NormTab: Improving Symbolic Reasoning in LLMs Through Tabular Data Normalization
2406.17961
0
0
Abstract
In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities in parsing textual data and generating code. However, their performance in tasks involving tabular data, especially those requiring symbolic reasoning, faces challenges due to the structural variance and inconsistency in table cell values often found in web tables. In this paper, we introduce NormTab, a novel framework aimed at enhancing the symbolic reasoning performance of LLMs by normalizing web tables. We study table normalization as a stand-alone, one-time preprocessing step using LLMs to support symbolic reasoning on tabular data. Our experimental evaluation, conducted on challenging web table datasets such as WikiTableQuestion and TabFact, demonstrates that leveraging NormTab significantly improves symbolic reasoning performance, showcasing the importance and effectiveness of web table normalization for enhancing LLM-based symbolic reasoning tasks.
Create account to get full access
Overview
- This paper introduces NormTab, a technique to improve the symbolic reasoning capabilities of large language models (LLMs) when working with tabular data.
- The key idea is to normalize the tabular data before feeding it to the LLM, which can help the model better understand and reason about the underlying structure and relationships in the data.
- The authors evaluate NormTab on a range of tasks, including TabSQLify, OpenTab, and Tables as Texts or Images, and find that it leads to significant performance improvements compared to using raw tabular data.
Plain English Explanation
The paper tackles the challenge of helping large language models (LLMs) like GPT-3 or BERT work more effectively with tabular data, which is a common format for storing and organizing information. Tabular data, with its rows and columns, has a specific structure that can be difficult for LLMs to fully understand and reason about.
The researchers developed a technique called NormTab that preprocesses the tabular data before feeding it to the LLM. The key idea is to normalize or standardize the data, which means transforming it into a more consistent and structured format. This can help the LLM better grasp the underlying relationships and patterns in the data, allowing it to reason about the information more effectively.
The researchers tested NormTab on several benchmarks that evaluate how well LLMs can perform tasks like answering questions about tables, generating SQL queries, or understanding the contents of tables. They found that using NormTab significantly improved the LLM's performance compared to just using the raw tabular data.
This is an important advance because LLMs are becoming increasingly powerful and versatile, but they still struggle with certain types of structured data like tables. By developing techniques like NormTab, researchers are finding ways to enhance the reasoning capabilities of LLMs, enabling them to better understand and work with the wide variety of data formats and structures that are common in the real world.
Technical Explanation
The key contribution of this paper is the NormTab technique, which aims to improve the symbolic reasoning capabilities of LLMs when working with tabular data. The authors hypothesize that the inherent structure and relational nature of tabular data can be challenging for LLMs to fully capture and reason about, and that normalizing the data can help address this issue.
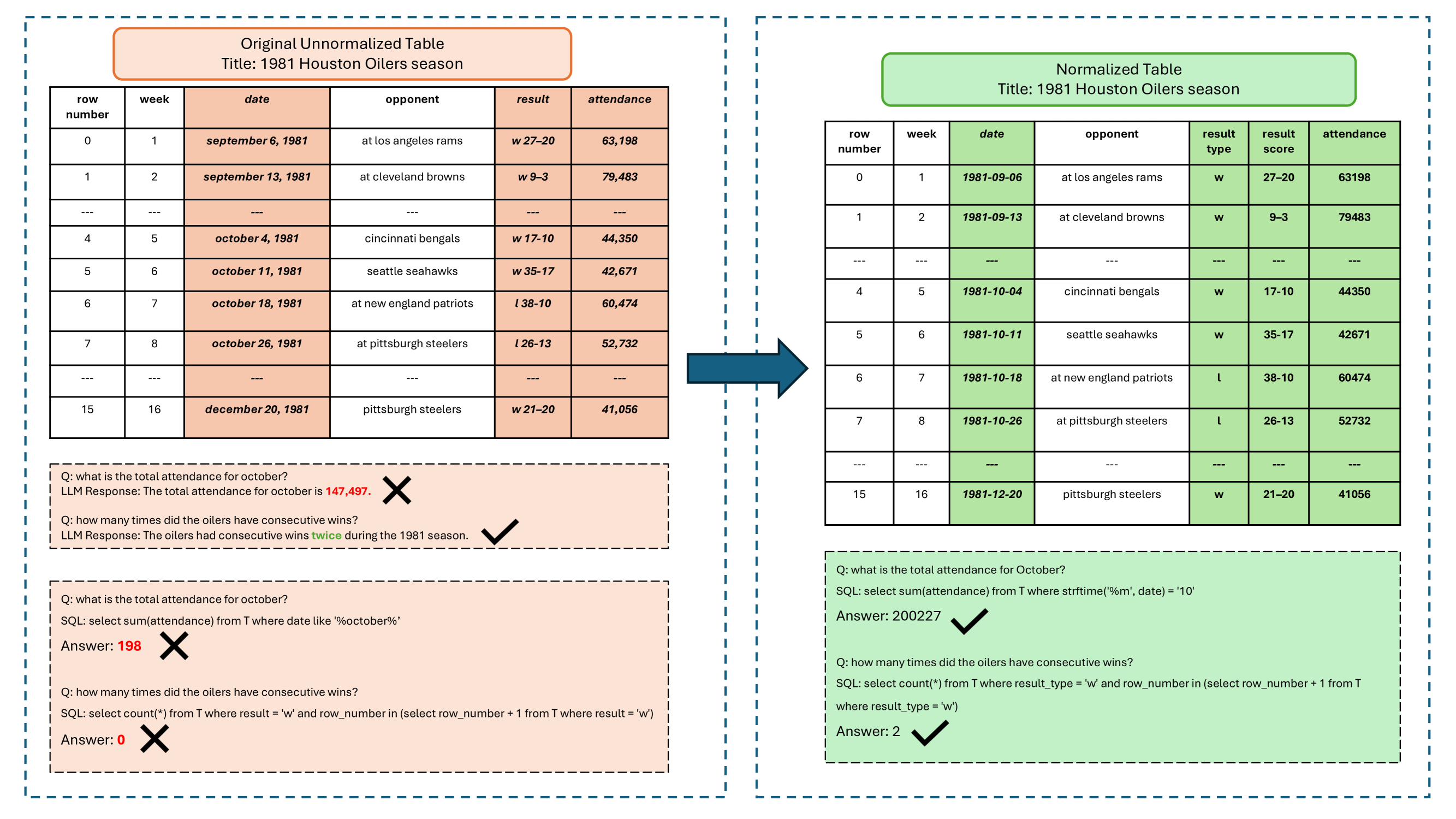
The NormTab preprocessing step involves several transformations to the input tabular data:
- Column flattening: The table is flattened into a sequence of column-value pairs, preserving the column and row structure.
- Column type encoding: The data type of each column (e.g., numerical, categorical, date) is encoded using a learned embedding.
- Row-column position encoding: The row and column position of each cell is encoded using learned positional embeddings.
These normalized representations are then concatenated and fed into the LLM as input, allowing the model to better understand the structure and relationships within the table.
The authors evaluate NormTab on a range of benchmarks, including TabSQLify, OpenTab, and Tables as Texts or Images. They find that NormTab consistently outperforms using the raw tabular data as input, demonstrating the effectiveness of their approach.
Additionally, the authors explore the performance of NormTab on the Are LLMs Naturally Good at Synthetic Tabular Data? benchmark, which evaluates how well LLMs can reason about synthetic tabular data. They find that NormTab improves performance on this task as well, suggesting that the normalization technique can help LLMs better understand the underlying structure and relationships in tabular data, even when the data is synthetically generated.
Critical Analysis
The NormTab approach presented in this paper is a promising step towards improving the symbolic reasoning capabilities of LLMs when working with tabular data. The authors demonstrate the effectiveness of their technique across a range of benchmarks, which is a notable achievement.
However, the paper does not address certain limitations and potential issues with the NormTab approach. For example, the impact of the normalization process on the model's ability to handle real-world, noisy, or incomplete tabular data is not explored. It would be valuable to understand how NormTab performs in more realistic scenarios where the data may not be as clean or structured as the benchmarks used in the study.
Additionally, the paper does not provide a detailed analysis of the computational and memory overhead introduced by the NormTab preprocessing step. As LLMs continue to grow in size and complexity, the efficiency of preprocessing techniques will become increasingly important, especially for deployment in real-world applications.
Further research could also investigate the generalizability of NormTab to other types of structured data beyond tabular formats, such as large language models for tabular data prediction and generation. Exploring how the normalization approach can be adapted or extended to handle a broader range of data structures could significantly expand the utility of the technique.
Conclusion
The NormTab technique introduced in this paper represents a valuable contribution to the ongoing effort to enhance the symbolic reasoning capabilities of large language models when working with tabular data. By normalizing the input data, the authors have shown that LLMs can better understand and reason about the underlying structure and relationships, leading to significant performance improvements on a range of benchmarks.
While the paper does not address certain limitations, such as the impact of NormTab on real-world, noisy data or the computational overhead of the preprocessing step, the overall approach demonstrates the potential for leveraging normalization techniques to improve the versatility and effectiveness of large language models. As these models continue to be widely adopted across a variety of applications, developing strategies to enhance their capabilities with structured data formats like tables will be increasingly important.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
TabSQLify: Enhancing Reasoning Capabilities of LLMs Through Table Decomposition
Md Mahadi Hasan Nahid, Davood Rafiei
0
0
Table reasoning is a challenging task that requires understanding both natural language questions and structured tabular data. Large language models (LLMs) have shown impressive capabilities in natural language understanding and generation, but they often struggle with large tables due to their limited input length. In this paper, we propose TabSQLify, a novel method that leverages text-to-SQL generation to decompose tables into smaller and relevant sub-tables, containing only essential information for answering questions or verifying statements, before performing the reasoning task. In our comprehensive evaluation on four challenging datasets, our approach demonstrates comparable or superior performance compared to prevailing methods reliant on full tables as input. Moreover, our method can reduce the input context length significantly, making it more scalable and efficient for large-scale table reasoning applications. Our method performs remarkably well on the WikiTQ benchmark, achieving an accuracy of 64.7%. Additionally, on the TabFact benchmark, it achieves a high accuracy of 79.5%. These results surpass other LLM-based baseline models on gpt-3.5-turbo (chatgpt). TabSQLify can reduce the table size significantly alleviating the computational load on LLMs when handling large tables without compromising performance.
4/17/2024

OpenTab: Advancing Large Language Models as Open-domain Table Reasoners
Kezhi Kong, Jiani Zhang, Zhengyuan Shen, Balasubramaniam Srinivasan, Chuan Lei, Christos Faloutsos, Huzefa Rangwala, George Karypis
0
0
Large Language Models (LLMs) trained on large volumes of data excel at various natural language tasks, but they cannot handle tasks requiring knowledge that has not been trained on previously. One solution is to use a retriever that fetches relevant information to expand LLM's knowledge scope. However, existing textual-oriented retrieval-based LLMs are not ideal on structured table data due to diversified data modalities and large table sizes. In this work, we propose OpenTab, an open-domain table reasoning framework powered by LLMs. Overall, OpenTab leverages table retriever to fetch relevant tables and then generates SQL programs to parse the retrieved tables efficiently. Utilizing the intermediate data derived from the SQL executions, it conducts grounded inference to produce accurate response. Extensive experimental evaluation shows that OpenTab significantly outperforms baselines in both open- and closed-domain settings, achieving up to 21.5% higher accuracy. We further run ablation studies to validate the efficacy of our proposed designs of the system.
4/16/2024

Tables as Texts or Images: Evaluating the Table Reasoning Ability of LLMs and MLLMs
Naihao Deng, Zhenjie Sun, Ruiqi He, Aman Sikka, Yulong Chen, Lin Ma, Yue Zhang, Rada Mihalcea
0
0
In this paper, we investigate the effectiveness of various LLMs in interpreting tabular data through different prompting strategies and data formats. Our analyses extend across six benchmarks for table-related tasks such as question-answering and fact-checking. We introduce for the first time the assessment of LLMs' performance on image-based table representations. Specifically, we compare five text-based and three image-based table representations, demonstrating the role of representation and prompting on LLM performance. Our study provides insights into the effective use of LLMs on table-related tasks.
6/7/2024
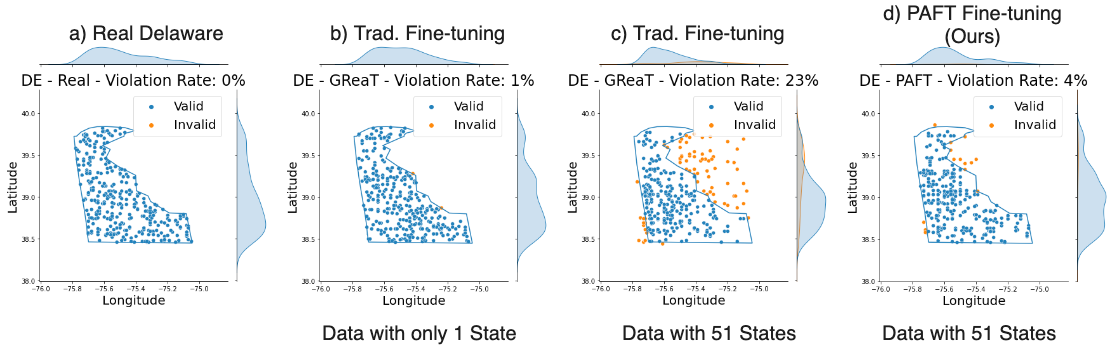
Are LLMs Naturally Good at Synthetic Tabular Data Generation?
Shengzhe Xu, Cho-Ting Lee, Mandar Sharma, Raquib Bin Yousuf, Nikhil Muralidhar, Naren Ramakrishnan
0
0
Large language models (LLMs) have demonstrated their prowess in generating synthetic text and images; however, their potential for generating tabular data -- arguably the most common data type in business and scientific applications -- is largely underexplored. This paper demonstrates that LLMs, used as-is, or after traditional fine-tuning, are severely inadequate as synthetic table generators. Due to the autoregressive nature of LLMs, fine-tuning with random order permutation runs counter to the importance of modeling functional dependencies, and renders LLMs unable to model conditional mixtures of distributions (key to capturing real world constraints). We showcase how LLMs can be made to overcome some of these deficiencies by making them permutation-aware.
6/24/2024