TabSQLify: Enhancing Reasoning Capabilities of LLMs Through Table Decomposition
2404.10150
0
0
Abstract
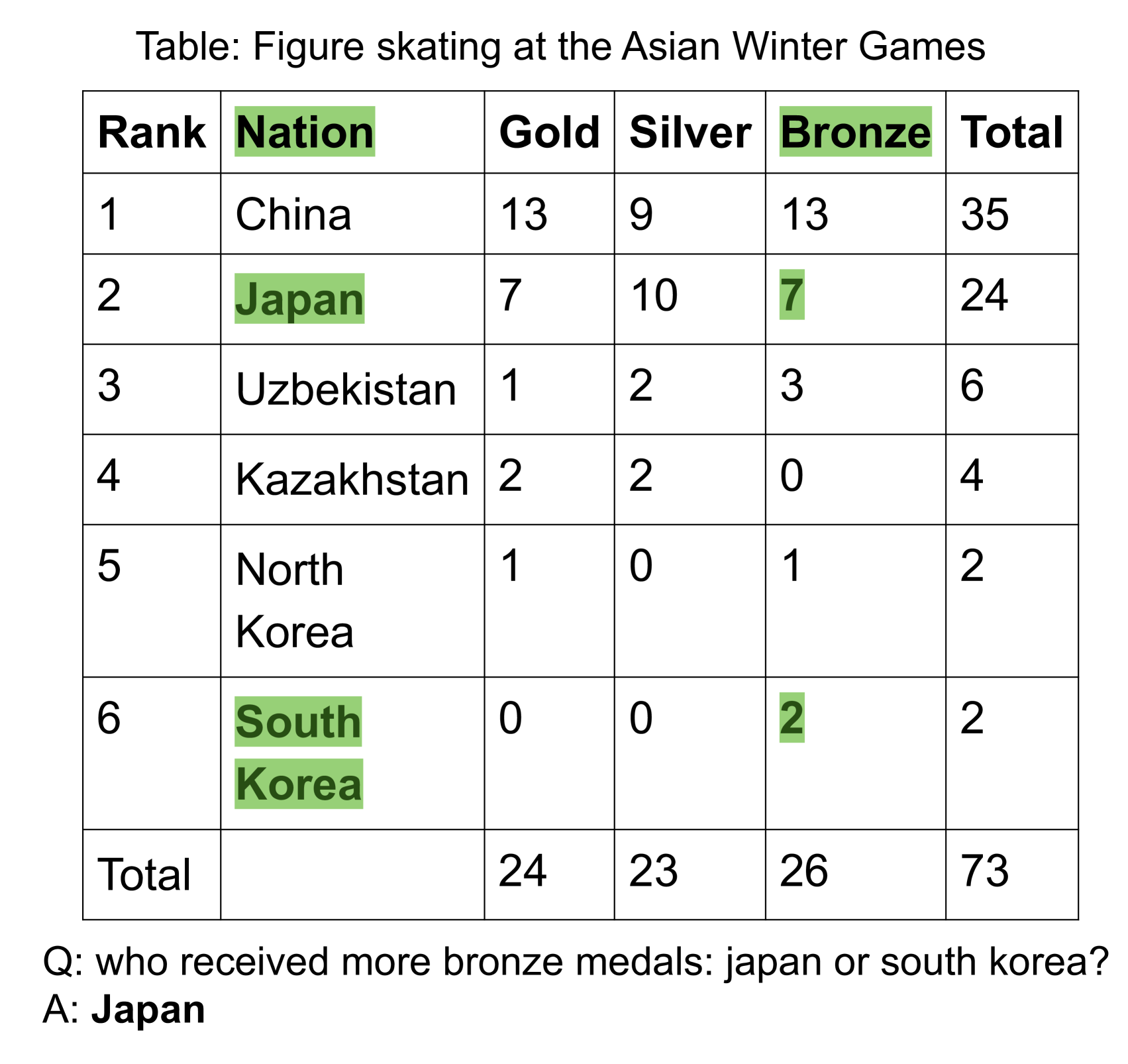
Table reasoning is a challenging task that requires understanding both natural language questions and structured tabular data. Large language models (LLMs) have shown impressive capabilities in natural language understanding and generation, but they often struggle with large tables due to their limited input length. In this paper, we propose TabSQLify, a novel method that leverages text-to-SQL generation to decompose tables into smaller and relevant sub-tables, containing only essential information for answering questions or verifying statements, before performing the reasoning task. In our comprehensive evaluation on four challenging datasets, our approach demonstrates comparable or superior performance compared to prevailing methods reliant on full tables as input. Moreover, our method can reduce the input context length significantly, making it more scalable and efficient for large-scale table reasoning applications. Our method performs remarkably well on the WikiTQ benchmark, achieving an accuracy of 64.7%. Additionally, on the TabFact benchmark, it achieves a high accuracy of 79.5%. These results surpass other LLM-based baseline models on gpt-3.5-turbo (chatgpt). TabSQLify can reduce the table size significantly alleviating the computational load on LLMs when handling large tables without compromising performance.
Create account to get full access
Overview
- This paper introduces TabSQLify, a novel approach to enhance the reasoning capabilities of large language models (LLMs) through table decomposition.
- The key idea is to break down complex tabular data into smaller, more manageable components, allowing LLMs to better understand and reason about the information.
- The authors demonstrate that this technique can significantly improve the performance of LLMs on various table-related tasks, such as question answering and data analysis.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, when it comes to working with structured data like tables, LLMs can struggle. TabSQLify: Enhancing Reasoning Capabilities of LLMs Through Table Decomposition introduces a new way to help LLMs better understand and reason about tabular data.
The core concept is to break down complex tables into smaller, more digestible pieces. Instead of trying to process an entire table at once, the LLM can focus on one part of the table at a time. This makes it easier for the model to grasp the relationships and patterns within the data.
By breaking down the tables in this way, the authors show that LLMs can perform much better on tasks like answering questions about the data or analyzing the information in the tables. This is an important step in advancing the capabilities of LLMs to work with structured data, which could have many real-world applications, such as in data analysis, decision-making, and more.
Technical Explanation
TabSQLify works by taking a table as input and decomposing it into smaller, more manageable components. This includes breaking the table down into individual columns, rows, and cells. The LLM is then trained on these decomposed elements, learning how to understand and reason about the relationships between them.
During inference, the LLM processes the table in a step-by-step fashion, first examining the individual components and then gradually building up its understanding of the overall table. This allows the model to more effectively capture the semantics and structure of the tabular data, leading to improved performance on a variety of table-related tasks.
The authors evaluate TabSQLify on several benchmark datasets, including TableQA and WikiSQL. The results show that TabSQLify consistently outperforms baseline LLM approaches, demonstrating the effectiveness of the table decomposition technique.
Critical Analysis
The paper presents a well-designed and comprehensive study, but there are a few areas that could be explored further:
-
Generalization to different table types: The experiments in the paper focus on relatively simple tabular data, such as those found in popular benchmarks. It would be interesting to see how well TabSQLify performs on more complex, real-world tables with diverse structures and content.
-
Interpretability of the decomposition process: While the table decomposition approach seems to improve LLM performance, the paper does not provide much insight into how the models are actually using the decomposed information. A more in-depth analysis of the internal workings of TabSQLify could help us better understand its strengths and limitations.
-
Scalability and efficiency: The paper does not address the computational and memory requirements of the table decomposition process. As LLMs continue to grow in size and complexity, it will be important to ensure that this approach remains scalable and efficient.
Overall, the TabSQLify paper represents a significant contribution to the field of enhancing LLM reasoning with tabular data. The authors have demonstrated a promising technique that could have far-reaching implications for a wide range of applications.
Conclusion
TabSQLify offers a novel approach to improve the reasoning capabilities of large language models when working with tabular data. By decomposing complex tables into smaller, more manageable components, the model can better understand and reason about the relationships and patterns within the data.
The authors have shown that this technique can significantly boost the performance of LLMs on a variety of table-related tasks, such as question answering and data analysis. This represents an important step forward in advancing the capabilities of LLMs to work with structured data, which could have far-reaching implications for many real-world applications.
While the paper presents a well-designed and comprehensive study, there are a few areas that could be explored further, such as the generalization to different table types, the interpretability of the decomposition process, and the scalability and efficiency of the approach. Overall, TabSQLify is a promising and innovative contribution to the field of AI and natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
NormTab: Improving Symbolic Reasoning in LLMs Through Tabular Data Normalization
Md Mahadi Hasan Nahid, Davood Rafiei
0
0
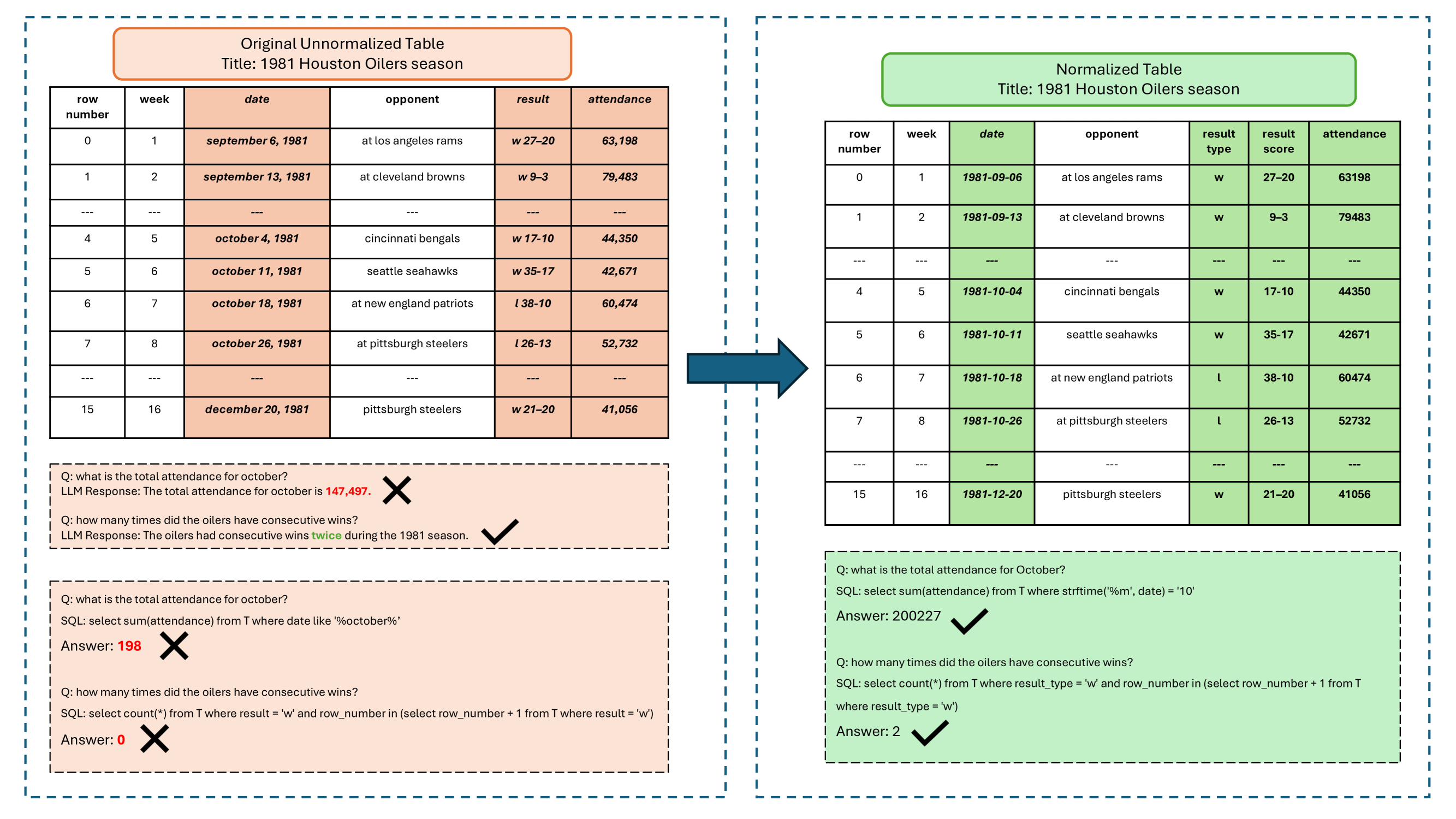
In recent years, Large Language Models (LLMs) have demonstrated remarkable capabilities in parsing textual data and generating code. However, their performance in tasks involving tabular data, especially those requiring symbolic reasoning, faces challenges due to the structural variance and inconsistency in table cell values often found in web tables. In this paper, we introduce NormTab, a novel framework aimed at enhancing the symbolic reasoning performance of LLMs by normalizing web tables. We study table normalization as a stand-alone, one-time preprocessing step using LLMs to support symbolic reasoning on tabular data. Our experimental evaluation, conducted on challenging web table datasets such as WikiTableQuestion and TabFact, demonstrates that leveraging NormTab significantly improves symbolic reasoning performance, showcasing the importance and effectiveness of web table normalization for enhancing LLM-based symbolic reasoning tasks.
6/27/2024

OpenTab: Advancing Large Language Models as Open-domain Table Reasoners
Kezhi Kong, Jiani Zhang, Zhengyuan Shen, Balasubramaniam Srinivasan, Chuan Lei, Christos Faloutsos, Huzefa Rangwala, George Karypis
0
0
Large Language Models (LLMs) trained on large volumes of data excel at various natural language tasks, but they cannot handle tasks requiring knowledge that has not been trained on previously. One solution is to use a retriever that fetches relevant information to expand LLM's knowledge scope. However, existing textual-oriented retrieval-based LLMs are not ideal on structured table data due to diversified data modalities and large table sizes. In this work, we propose OpenTab, an open-domain table reasoning framework powered by LLMs. Overall, OpenTab leverages table retriever to fetch relevant tables and then generates SQL programs to parse the retrieved tables efficiently. Utilizing the intermediate data derived from the SQL executions, it conducts grounded inference to produce accurate response. Extensive experimental evaluation shows that OpenTab significantly outperforms baselines in both open- and closed-domain settings, achieving up to 21.5% higher accuracy. We further run ablation studies to validate the efficacy of our proposed designs of the system.
4/16/2024

Uncovering Limitations of Large Language Models in Information Seeking from Tables
Chaoxu Pang, Yixuan Cao, Chunhao Yang, Ping Luo
0
0
Tables are recognized for their high information density and widespread usage, serving as essential sources of information. Seeking information from tables (TIS) is a crucial capability for Large Language Models (LLMs), serving as the foundation of knowledge-based Q&A systems. However, this field presently suffers from an absence of thorough and reliable evaluation. This paper introduces a more reliable benchmark for Table Information Seeking (TabIS). To avoid the unreliable evaluation caused by text similarity-based metrics, TabIS adopts a single-choice question format (with two options per question) instead of a text generation format. We establish an effective pipeline for generating options, ensuring their difficulty and quality. Experiments conducted on 12 LLMs reveal that while the performance of GPT-4-turbo is marginally satisfactory, both other proprietary and open-source models perform inadequately. Further analysis shows that LLMs exhibit a poor understanding of table structures, and struggle to balance between TIS performance and robustness against pseudo-relevant tables (common in retrieval-augmented systems). These findings uncover the limitations and potential challenges of LLMs in seeking information from tables. We release our data and code to facilitate further research in this field.
6/7/2024
Generating Tables from the Parametric Knowledge of Language Models
Yevgeni Berkovitch, Oren Glickman, Amit Somech, Tomer Wolfson
0
0
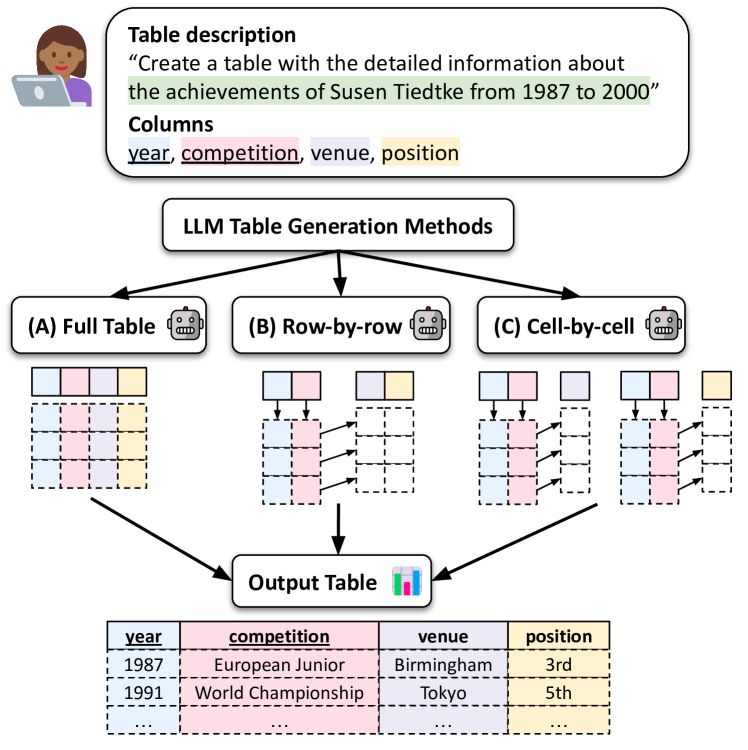
We explore generating factual and accurate tables from the parametric knowledge of large language models (LLMs). While LLMs have demonstrated impressive capabilities in recreating knowledge bases and generating free-form text, we focus on generating structured tabular data, which is crucial in domains like finance and healthcare. We examine the table generation abilities of four state-of-the-art LLMs: GPT-3.5, GPT-4, Llama2-13B, and Llama2-70B, using three prompting methods for table generation: (a) full-table, (b) row-by-row; (c) cell-by-cell. For evaluation, we introduce a novel benchmark, WikiTabGen which contains 100 curated Wikipedia tables. Tables are further processed to ensure their factual correctness and manually annotated with short natural language descriptions. Our findings reveal that table generation remains a challenge, with GPT-4 reaching the highest accuracy at 19.6%. Our detailed analysis sheds light on how various table properties, such as size, table popularity, and numerical content, influence generation performance. This work highlights the unique challenges in LLM-based table generation and provides a solid evaluation framework for future research. Our code, prompts and data are all publicly available: https://github.com/analysis-bots/WikiTabGen
6/18/2024