Not Just Change the Labels, Learn the Features: Watermarking Deep Neural Networks with Multi-View Data

0

Sign in to get full access
Overview
- This paper proposes a novel watermarking technique for deep neural networks that leverages multi-view data, allowing the model to learn unique feature representations that can be used as a watermark.
- The approach aims to provide a secure and robust way to protect against model theft and unauthorized use, without relying solely on modifying the model labels or architecture.
- The researchers demonstrate the effectiveness of their watermarking method through extensive experiments and evaluations.
Plain English Explanation
Deep neural networks have become increasingly valuable and susceptible to theft, as they can be extracted and reused without the original owner's consent. This paper introduces a technique to "watermark" deep neural networks by learning unique feature representations using multi-view data.
The key idea is to provide the model with multiple perspectives or "views" of the same data, such as text and images or different modalities. The model then learns to extract features that are consistent across these views, creating a distinctive "fingerprint" that can be used to identify the model.
This approach is more robust than simply modifying the model labels or architecture, as the watermark is deeply embedded in the model's internal representations. Even if an attacker tries to remove or alter the watermark, the model's performance on the original task would be significantly degraded.
The researchers demonstrate the effectiveness of their watermarking technique through various experiments, showing that it can reliably identify the model's origin, even when the model is transferred to a different task or dataset. This watermarking scheme is designed to be "tattooed" onto the model, making it difficult to remove without compromising the model's functionality.
Technical Explanation
The proposed watermarking technique leverages multi-view data, which provides the deep neural network with multiple perspectives or "views" of the same data. For example, the model may be trained on text and corresponding images or different modalities of the same information.
The key insight is that by learning feature representations that are consistent across these multiple views, the model develops a distinctive "fingerprint" that can be used as a watermark. This watermark is deeply embedded in the model's internal representations, making it difficult for an attacker to remove or alter without significantly degrading the model's performance on the original task.
The researchers design a specialized training procedure that encourages the model to learn these multi-view feature representations. This involves incorporating a contrastive loss function that incentivizes the model to extract common features across the different views, while also maintaining task-specific performance.
Through extensive experiments, the researchers demonstrate that their watermarking approach can reliably identify the model's origin, even when it is transferred to a different task or dataset. They also show that the watermark is resilient to various attack scenarios, such as model fine-tuning or adversarial input manipulation.
Critical Analysis
The proposed watermarking technique represents a promising approach to protecting deep neural networks against theft and unauthorized use. By leveraging multi-view data, the method avoids relying solely on modifying the model labels or architecture, which can be more easily detected or removed by attackers.
However, the technique does have some limitations. It requires access to multi-view data, which may not always be available or feasible to obtain. Additionally, the training process can be computationally intensive, as the model needs to learn feature representations that are consistent across multiple views.
Another potential concern is the impact of the watermarking on the model's performance on the primary task. While the researchers demonstrate that the watermark can be embedded without significant degradation, there may be cases where the watermarking process interferes with the model's optimization, leading to suboptimal performance.
Further research could explore ways to make the watermarking process more efficient and less disruptive to the model's core functionality. Additionally, investigating the long-term stability and resilience of the watermark, as well as its potential impact on model interpretability and explainability, could be valuable areas for future work.
Conclusion
This paper presents a novel watermarking technique for deep neural networks that leverages multi-view data to learn distinctive feature representations as a form of model protection. By embedding the watermark within the model's internal representations, the approach offers a more secure and robust alternative to traditional watermarking methods that rely on modifying the model labels or architecture.
The researchers demonstrate the effectiveness of their technique through extensive experiments, showcasing its ability to reliably identify the model's origin and its resilience to various attack scenarios. While the approach has some limitations, it represents an important step forward in addressing the growing threat of model theft and unauthorized use, which is crucial for safeguarding the significant investments and innovations in the field of deep learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Not Just Change the Labels, Learn the Features: Watermarking Deep Neural Networks with Multi-View Data
Yuxuan Li, Sarthak Kumar Maharana, Yunhui Guo
With the increasing prevalence of Machine Learning as a Service (MLaaS) platforms, there is a growing focus on deep neural network (DNN) watermarking techniques. These methods are used to facilitate the verification of ownership for a target DNN model to protect intellectual property. One of the most widely employed watermarking techniques involves embedding a trigger set into the source model. Unfortunately, existing methodologies based on trigger sets are still susceptible to functionality-stealing attacks, potentially enabling adversaries to steal the functionality of the source model without a reliable means of verifying ownership. In this paper, we first introduce a novel perspective on trigger set-based watermarking methods from a feature learning perspective. Specifically, we demonstrate that by selecting data exhibiting multiple features, also referred to as emph{multi-view data}, it becomes feasible to effectively defend functionality stealing attacks. Based on this perspective, we introduce a novel watermarking technique based on Multi-view dATa, called MAT, for efficiently embedding watermarks within DNNs. This approach involves constructing a trigger set with multi-view data and incorporating a simple feature-based regularization method for training the source model. We validate our method across various benchmarks and demonstrate its efficacy in defending against model extraction attacks, surpassing relevant baselines by a significant margin. The code is available at: href{https://github.com/liyuxuan-github/MAT}{https://github.com/liyuxuan-github/MAT}.
Read more7/19/2024
0
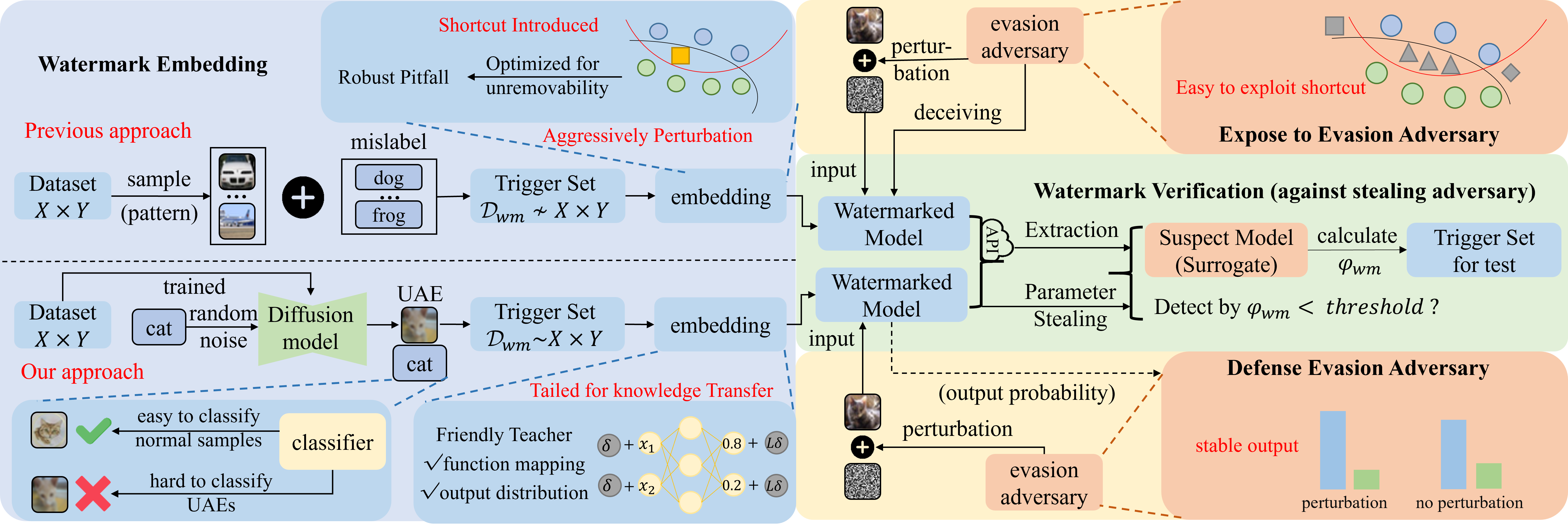
Reliable Model Watermarking: Defending Against Theft without Compromising on Evasion
Hongyu Zhu, Sichu Liang, Wentao Hu, Fangqi Li, Ju Jia, Shilin Wang
With the rise of Machine Learning as a Service (MLaaS) platforms,safeguarding the intellectual property of deep learning models is becoming paramount. Among various protective measures, trigger set watermarking has emerged as a flexible and effective strategy for preventing unauthorized model distribution. However, this paper identifies an inherent flaw in the current paradigm of trigger set watermarking: evasion adversaries can readily exploit the shortcuts created by models memorizing watermark samples that deviate from the main task distribution, significantly impairing their generalization in adversarial settings. To counteract this, we leverage diffusion models to synthesize unrestricted adversarial examples as trigger sets. By learning the model to accurately recognize them, unique watermark behaviors are promoted through knowledge injection rather than error memorization, thus avoiding exploitable shortcuts. Furthermore, we uncover that the resistance of current trigger set watermarking against removal attacks primarily relies on significantly damaging the decision boundaries during embedding, intertwining unremovability with adverse impacts. By optimizing the knowledge transfer properties of protected models, our approach conveys watermark behaviors to extraction surrogates without aggressively decision boundary perturbation. Experimental results on CIFAR-10/100 and Imagenette datasets demonstrate the effectiveness of our method, showing not only improved robustness against evasion adversaries but also superior resistance to watermark removal attacks compared to state-of-the-art solutions.
Read more4/23/2024
0
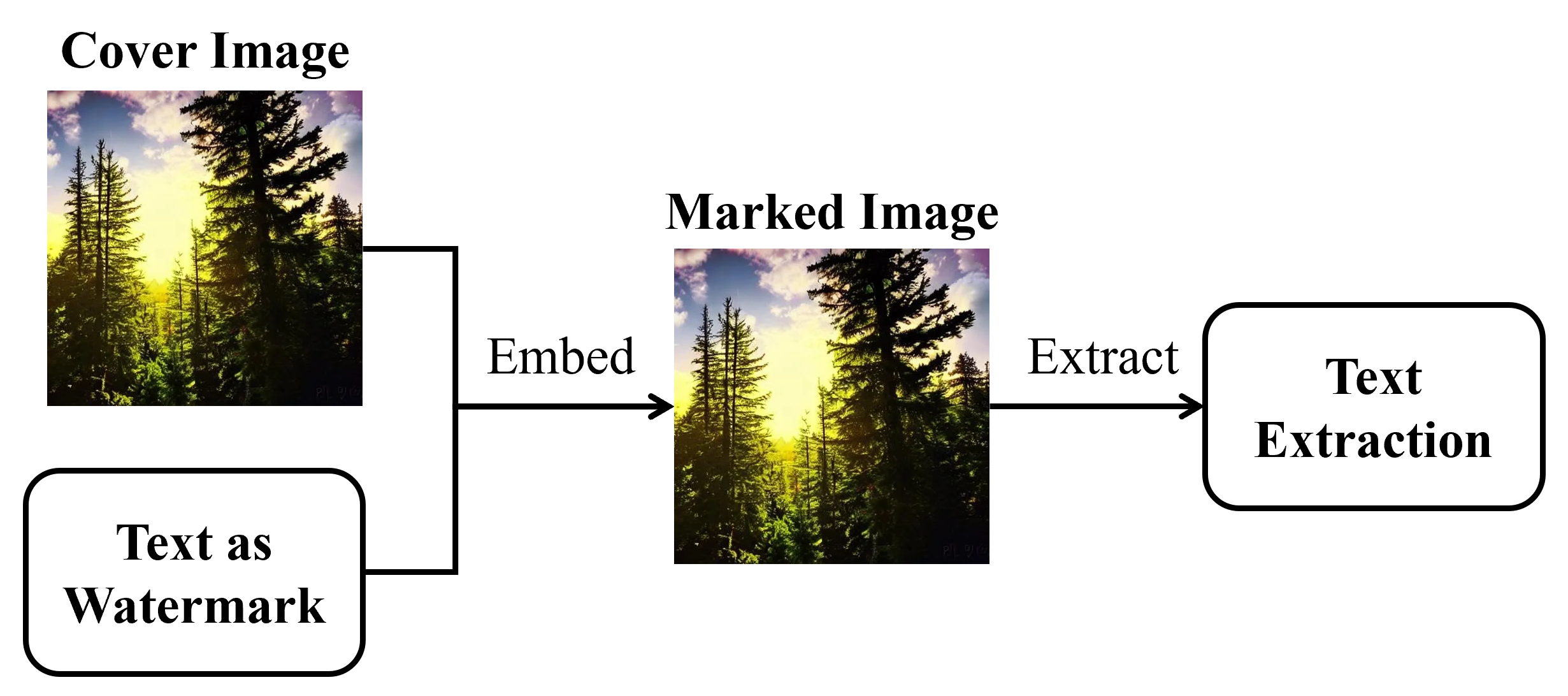
Deep Learning-based Text-in-Image Watermarking
Bishwa Karki, Chun-Hua Tsai, Pei-Chi Huang, Xin Zhong
In this work, we introduce a novel deep learning-based approach to text-in-image watermarking, a method that embeds and extracts textual information within images to enhance data security and integrity. Leveraging the capabilities of deep learning, specifically through the use of Transformer-based architectures for text processing and Vision Transformers for image feature extraction, our method sets new benchmarks in the domain. The proposed method represents the first application of deep learning in text-in-image watermarking that improves adaptivity, allowing the model to intelligently adjust to specific image characteristics and emerging threats. Through testing and evaluation, our method has demonstrated superior robustness compared to traditional watermarking techniques, achieving enhanced imperceptibility that ensures the watermark remains undetectable across various image contents.
Read more4/23/2024
0
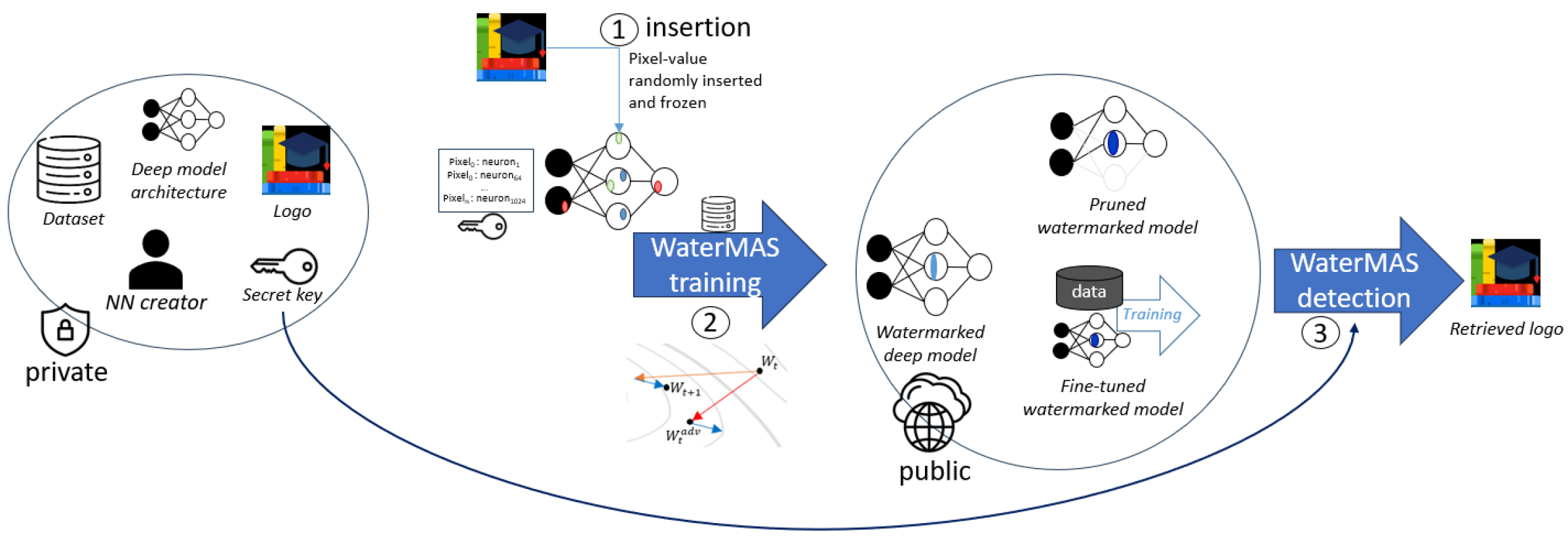
WaterMAS: Sharpness-Aware Maximization for Neural Network Watermarking
Carl De Sousa Trias, Mihai Mitrea, Attilio Fiandrotti, Marco Cagnazzo, Sumanta Chaudhuri, Enzo Tartaglione
Nowadays, deep neural networks are used for solving complex tasks in several critical applications and protecting both their integrity and intellectual property rights (IPR) has become of utmost importance. To this end, we advance WaterMAS, a substitutive, white-box neural network watermarking method that improves the trade-off among robustness, imperceptibility, and computational complexity, while making provisions for increased data payload and security. WasterMAS insertion keeps unchanged the watermarked weights while sharpening their underlying gradient space. The robustness is thus ensured by limiting the attack's strength: even small alterations of the watermarked weights would impact the model's performance. The imperceptibility is ensured by inserting the watermark during the training process. The relationship among the WaterMAS data payload, imperceptibility, and robustness properties is discussed. The secret key is represented by the positions of the weights conveying the watermark, randomly chosen through multiple layers of the model. The security is evaluated by investigating the case in which an attacker would intercept the key. The experimental validations consider 5 models and 2 tasks (VGG16, ResNet18, MobileNetV3, SwinT for CIFAR10 image classification, and DeepLabV3 for Cityscapes image segmentation) as well as 4 types of attacks (Gaussian noise addition, pruning, fine-tuning, and quantization). The code will be released open-source upon acceptance of the article.
Read more9/9/2024