Non-Coherent Over-the-Air Decentralized Gradient Descent

0
⛏️
Sign in to get full access
Overview
- Decentralized Gradient Descent (DGD) is a challenging technique for wireless systems due to noise, fading, and bandwidth limitations
- This paper introduces a scalable DGD algorithm that eliminates the need for scheduling, topology information, or channel state information (CSI)
- The core is a Non-Coherent Over-The-Air (NCOTA) consensus scheme that exploits the noisy energy superposition property of wireless channels
Plain English Explanation
In wireless networks, it can be difficult to coordinate the exchange of information needed for decentralized optimization techniques like Decentralized Gradient Descent (DGD). Factors like signal interference, fading, and limited bandwidth mean the network nodes need to know details about the connections between each other (the "topology") and the current wireless conditions (the "channel state information") in order to schedule and coordinate their transmissions effectively.
This paper presents a new DGD algorithm that sidesteps these challenges. At its core is a technique called "Non-Coherent Over-The-Air (NCOTA) consensus" that exploits a property of wireless signals. When multiple nodes transmit at the same time, the energy level of the combined signal is roughly equal to the sum of the individual energy levels, scaled by the average signal strengths of each node's connection.
The key insight is that this property can be used for consensus - where the nodes collectively agree on a shared value - without needing any explicit coordination or knowledge of the network topology or wireless conditions. Each node just encodes its local optimization signal into the energy level of its transmission, sending it out simultaneously with the others. The received energy level then represents the weighted average of all the nodes' signals, allowing consensus to be achieved.
By introducing a carefully designed consensus step size, this NCOTA approach can provably drive the local models at each node to converge to the globally optimal model at a fast rate, even in the presence of various types of fading. Experiments show it outperforms state-of-the-art decentralized optimization methods, especially in dense network scenarios where coordination is most challenging.
Technical Explanation
The core innovation of this paper is the Non-Coherent Over-The-Air (NCOTA) consensus scheme, which allows the nodes to perform consensus without needing any knowledge of the network topology or channel state information (CSI).
The key insight is that when multiple nodes transmit wireless signals simultaneously, the received energy level is equal, on average, to the sum of the individual transmitted energy levels, scaled by their respective average channel gains. This noisy "energy superposition" property enables unbiased consensus estimation, using the average channel gains as implicit mixing weights.
Specifically, each node encodes its local optimization signal (e.g. the gradient of its loss function) into the energy level of an OFDM subcarrier, and transmits this simultaneously with the other nodes, without any coordination. The received energy level then represents the weighted average of all the nodes' signals, allowing consensus to be achieved.
To mitigate errors in this consensus estimation due to energy fluctuations around the expected values, the authors introduce a consensus step size that decreases over time. They prove that for strongly convex optimization problems, this NCOTA approach can drive the local models at each node to converge to the globally optimal model at a rate of O(1/sqrt(k)) after k iterations, with suitable diminishing learning and consensus step sizes.
The authors also extend their approach to accommodate a broad class of fading models and frequency-selective channels. Numerical experiments on image classification tasks show faster convergence compared to state-of-the-art decentralized optimization schemes, especially in dense network scenarios where coordination overhead is most challenging.
Critical Analysis
The NCOTA consensus approach presented in this paper successfully eliminates the need for scheduling, topology information, and channel state information (CSI) in decentralized optimization. This is a notable advancement, as acquiring and managing this coordination information can be a major obstacle, especially in large-scale wireless networks.
However, the authors acknowledge some limitations and caveats. The theoretical analysis assumes strongly convex objective functions, which may not hold in all practical machine learning applications. Additionally, while the NCOTA method can handle various fading models, it may be sensitive to extreme fluctuations in the wireless channel conditions.
It would also be valuable to further explore the scalability and robustness of this approach, particularly in the face of stragglers or adversarial attacks that could disrupt the consensus process. Evaluating the method's performance on a broader range of decentralized learning tasks and real-world datasets would also help assess its practical utility.
Overall, this paper presents a clever and promising technique for enabling decentralized optimization in wireless networks. While further research is needed to fully understand its capabilities and limitations, the NCOTA consensus approach is an important step forward in addressing the coordination challenges that have historically plagued DGD in these settings.
Conclusion
This paper introduces a scalable Decentralized Gradient Descent (DGD) algorithm that eliminates the need for scheduling, topology information, or channel state information (CSI) in wireless systems. At its core is a novel "Non-Coherent Over-The-Air (NCOTA) consensus" scheme that exploits the noisy energy superposition property of wireless channels to achieve consensus without explicit coordination.
By carefully designing a consensus step size, the NCOTA approach can provably drive the local models at each node to converge to the globally optimal model at a fast rate, even in the presence of various types of fading. Experiments show this method outperforms state-of-the-art decentralized optimization techniques, particularly in dense network scenarios where coordination overhead is most challenging.
While the current analysis assumes strongly convex objectives and may have some sensitivity to extreme channel conditions, this work represents an important advance in enabling robust, scalable decentralized learning over wireless networks. Further research is needed to fully assess the capabilities and limitations of this approach, but the NCOTA consensus technique is a promising step forward in this critical area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
0
Non-Coherent Over-the-Air Decentralized Gradient Descent
Nicolo' Michelusi
Implementing Decentralized Gradient Descent (DGD) in wireless systems is challenging due to noise, fading, and limited bandwidth, necessitating topology awareness, transmission scheduling, and the acquisition of channel state information (CSI) to mitigate interference and maintain reliable communications. These operations may result in substantial signaling overhead and scalability challenges in large networks lacking central coordination. This paper introduces a scalable DGD algorithm that eliminates the need for scheduling, topology information, or CSI (both average and instantaneous). At its core is a Non-Coherent Over-The-Air (NCOTA) consensus scheme that exploits a noisy energy superposition property of wireless channels. Nodes encode their local optimization signals into energy levels within an OFDM frame and transmit simultaneously, without coordination. The key insight is that the received energy equals, on average, the sum of the energies of the transmitted signals, scaled by their respective average channel gains, akin to a consensus step. This property enables unbiased consensus estimation, utilizing average channel gains as mixing weights, thereby removing the need for their explicit design or for CSI. Introducing a consensus stepsize mitigates consensus estimation errors due to energy fluctuations around their expected values. For strongly-convex problems, it is shown that the expected squared distance between the local and globally optimum models vanishes at a rate of O(1/sqrt{k}) after k iterations, with suitable decreasing learning and consensus stepsizes. Extensions accommodate a broad class of fading models and frequency-selective channels. Numerical experiments on image classification demonstrate faster convergence in terms of running time compared to state-of-the-art schemes, especially in dense network scenarios.
Read more9/14/2024
0
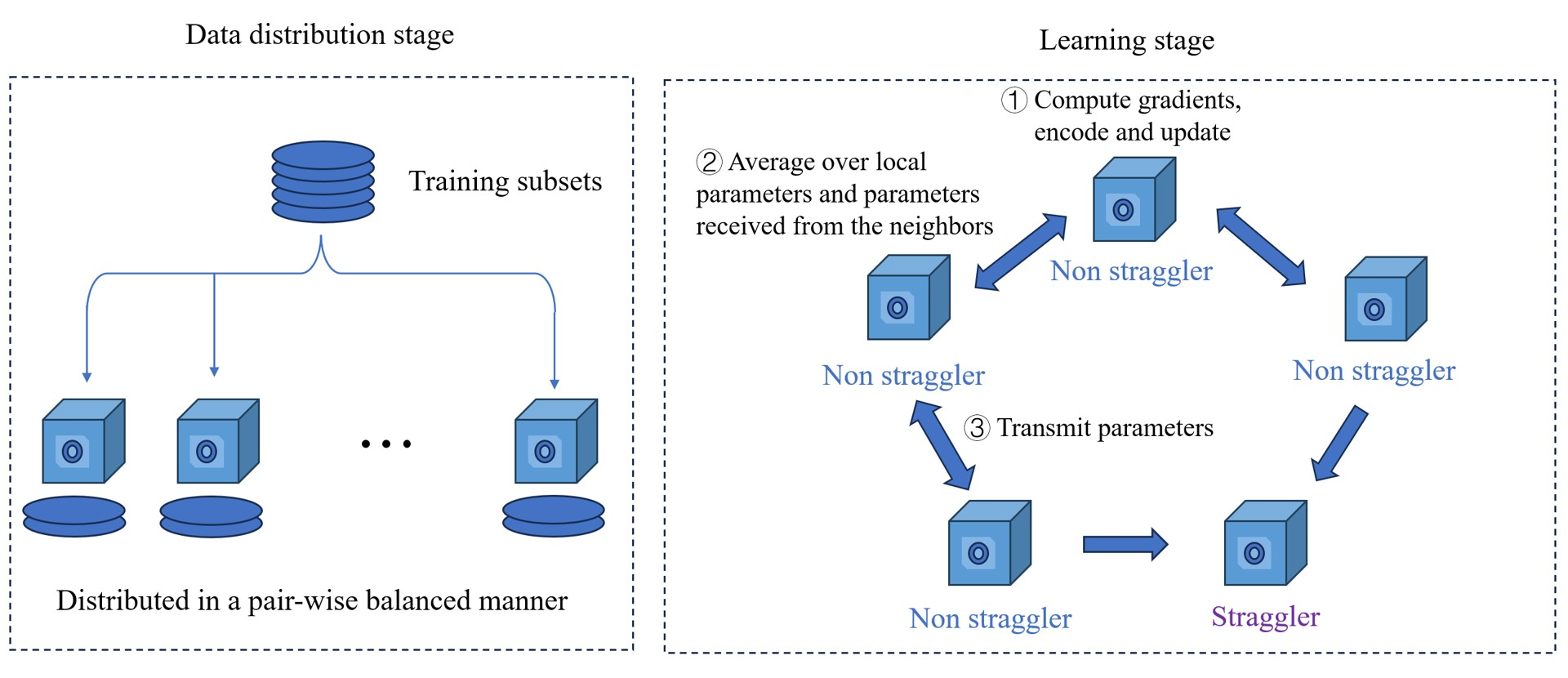
Gradient Coding in Decentralized Learning for Evading Stragglers
Chengxi Li, Mikael Skoglund
In this paper, we consider a decentralized learning problem in the presence of stragglers. Although gradient coding techniques have been developed for distributed learning to evade stragglers, where the devices send encoded gradients with redundant training data, it is difficult to apply those techniques directly to decentralized learning scenarios. To deal with this problem, we propose a new gossip-based decentralized learning method with gradient coding (GOCO). In the proposed method, to avoid the negative impact of stragglers, the parameter vectors are updated locally using encoded gradients based on the framework of stochastic gradient coding and then averaged in a gossip-based manner. We analyze the convergence performance of GOCO for strongly convex loss functions. And we also provide simulation results to demonstrate the superiority of the proposed method in terms of learning performance compared with the baseline methods.
Read more6/17/2024
0
Decentralized Optimization in Time-Varying Networks with Arbitrary Delays
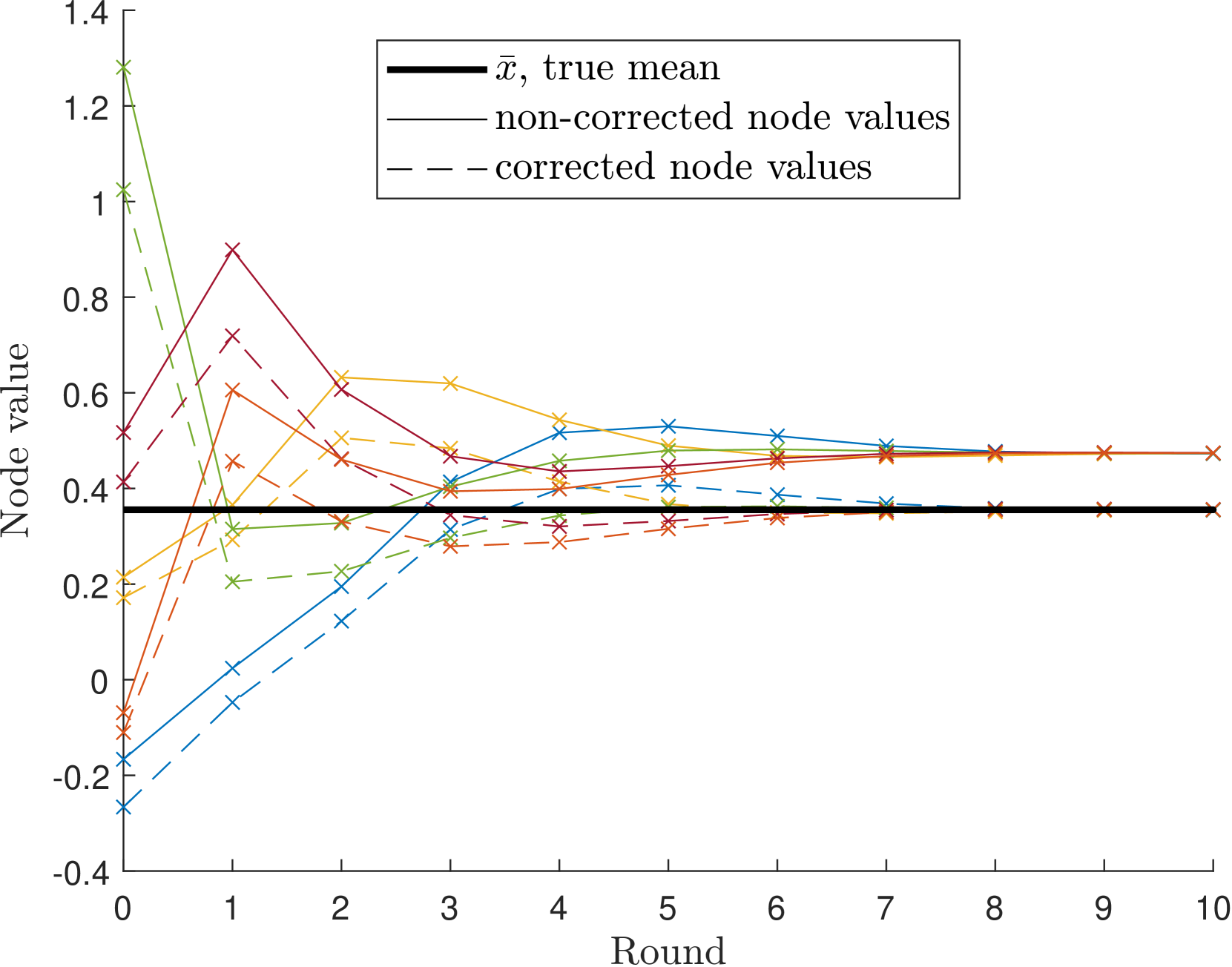
Tomas Ortega, Hamid Jafarkhani
We consider a decentralized optimization problem for networks affected by communication delays. Examples of such networks include collaborative machine learning, sensor networks, and multi-agent systems. To mimic communication delays, we add virtual non-computing nodes to the network, resulting in directed graphs. This motivates investigating decentralized optimization solutions on directed graphs. Existing solutions assume nodes know their out-degrees, resulting in limited applicability. To overcome this limitation, we introduce a novel gossip-based algorithm, called DT-GO, that does not need to know the out-degrees. The algorithm is applicable in general directed networks, for example networks with delays or limited acknowledgment capabilities. We derive convergence rates for both convex and non-convex objectives, showing that our algorithm achieves the same complexity order as centralized Stochastic Gradient Descent. In other words, the effects of the graph topology and delays are confined to higher-order terms. Additionally, we extend our analysis to accommodate time-varying network topologies. Numerical simulations are provided to support our theoretical findings.
Read more5/31/2024
0
Decentralized Stochastic Subgradient Methods for Nonsmooth Nonconvex Optimization
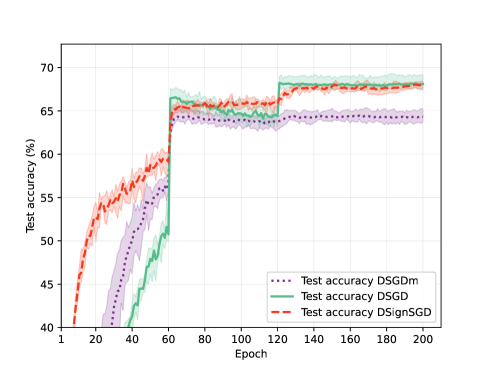
Siyuan Zhang, Nachuan Xiao, Xin Liu
In this paper, we concentrate on decentralized optimization problems with nonconvex and nonsmooth objective functions, especially on the decentralized training of nonsmooth neural networks. We introduce a unified framework to analyze the global convergence of decentralized stochastic subgradient-based methods. We prove the global convergence of our proposed framework under mild conditions, by establishing that the generated sequence asymptotically approximates the trajectories of its associated differential inclusion. Furthermore, we establish that our proposed framework covers a wide range of existing efficient decentralized subgradient-based methods, including decentralized stochastic subgradient descent (DSGD), DSGD with gradient-tracking technique (DSGD-T), and DSGD with momentum (DSGD-M). In addition, we introduce the sign map to regularize the update directions in DSGD-M, and show it is enclosed in our proposed framework. Consequently, our convergence results establish, for the first time, global convergence of these methods when applied to nonsmooth nonconvex objectives. Preliminary numerical experiments demonstrate that our proposed framework yields highly efficient decentralized subgradient-based methods with convergence guarantees in the training of nonsmooth neural networks.
Read more6/28/2024