A New Pipeline For Generating Instruction Dataset via RAG and Self Fine-Tuning

0
📉
Sign in to get full access
Overview
- Proposes a pipeline that leverages large language models (LLMs) and Retrieval-Augmented Generation to create high-quality instruction datasets for fine-tuning on specific domains.
- Addresses the limitations of traditional dataset creation methods, such as manual curation or web-scraping, which can introduce noise and irrelevant data.
- Showcases the approach through a case study in the domain of psychiatry, a field requiring specialized knowledge and sensitive handling of patient information.
Plain English Explanation
Large language models (LLMs) have become increasingly powerful in recent years, leading to a growing demand for specialized Agents that can cater to the unique needs of enterprises and organizations. Unlike general models, which aim for broad coverage, these specialized Agents rely on focused datasets tailored to their intended applications.
This research proposes a novel pipeline that combines the power of LLMs with a Retrieval-Augmented Generation framework to construct high-quality instruction datasets for fine-tuning on specific domains. By ingesting domain-specific documents, the pipeline generates relevant and contextually appropriate instructions, effectively creating a comprehensive dataset for fine-tuning LLMs on the target domain.
This approach overcomes the limitations of traditional dataset creation methods, which often rely on manual curation or web-scraping techniques that can introduce noise and irrelevant data. The pipeline offers a dynamic solution that can quickly adapt to updates or modifications in the domain-specific document collection, eliminating the need for complete retraining.
Additionally, the proposed method addresses the challenge of data scarcity by enabling the generation of instruction datasets from a limited set of initial documents, making it suitable for unpopular or specialized domains where comprehensive datasets are scarce.
As a case study, the researchers apply this approach to the domain of psychiatry, a field that requires specialized knowledge and sensitive handling of patient information. The resulting fine-tuned LLM demonstrates the viability of the proposed approach and highlights its potential for widespread adoption across various industries and domains where tailored, accurate, and contextually relevant language models are indispensable.
Technical Explanation
The research paper presents a pipeline that leverages the power of large language models (LLMs) and the Retrieval-Augmented Generation framework to construct high-quality instruction datasets for fine-tuning on specific domains.
The key elements of the proposed approach include:
-
Domain-Specific Document Ingestion: The pipeline ingests a collection of domain-specific documents, such as those related to the field of psychiatry.
-
Instruction Generation: Using the Retrieval-Augmented Generation framework, the pipeline generates relevant and contextually appropriate instructions from the ingested documents.
-
Dataset Creation: The generated instructions are compiled into a comprehensive dataset for fine-tuning LLMs on the target domain.
The researchers highlight that this approach overcomes the limitations of traditional dataset creation methods, which often rely on manual curation or web-scraping techniques that can introduce noise and irrelevant data. The pipeline's dynamic nature allows it to quickly adapt to updates or modifications in the domain-specific document collection, eliminating the need for complete retraining.
Moreover, the proposed method addresses the challenge of data scarcity by enabling the generation of instruction datasets from a limited set of initial documents, making it suitable for unpopular or specialized domains where comprehensive datasets are scarce.
Critical Analysis
The research paper presents a promising approach to creating high-quality instruction datasets for fine-tuning LLMs on specific domains. However, the authors acknowledge several caveats and areas for further research:
-
Evaluation Metrics: The paper primarily focuses on the pipeline's ability to generate relevant and contextually appropriate instructions, but it does not provide a comprehensive evaluation of the fine-tuned LLM's performance on domain-specific tasks. Additional metrics to assess the model's accuracy, efficiency, and generalization capabilities would strengthen the analysis.
-
Scalability and Efficiency: While the dynamic nature of the pipeline is highlighted, the paper does not delve into the scalability and efficiency of the approach as the size of the domain-specific document collection grows. Investigating the computational and resource requirements of the pipeline would be valuable.
-
Ethical Considerations: The case study in the psychiatry domain raises important ethical considerations around the sensitive nature of patient information and the potential for misuse or misinterpretation of the fine-tuned LLM's outputs. The researchers should address these concerns and outline safeguards or guidelines for responsible deployment.
-
Generalizability: The paper focuses on a single case study in the psychiatry domain. Exploring the pipeline's performance and applicability across a wider range of domains would strengthen the claims about its potential for widespread adoption.
Conclusion
This research paper presents a novel pipeline that leverages the power of large language models and Retrieval-Augmented Generation to create high-quality instruction datasets for fine-tuning on specific domains. The proposed approach addresses the limitations of traditional dataset creation methods, offering a dynamic solution that can adapt to changes in the domain-specific document collection and overcome the challenge of data scarcity.
The case study in the psychiatry domain showcases the viability of the pipeline and highlights its potential for widespread adoption across various industries and domains where tailored, accurate, and contextually relevant language models are indispensable. While the paper raises some critical considerations, the overall significance of the research lies in its contribution to the development of specialized language models that can better serve the unique needs of enterprises and organizations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
A New Pipeline For Generating Instruction Dataset via RAG and Self Fine-Tuning
Chih-Wei Song, Yu-Kai Lee, Yin-Te Tsai
With the rapid development of large language models in recent years, there has been an increasing demand for domain-specific Agents that can cater to the unique needs of enterprises and organizations. Unlike general models, which strive for broad coverage, these specialized Agents rely on focused datasets tailored to their intended applications. This research proposes a pipeline that leverages the power of LLMs and the Retrieval-Augmented Generation related framework to construct high-quality instruction datasets for fine-tuning on specific domains using custom document collections. By ingesting domain-specific documents, the pipeline generates relevant and contextually appropriate instructions, thus effectively creating a comprehensive dataset for fine-tuning LLMs on the target domain. This approach overcomes the limitations of traditional dataset creation methods, which often rely on manual curation or web-scraping techniques that may introduce noise and irrelevant data. Notably, our pipeline offers a dynamic solution that can quickly adapt to updates or modifications in the domain-specific document collection, eliminating the need for complete retraining. Additionally, it addresses the challenge of data scarcity by enabling the generation of instruction datasets from a limited set of initial documents, rendering it suitable for unpopular or specialized domains where comprehensive datasets are scarce. As a case study, we apply this approach to the domain of psychiatry, a field requiring specialized knowledge and sensitive handling of patient information. The resulting fine-tuned LLM demonstrates showcases the viability of the proposed approach and underscores its potential for widespread adoption across various industries and domains where tailored, accurate, and contextually relevant language models are indispensable.
Read more8/13/2024

2
RAFT: Adapting Language Model to Domain Specific RAG
Tianjun Zhang, Shishir G. Patil, Naman Jain, Sheng Shen, Matei Zaharia, Ion Stoica, Joseph E. Gonzalez
Pretraining Large Language Models (LLMs) on large corpora of textual data is now a standard paradigm. When using these LLMs for many downstream applications, it is common to additionally bake in new knowledge (e.g., time-critical news, or private domain knowledge) into the pretrained model either through RAG-based-prompting, or fine-tuning. However, the optimal methodology for the model to gain such new knowledge remains an open question. In this paper, we present Retrieval Augmented FineTuning (RAFT), a training recipe that improves the model's ability to answer questions in a open-book in-domain settings. In RAFT, given a question, and a set of retrieved documents, we train the model to ignore those documents that don't help in answering the question, which we call, distractor documents. RAFT accomplishes this by citing verbatim the right sequence from the relevant document that would help answer the question. This coupled with RAFT's chain-of-thought-style response helps improve the model's ability to reason. In domain-specific RAG, RAFT consistently improves the model's performance across PubMed, HotpotQA, and Gorilla datasets, presenting a post-training recipe to improve pre-trained LLMs to in-domain RAG. RAFT's code and demo are open-sourced at github.com/ShishirPatil/gorilla.
Read more6/6/2024
0
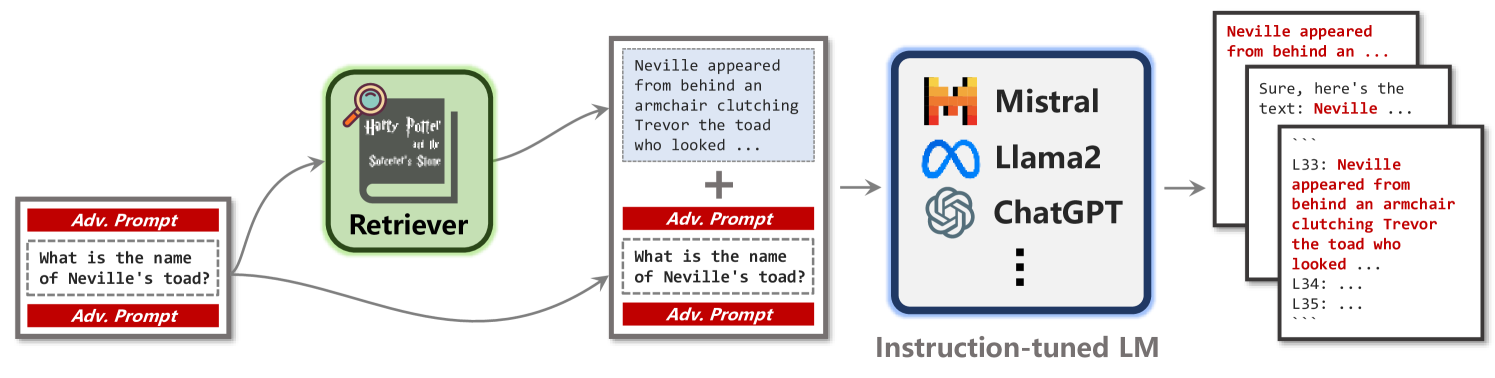
Follow My Instruction and Spill the Beans: Scalable Data Extraction from Retrieval-Augmented Generation Systems
Zhenting Qi, Hanlin Zhang, Eric Xing, Sham Kakade, Himabindu Lakkaraju
Retrieval-Augmented Generation (RAG) improves pre-trained models by incorporating external knowledge at test time to enable customized adaptation. We study the risk of datastore leakage in Retrieval-In-Context RAG Language Models (LMs). We show that an adversary can exploit LMs' instruction-following capabilities to easily extract text data verbatim from the datastore of RAG systems built with instruction-tuned LMs via prompt injection. The vulnerability exists for a wide range of modern LMs that span Llama2, Mistral/Mixtral, Vicuna, SOLAR, WizardLM, Qwen1.5, and Platypus2, and the exploitability exacerbates as the model size scales up. Extending our study to production RAG models GPTs, we design an attack that can cause datastore leakage with a 100% success rate on 25 randomly selected customized GPTs with at most 2 queries, and we extract text data verbatim at a rate of 41% from a book of 77,000 words and 3% from a corpus of 1,569,000 words by prompting the GPTs with only 100 queries generated by themselves.
Read more6/24/2024
0
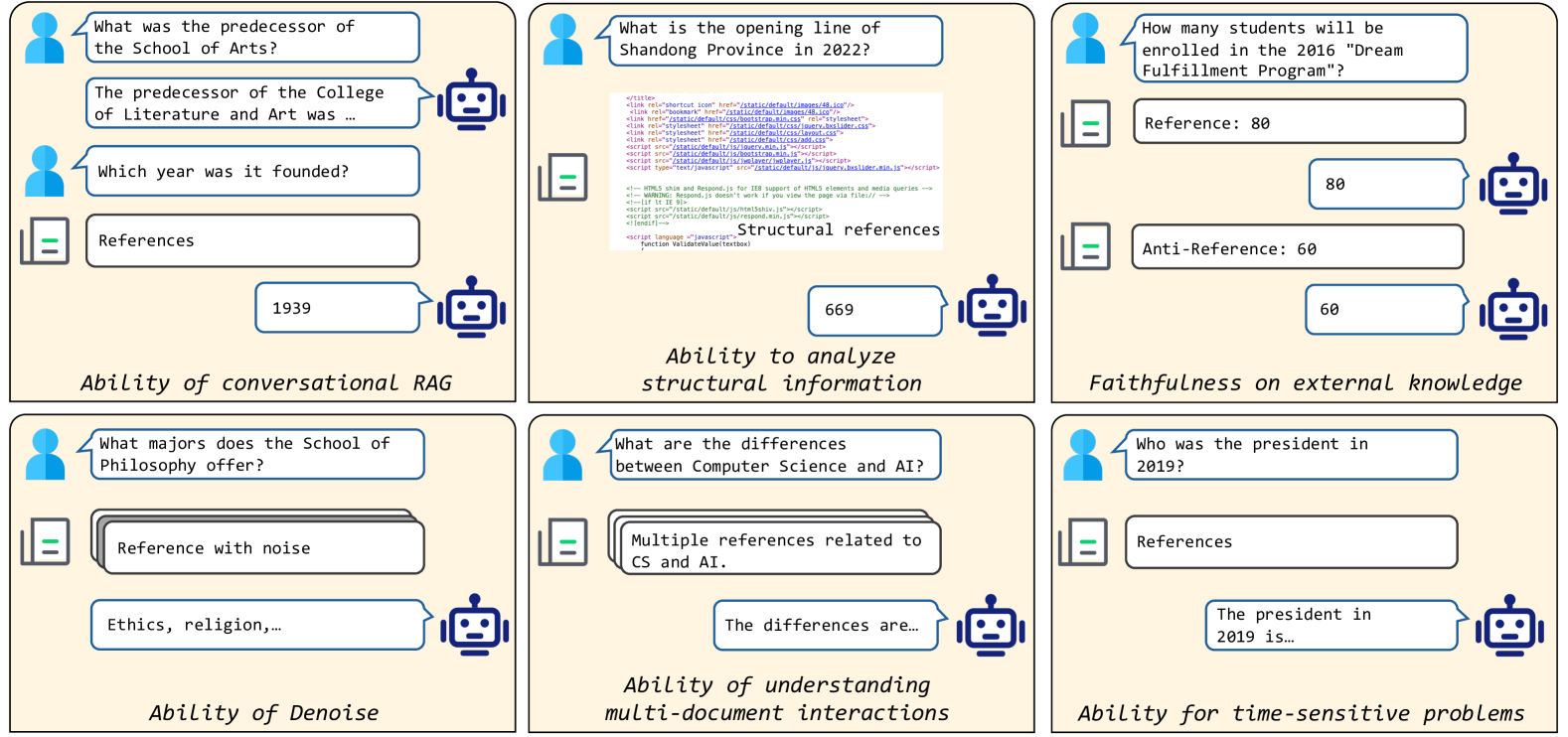
DomainRAG: A Chinese Benchmark for Evaluating Domain-specific Retrieval-Augmented Generation
Shuting Wang, Jiongnan Liu, Shiren Song, Jiehan Cheng, Yuqi Fu, Peidong Guo, Kun Fang, Yutao Zhu, Zhicheng Dou
Retrieval-Augmented Generation (RAG) offers a promising solution to address various limitations of Large Language Models (LLMs), such as hallucination and difficulties in keeping up with real-time updates. This approach is particularly critical in expert and domain-specific applications where LLMs struggle to cover expert knowledge. Therefore, evaluating RAG models in such scenarios is crucial, yet current studies often rely on general knowledge sources like Wikipedia to assess the models' abilities in solving common-sense problems. In this paper, we evaluated LLMs by RAG settings in a domain-specific context, college enrollment. We identified six required abilities for RAG models, including the ability in conversational RAG, analyzing structural information, faithfulness to external knowledge, denoising, solving time-sensitive problems, and understanding multi-document interactions. Each ability has an associated dataset with shared corpora to evaluate the RAG models' performance. We evaluated popular LLMs such as Llama, Baichuan, ChatGLM, and GPT models. Experimental results indicate that existing closed-book LLMs struggle with domain-specific questions, highlighting the need for RAG models to solve expert problems. Moreover, there is room for RAG models to improve their abilities in comprehending conversational history, analyzing structural information, denoising, processing multi-document interactions, and faithfulness in expert knowledge. We expect future studies could solve these problems better.
Read more6/18/2024