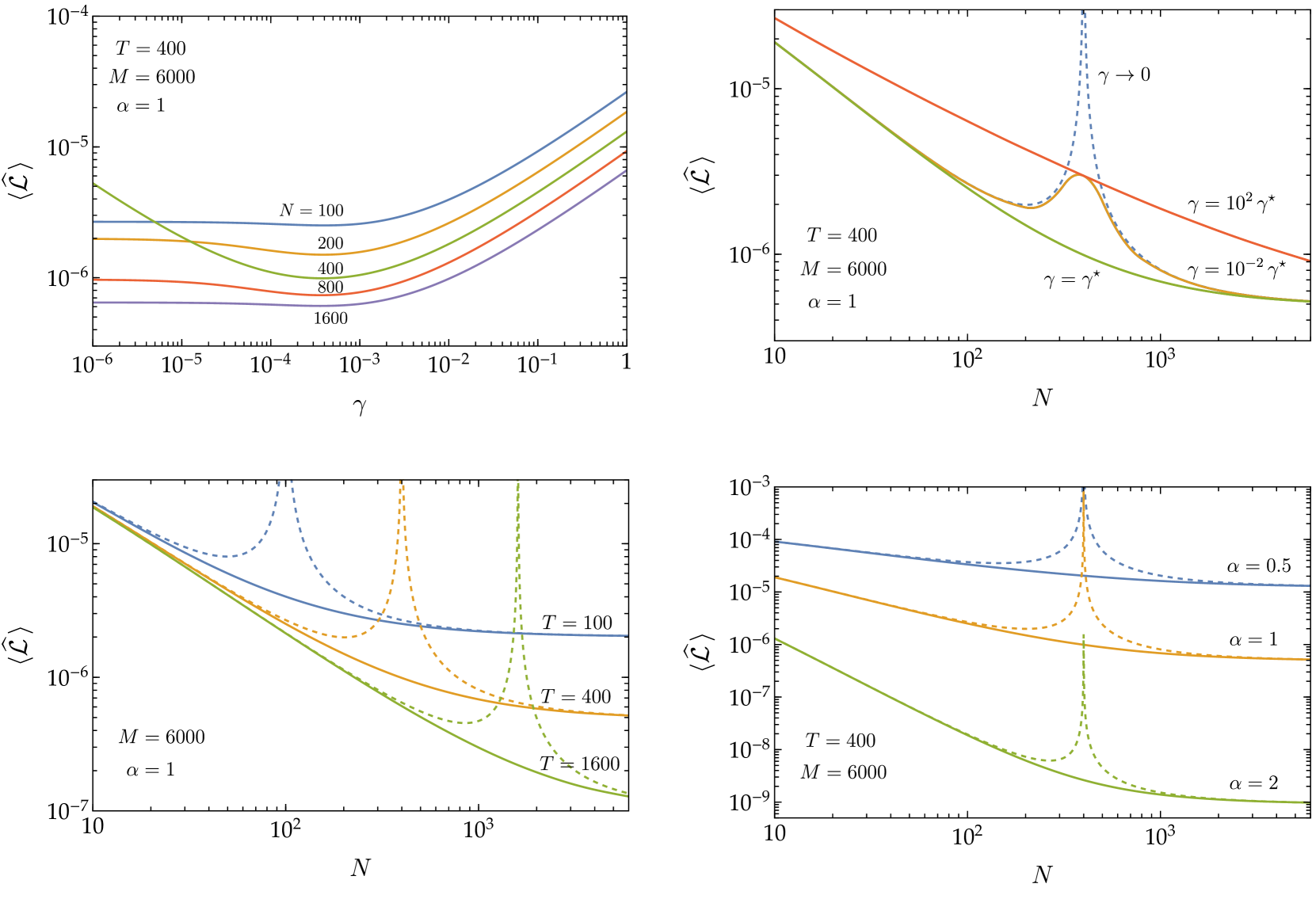
Many machine learning models based on neural networks exhibit scaling laws: their performance scales as power laws with respect to the sizes of the model and training data set. We use large-N field theory methods to solve a model recently proposed by Maloney, Roberts and Sully which provides a simplified setting to study neural scaling laws. Our solution extends the result in this latter paper to general nonzero values of the ridge parameter, which are essential to regularize the behavior of the model. In addition to obtaining new and more precise scaling laws, we also uncover a duality transformation at the diagrams level which explains the symmetry between model and training data set sizes. The same duality underlies recent efforts to design neural networks to simulate quantum field theories.
Create account to get full access
Overview
- This paper presents a solvable model for studying neural scaling laws, which describe the empirical relationship between the performance and size of neural networks.
- The model goes beyond the "ridgeless limit" assumption, which simplifies the analysis but may not capture the full complexity of real-world neural networks.
- The authors derive analytical expressions for various scaling laws and show that their model can exhibit a rich phase diagram with different scaling regimes.
Plain English Explanation
The paper examines the scaling behavior of large neural networks, which refers to how the performance of a neural network changes as it gets larger in size. Explaining Neural Scaling Laws and Exactly Solvable Model for the Emergence of Scaling Laws have explored this topic before, but this paper aims to go beyond the simplified "ridgeless limit" assumption used in those studies.
The researchers developed a mathematical model that can capture more of the complexity of real-world neural networks. Their model shows that neural networks can exhibit a rich variety of scaling behaviors, with different regimes or phases depending on the network's size and other parameters. Neural Scaling Laws from Large-N Field Theory: Solvable Model Beyond the Ridgeless Limit provides a way to analytically derive these scaling laws and understand the underlying mechanisms driving them.
This work contributes to our fundamental understanding of how neural networks scale, which is important for the field of Embodied AI and the development of Optimal Neural Scaling Laws. By going beyond simplifying assumptions, the authors offer a more realistic model that can shed light on the complex scaling behavior of large neural networks.
Technical Explanation
The paper develops a solvable model for studying neural scaling laws that goes beyond the "ridgeless limit" assumption used in previous work. Exactly Solvable Model for the Emergence of Scaling Laws and Explaining Neural Scaling Laws had used the ridgeless limit, which simplifies the analysis but may not capture the full complexity of real-world neural networks.
The authors derive analytical expressions for various scaling laws, including the scaling of test and training loss, gradient norms, and the condition number of the Hessian matrix. Their model exhibits a rich phase diagram with different scaling regimes depending on the network size and other parameters.
For example, the model can display power-law scaling, logarithmic scaling, and even non-monotonic scaling behavior. The authors provide a detailed analysis of these different phases and the underlying mechanisms driving the scaling laws.
By going beyond the ridgeless limit, this work offers a more realistic and comprehensive picture of how neural networks scale. The insights from this solvable model can inform the development of Optimal Neural Scaling Laws and contribute to our fundamental understanding of Neural Scaling Laws from Large-N Field Theory and their implications for Embodied AI.
Critical Analysis
The paper presents a comprehensive and technically rigorous model for studying neural scaling laws, going beyond the simplifications of previous work. By relaxing the ridgeless limit assumption, the authors are able to capture a richer set of scaling behaviors, which is a valuable contribution to the field.
However, the model still relies on several assumptions, such as the specific form of the activation function and the statistical properties of the input data. While these assumptions are common in theoretical analyses, they may not fully reflect the complexity of real-world neural networks.
Additionally, the authors focus on a specific type of neural network architecture and do not explore the implications of their model for other architectures or tasks. It would be interesting to see how the insights from this work could be generalized to a broader range of neural network models and applications.
Finally, while the analytical expressions derived in the paper provide valuable theoretical insights, it is unclear how well the model's predictions would match empirical observations of large-scale neural networks. Validating the model's predictions against experimental data would be an important next step to assess its practical relevance.
Overall, this paper represents a significant advancement in our understanding of neural scaling laws and offers a solid foundation for future research in this area. By continuing to refine and validate these theoretical models, we can hope to develop a more comprehensive and predictive theory of neural network scaling that can inform the design of Optimal Neural Scaling Laws and Embodied AI systems.
Conclusion
This paper presents a solvable model for studying neural scaling laws that goes beyond the simplifying "ridgeless limit" assumption used in previous work. The authors derive analytical expressions for various scaling laws and show that their model can exhibit a rich phase diagram with different scaling regimes depending on the network size and other parameters.
By relaxing the ridgeless limit, the model offers a more realistic and comprehensive picture of how neural networks scale. The insights from this work can contribute to our fundamental understanding of Neural Scaling Laws from Large-N Field Theory and inform the development of Optimal Neural Scaling Laws and Embodied AI systems.
While the model still relies on certain assumptions, this paper represents a significant step forward in the theoretical study of neural network scaling and lays the groundwork for further refinement and validation against empirical data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Dynamical Model of Neural Scaling Laws
Blake Bordelon, Alexander Atanasov, Cengiz Pehlevan
0
0
On a variety of tasks, the performance of neural networks predictably improves with training time, dataset size and model size across many orders of magnitude. This phenomenon is known as a neural scaling law. Of fundamental importance is the compute-optimal scaling law, which reports the performance as a function of units of compute when choosing model sizes optimally. We analyze a random feature model trained with gradient descent as a solvable model of network training and generalization. This reproduces many observations about neural scaling laws. First, our model makes a prediction about why the scaling of performance with training time and with model size have different power law exponents. Consequently, the theory predicts an asymmetric compute-optimal scaling rule where the number of training steps are increased faster than model parameters, consistent with recent empirical observations. Second, it has been observed that early in training, networks converge to their infinite-width dynamics at a rate $1/textit{width}$ but at late time exhibit a rate $textit{width}^{-c}$, where $c$ depends on the structure of the architecture and task. We show that our model exhibits this behavior. Lastly, our theory shows how the gap between training and test loss can gradually build up over time due to repeated reuse of data.
6/26/2024
🧠
Explaining Neural Scaling Laws
Yasaman Bahri, Ethan Dyer, Jared Kaplan, Jaehoon Lee, Utkarsh Sharma
0
0
The population loss of trained deep neural networks often follows precise power-law scaling relations with either the size of the training dataset or the number of parameters in the network. We propose a theory that explains the origins of and connects these scaling laws. We identify variance-limited and resolution-limited scaling behavior for both dataset and model size, for a total of four scaling regimes. The variance-limited scaling follows simply from the existence of a well-behaved infinite data or infinite width limit, while the resolution-limited regime can be explained by positing that models are effectively resolving a smooth data manifold. In the large width limit, this can be equivalently obtained from the spectrum of certain kernels, and we present evidence that large width and large dataset resolution-limited scaling exponents are related by a duality. We exhibit all four scaling regimes in the controlled setting of large random feature and pretrained models and test the predictions empirically on a range of standard architectures and datasets. We also observe several empirical relationships between datasets and scaling exponents under modifications of task and architecture aspect ratio. Our work provides a taxonomy for classifying different scaling regimes, underscores that there can be different mechanisms driving improvements in loss, and lends insight into the microscopic origins of and relationships between scaling exponents.
4/30/2024
Neural Scaling Laws on Graphs
Jingzhe Liu, Haitao Mao, Zhikai Chen, Tong Zhao, Neil Shah, Jiliang Tang
0
0
Deep graph models (e.g., graph neural networks and graph transformers) have become important techniques for leveraging knowledge across various types of graphs. Yet, the scaling properties of deep graph models have not been systematically investigated, casting doubt on the feasibility of achieving large graph models through enlarging the model and dataset sizes. In this work, we delve into neural scaling laws on graphs from both model and data perspectives. We first verify the validity of such laws on graphs, establishing formulations to describe the scaling behaviors. For model scaling, we investigate the phenomenon of scaling law collapse and identify overfitting as the potential reason. Moreover, we reveal that the model depth of deep graph models can impact the model scaling behaviors, which differ from observations in other domains such as CV and NLP. For data scaling, we suggest that the number of graphs can not effectively metric the graph data volume in scaling law since the sizes of different graphs are highly irregular. Instead, we reform the data scaling law with the number of edges as the metric to address the irregular graph sizes. We further demonstrate the reformed law offers a unified view of the data scaling behaviors for various fundamental graph tasks including node classification, link prediction, and graph classification. This work provides valuable insights into neural scaling laws on graphs, which can serve as an essential step toward large graph models.
6/11/2024
📈
An exactly solvable model for emergence and scaling laws
Yoonsoo Nam, Nayara Fonseca, Seok Hyeong Lee, Ard Louis
0
0
Deep learning models can exhibit what appears to be a sudden ability to solve a new problem as training time ($T$), training data ($D$), or model size ($N$) increases, a phenomenon known as emergence. In this paper, we present a framework where each new ability (a skill) is represented as a basis function. We solve a simple multi-linear model in this skill-basis, finding analytic expressions for the emergence of new skills, as well as for scaling laws of the loss with training time, data size, model size, and optimal compute ($C$). We compare our detailed calculations to direct simulations of a two-layer neural network trained on multitask sparse parity, where the tasks in the dataset are distributed according to a power-law. Our simple model captures, using a single fit parameter, the sigmoidal emergence of multiple new skills as training time, data size or model size increases in the neural network.
4/29/2024