Neural Scaling Laws for Embodied AI

0
🧠
Sign in to get full access
Overview
- This paper explores the scaling laws that govern the performance of machine learning models used in robotics and embodied AI.
- The researchers conducted a meta-analysis of 198 research papers to understand how factors like compute, model size, and training data quantity impact model performance across various robotic tasks.
- The study found that scaling laws apply to both Robot Foundation Models (RFMs) and Large Language Models (LLMs) used in robotics, with performance consistently improving as resources increase.
- The paper highlights the importance of large and diverse datasets, the lack of standardized benchmarks in embodied AI, and the emergence of new capabilities as models scale.
Plain English Explanation
The researchers in this paper looked at how the size and power of machine learning models used in robotics and embodied AI affects their performance. They analyzed data from 198 previous studies to understand how factors like the computational resources, the size of the models, and the amount of training data impact the performance of these models on different robotic tasks.
The key finding is that the same scaling laws that have driven progress in language modeling and computer vision also apply to robotics and embodied AI. As the models get larger and have access to more computational power and training data, their performance consistently improves, following a predictable pattern.
The coefficients of these scaling laws for robotics models are very similar to what has been observed in computer vision, but differ from the scaling laws for language models. This suggests that the fundamental dynamics of how these models learn and improve are somewhat different between robotics and language tasks.
The researchers also note that the scaling laws vary depending on the complexity of the task. Models tend to improve more efficiently on familiar tasks compared to unfamiliar ones, emphasizing the need for large and diverse datasets to train capable robotic systems.
Furthermore, the lack of standardized benchmarks in embodied AI makes it difficult to compare progress across different studies. And as the models get larger, the researchers observe diminishing returns, meaning significant resources are required to achieve high performance. This poses challenges due to the data and computational constraints that many robotics projects face.
Overall, this study provides important insights into the underlying principles governing the development of machine learning for robotics and embodied AI, and highlights areas where further research and investment are needed to unlock the full potential of these technologies.
Technical Explanation
The researchers conducted a comprehensive meta-analysis of 198 research papers to quantify the scaling laws that govern the performance of Robot Foundation Models (RFMs) and the use of Large Language Models (LLMs) in robotics tasks.
They analyzed how key factors like compute, model size, and training data quantity impact model performance across a variety of robotic applications, including navigation, manipulation, and perception. The findings confirm that scaling laws apply to both RFMs and LLMs in robotics, with performance consistently improving as resources increase.
Interestingly, the power law coefficients for RFMs closely match those observed in computer vision, outperforming the coefficients for LLMs in the language domain. This suggests that the fundamental dynamics of how these models learn and improve are somewhat different between robotics and language tasks.
The researchers also note that these coefficients vary with task complexity, with familiar tasks scaling more efficiently than unfamiliar ones. This emphasizes the need for large and diverse datasets to train capable robotic systems, as highlighted in previous research.
Furthermore, the study draws attention to the absence of standardized benchmarks in embodied AI, making it challenging to compare progress across different studies. Most of the research indicates diminishing returns, suggesting that significant resources are necessary to achieve high performance, which poses challenges due to data and computational limitations.
Finally, the researchers observe the emergence of new capabilities as models scale, particularly related to data and model size. This underscores the importance of continuing to explore and understand the scaling laws that govern the development of machine learning for robotics and embodied AI.
Critical Analysis
The study provides a comprehensive and rigorous analysis of the scaling laws governing the performance of machine learning models in robotics and embodied AI. The researchers' meta-analysis of 198 research papers offers a valuable dataset and a holistic view of the field.
One key limitation of the study is the lack of standardized benchmarks in embodied AI, which the researchers acknowledge. This makes it difficult to directly compare the performance of different models and approaches, and could introduce some biases in the meta-analysis.
Additionally, the researchers note that the scaling laws vary depending on the complexity of the task, with familiar tasks scaling more efficiently than unfamiliar ones. This highlights the importance of diverse and representative training datasets, as well as the need for further research to understand the factors that contribute to task complexity in the context of robotics.
While the study provides important insights into the underlying principles governing the development of machine learning for robotics and embodied AI, it would be valuable to see further research exploring the practical implications of these findings. For example, how can these scaling laws be leveraged to guide the development of more efficient and capable robotic systems? What are the key bottlenecks and challenges that need to be addressed to unlock the full potential of these technologies?
Overall, this paper offers a significant contribution to the understanding of scaling laws in robotics and embodied AI, and serves as a valuable foundation for future research in this rapidly evolving field.
Conclusion
This study provides the first comprehensive analysis of the scaling laws that govern the performance of machine learning models in robotics and embodied AI. The researchers' meta-analysis of 198 research papers confirms that the same scaling laws that have driven remarkable progress in language modeling and computer vision also apply to the field of robotics.
The findings suggest that as models get larger and have access to more computational power and training data, their performance consistently improves, following a predictable pattern. Interestingly, the scaling law coefficients for robotic models closely match those observed in computer vision, but differ from the language domain, indicating fundamental differences in how these models learn and improve.
The study also highlights the importance of large and diverse datasets, the lack of standardized benchmarks in embodied AI, and the emergence of new capabilities as models scale. As the field of robotics continues to evolve, understanding these underlying principles will be crucial for guiding the development of more efficient and capable systems.
Overall, this research offers valuable insights that can inform future work in machine learning for robotics and embodied AI, helping to unlock the full potential of these transformative technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
Neural Scaling Laws for Embodied AI
Sebastian Sartor, Neil Thompson
Scaling laws have driven remarkable progress across machine learning domains like language modeling and computer vision. However, the exploration of scaling laws in embodied AI and robotics has been limited, despite the rapidly increasing usage of machine learning in this field. This paper presents the first study to quantify scaling laws for Robot Foundation Models (RFMs) and the use of LLMs in robotics tasks. Through a meta-analysis spanning 198 research papers, we analyze how key factors like compute, model size, and training data quantity impact model performance across various robotic tasks. Our findings confirm that scaling laws apply to both RFMs and LLMs in robotics, with performance consistently improving as resources increase. The power law coefficients for RFMs closely match those of LLMs in robotics, resembling those found in computer vision and outperforming those for LLMs in the language domain. We also note that these coefficients vary with task complexity, with familiar tasks scaling more efficiently than unfamiliar ones, emphasizing the need for large and diverse datasets. Furthermore, we highlight the absence of standardized benchmarks in embodied AI. Most studies indicate diminishing returns, suggesting that significant resources are necessary to achieve high performance, posing challenges due to data and computational limitations. Finally, as models scale, we observe the emergence of new capabilities, particularly related to data and model size.
Read more5/24/2024
🔮
0
Scaling Laws Do Not Scale
Fernando Diaz, Michael Madaio
Recent work has advocated for training AI models on ever-larger datasets, arguing that as the size of a dataset increases, the performance of a model trained on that dataset will correspondingly increase (referred to as scaling laws). In this paper, we draw on literature from the social sciences and machine learning to critically interrogate these claims. We argue that this scaling law relationship depends on metrics used to measure performance that may not correspond with how different groups of people perceive the quality of models' output. As the size of datasets used to train large AI models grows and AI systems impact ever larger groups of people, the number of distinct communities represented in training or evaluation datasets grows. It is thus even more likely that communities represented in datasets may have values or preferences not reflected in (or at odds with) the metrics used to evaluate model performance in scaling laws. Different communities may also have values in tension with each other, leading to difficult, potentially irreconcilable choices about metrics used for model evaluations -- threatening the validity of claims that model performance is improving at scale. We end the paper with implications for AI development: that the motivation for scraping ever-larger datasets may be based on fundamentally flawed assumptions about model performance. That is, models may not, in fact, continue to improve as the datasets get larger -- at least not for all people or communities impacted by those models. We suggest opportunities for the field to rethink norms and values in AI development, resisting claims for universality of large models, fostering more local, small-scale designs, and other ways to resist the impetus towards scale in AI.
Read more7/30/2024
0
Neural Scaling Laws on Graphs
Jingzhe Liu, Haitao Mao, Zhikai Chen, Tong Zhao, Neil Shah, Jiliang Tang
Deep graph models (e.g., graph neural networks and graph transformers) have become important techniques for leveraging knowledge across various types of graphs. Yet, the scaling properties of deep graph models have not been systematically investigated, casting doubt on the feasibility of achieving large graph models through enlarging the model and dataset sizes. In this work, we delve into neural scaling laws on graphs from both model and data perspectives. We first verify the validity of such laws on graphs, establishing formulations to describe the scaling behaviors. For model scaling, we investigate the phenomenon of scaling law collapse and identify overfitting as the potential reason. Moreover, we reveal that the model depth of deep graph models can impact the model scaling behaviors, which differ from observations in other domains such as CV and NLP. For data scaling, we suggest that the number of graphs can not effectively metric the graph data volume in scaling law since the sizes of different graphs are highly irregular. Instead, we reform the data scaling law with the number of edges as the metric to address the irregular graph sizes. We further demonstrate the reformed law offers a unified view of the data scaling behaviors for various fundamental graph tasks including node classification, link prediction, and graph classification. This work provides valuable insights into neural scaling laws on graphs, which can serve as an essential step toward large graph models.
Read more6/11/2024
1
Observational Scaling Laws and the Predictability of Language Model Performance
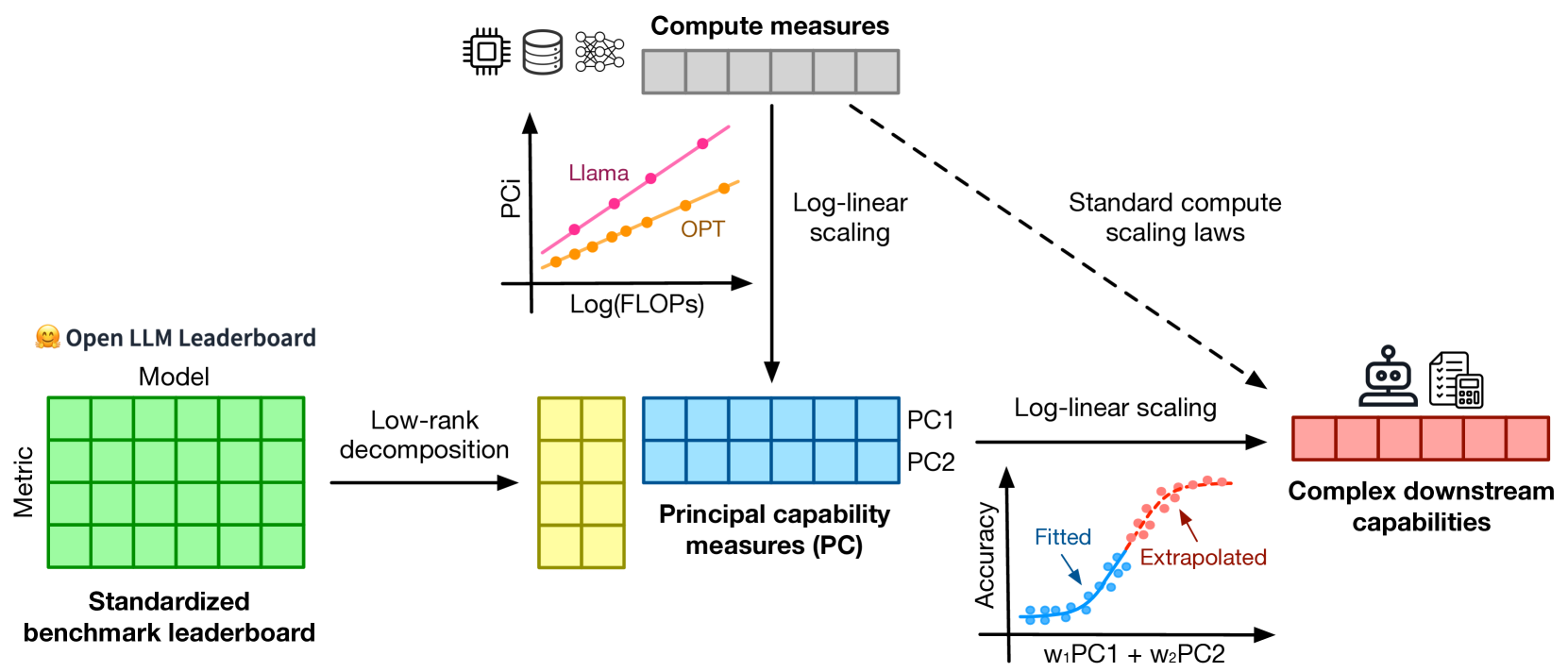
Yangjun Ruan, Chris J. Maddison, Tatsunori Hashimoto
Understanding how language model performance varies with scale is critical to benchmark and algorithm development. Scaling laws are one approach to building this understanding, but the requirement of training models across many different scales has limited their use. We propose an alternative, observational approach that bypasses model training and instead builds scaling laws from ~80 publically available models. Building a single scaling law from multiple model families is challenging due to large variations in their training compute efficiencies and capabilities. However, we show that these variations are consistent with a simple, generalized scaling law where language model performance is a function of a low-dimensional capability space, and model families only vary in their efficiency in converting training compute to capabilities. Using this approach, we show the surprising predictability of complex scaling phenomena: we show that several emergent phenomena follow a smooth, sigmoidal behavior and are predictable from small models; we show that the agent performance of models such as GPT-4 can be precisely predicted from simpler non-agentic benchmarks; and we show how to predict the impact of post-training interventions like Chain-of-Thought and Self-Consistency as language model capabilities continue to improve.
Read more5/20/2024