Tables as Texts or Images: Evaluating the Table Reasoning Ability of LLMs and MLLMs
2402.12424
0
0

Abstract
In this paper, we investigate the effectiveness of various LLMs in interpreting tabular data through different prompting strategies and data formats. Our analyses extend across six benchmarks for table-related tasks such as question-answering and fact-checking. We introduce for the first time the assessment of LLMs' performance on image-based table representations. Specifically, we compare five text-based and three image-based table representations, demonstrating the role of representation and prompting on LLM performance. Our study provides insights into the effective use of LLMs on table-related tasks.
Create account to get full access
Overview
- This paper explores the use of multimodal prompting strategies, which combine text and other modalities like images or tables, to improve the performance of large language models (LLMs) on tabular data tasks.
- The researchers conduct a comparative analysis to understand how different multimodal prompting approaches affect the performance of LLMs on various tabular data tasks.
- The paper aims to provide insights into the potential of multimodal prompting to enhance the capabilities of LLMs when working with structured data.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can understand and generate human-like text. However, they can struggle with tasks that involve structured data, such as tables or spreadsheets. This paper investigates ways to improve the performance of LLMs on these types of tasks by using multimodal prompting.
Multimodal prompting means providing the LLM with information in multiple formats, such as text and tables or images, to help it better understand the task at hand. The researchers in this study tested different multimodal prompting strategies to see which ones were most effective for improving the LLM's ability to work with tabular data.
For example, they might show the LLM a table of financial data and ask it to summarize the key insights. By combining the textual prompt with the visual representation of the data, the researchers hoped to give the LLM a richer understanding of the task and help it perform better.
The researchers compared the performance of the LLM using different multimodal prompting strategies and found that some approaches were more effective than others. This provides valuable insights into how to best leverage multimodal information to enhance the capabilities of LLMs, particularly when working with structured data like tables.
Technical Explanation
The paper explores the use of multimodal prompting strategies to improve the performance of large language models (LLMs) on tabular data tasks. The researchers conduct a comparative analysis to understand how different multimodal prompting approaches, such as combining text with images or tables, affect the LLM's performance on a variety of tabular data tasks.
The study builds on previous research that has highlighted the limitations of LLMs in information-seeking tasks and the potential for enhancing the reasoning capabilities of LLMs through the use of tables. The paper also draws inspiration from works that have explored the benefits of multimodal prompting and the advancement of LLMs in predictive tasks involving tabular data.
The researchers design and implement several multimodal prompting strategies, including text-only, text-image, and text-table prompts, and evaluate their impact on the LLM's performance on a range of tabular data tasks, such as classification, regression, and question-answering. They analyze the results to identify the most effective multimodal prompting approaches and provide insights into the potential of this technique to enhance the capabilities of LLMs when working with structured data.
Critical Analysis
The paper provides a thorough and well-designed exploration of multimodal prompting strategies for LLMs, but there are a few aspects that could be further addressed or explored:
-
Generalizability: While the paper demonstrates the effectiveness of multimodal prompting on the specific tasks and datasets used in the study, it would be valuable to assess the generalizability of these findings to a wider range of tabular data tasks and domains.
-
Architectural Considerations: The paper focuses on the prompting strategies rather than the underlying LLM architecture. Exploring how different LLM architectures (e.g., GPT-3, BERT) might interact with multimodal prompting could provide additional insights.
-
Cognitive Aspects: The paper does not delve into the cognitive mechanisms or reasoning processes that might underlie the observed performance improvements. Incorporating insights from cognitive science or human-AI interaction studies could further enhance the understanding of the benefits of multimodal prompting.
-
Real-world Implications: While the paper highlights the potential of multimodal prompting for enhancing LLM performance on tabular data tasks, it would be valuable to explore the practical implications and challenges of deploying such techniques in real-world applications.
Overall, the paper presents a valuable contribution to the understanding of multimodal prompting strategies and their impact on LLM performance, providing a solid foundation for further research and development in this area.
Conclusion
This paper presents a comparative analysis of multimodal prompting strategies for improving the performance of large language models (LLMs) on tabular data tasks. The researchers explore various approaches that combine text with visual representations, such as images or tables, to provide LLMs with a richer understanding of the task at hand.
The findings suggest that certain multimodal prompting strategies can indeed enhance the capabilities of LLMs when working with structured data, outperforming text-only prompts on a range of tasks. These insights have significant implications for the development of more versatile and effective LLMs, particularly in domains that rely heavily on tabular data, such as finance, healthcare, and scientific research.
By continuing to explore the potential of multimodal prompting, researchers can unlock new possibilities for LLMs to better understand and interact with the world around them, paving the way for more intelligent and impactful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Multimodal Table Understanding
Mingyu Zheng, Xinwei Feng, Qingyi Si, Qiaoqiao She, Zheng Lin, Wenbin Jiang, Weiping Wang
0
0
Although great progress has been made by previous table understanding methods including recent approaches based on large language models (LLMs), they rely heavily on the premise that given tables must be converted into a certain text sequence (such as Markdown or HTML) to serve as model input. However, it is difficult to access such high-quality textual table representations in some real-world scenarios, and table images are much more accessible. Therefore, how to directly understand tables using intuitive visual information is a crucial and urgent challenge for developing more practical applications. In this paper, we propose a new problem, multimodal table understanding, where the model needs to generate correct responses to various table-related requests based on the given table image. To facilitate both the model training and evaluation, we construct a large-scale dataset named MMTab, which covers a wide spectrum of table images, instructions and tasks. On this basis, we develop Table-LLaVA, a generalist tabular multimodal large language model (MLLM), which significantly outperforms recent open-source MLLM baselines on 23 benchmarks under held-in and held-out settings. The code and data is available at this https://github.com/SpursGoZmy/Table-LLaVA
6/13/2024
💬
HeLM: Highlighted Evidence augmented Language Model for Enhanced Table-to-Text Generation
Junyi Bian, Xiaolei Qin, Wuhe Zou, Mengzuo Huang, Congyi Luo, Ke Zhang, Weidong Zhang
0
0
Large models have demonstrated significant progress across various domains, particularly in tasks related to text generation. In the domain of Table to Text, many Large Language Model (LLM)-based methods currently resort to modifying prompts to invoke public APIs, incurring potential costs and information leaks. With the advent of open-source large models, fine-tuning LLMs has become feasible. In this study, we conducted parameter-efficient fine-tuning on the LLaMA2 model. Distinguishing itself from previous fine-tuning-based table-to-text methods, our approach involves injecting reasoning information into the input by emphasizing table-specific row data. Our model consists of two modules: 1) a table reasoner that identifies relevant row evidence, and 2) a table summarizer that generates sentences based on the highlighted table. To facilitate this, we propose a search strategy to construct reasoning labels for training the table reasoner. On both the FetaQA and QTSumm datasets, our approach achieved state-of-the-art results. Additionally, we observed that highlighting input tables significantly enhances the model's performance and provides valuable interpretability.
4/30/2024

Uncovering Limitations of Large Language Models in Information Seeking from Tables
Chaoxu Pang, Yixuan Cao, Chunhao Yang, Ping Luo
0
0
Tables are recognized for their high information density and widespread usage, serving as essential sources of information. Seeking information from tables (TIS) is a crucial capability for Large Language Models (LLMs), serving as the foundation of knowledge-based Q&A systems. However, this field presently suffers from an absence of thorough and reliable evaluation. This paper introduces a more reliable benchmark for Table Information Seeking (TabIS). To avoid the unreliable evaluation caused by text similarity-based metrics, TabIS adopts a single-choice question format (with two options per question) instead of a text generation format. We establish an effective pipeline for generating options, ensuring their difficulty and quality. Experiments conducted on 12 LLMs reveal that while the performance of GPT-4-turbo is marginally satisfactory, both other proprietary and open-source models perform inadequately. Further analysis shows that LLMs exhibit a poor understanding of table structures, and struggle to balance between TIS performance and robustness against pseudo-relevant tables (common in retrieval-augmented systems). These findings uncover the limitations and potential challenges of LLMs in seeking information from tables. We release our data and code to facilitate further research in this field.
6/7/2024
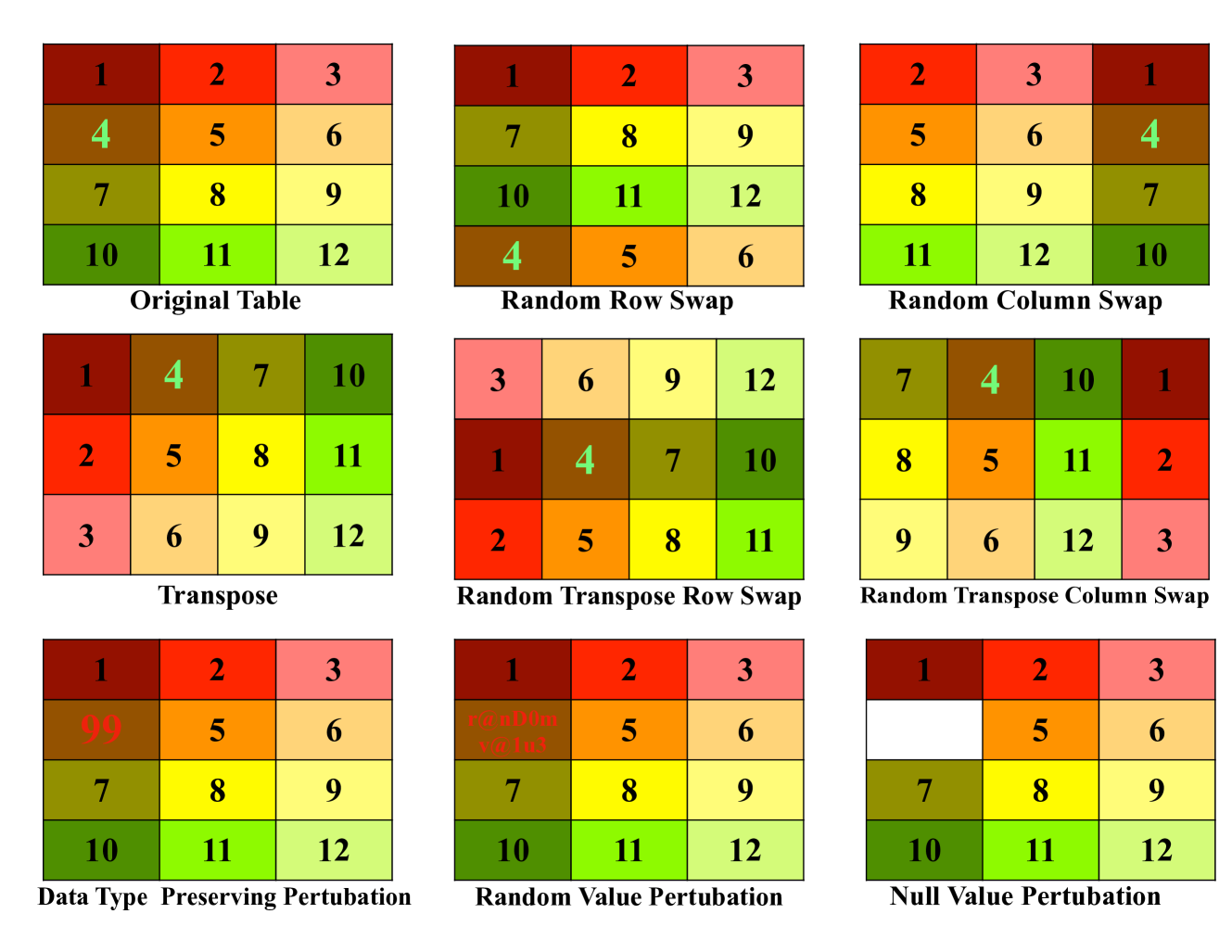
On the Robustness of Language Models for Tabular Question Answering
Kushal Raj Bhandari, Sixue Xing, Soham Dan, Jianxi Gao
0
0
Large Language Models (LLMs), originally shown to ace various text comprehension tasks have also remarkably been shown to tackle table comprehension tasks without specific training. While previous research has explored LLM capabilities with tabular dataset tasks, our study assesses the influence of $textit{in-context learning}$,$ textit{model scale}$, $textit{instruction tuning}$, and $textit{domain biases}$ on Tabular Question Answering (TQA). We evaluate the robustness of LLMs on Wikipedia-based $textbf{WTQ}$ and financial report-based $textbf{TAT-QA}$ TQA datasets, focusing on their ability to robustly interpret tabular data under various augmentations and perturbations. Our findings indicate that instructions significantly enhance performance, with recent models like Llama3 exhibiting greater robustness over earlier versions. However, data contamination and practical reliability issues persist, especially with WTQ. We highlight the need for improved methodologies, including structure-aware self-attention mechanisms and better handling of domain-specific tabular data, to develop more reliable LLMs for table comprehension.
6/19/2024