A novel molecule generative model of VAE combined with Transformer for unseen structure generation
2402.11950
0
0
📈
Abstract
Recently, molecule generation using deep learning has been actively investigated in drug discovery. In this field, Transformer and VAE are widely used as powerful models, but they are rarely used in combination due to structural and performance mismatch of them. This study proposes a model that combines these two models through structural and parameter optimization in handling diverse molecules. The proposed model shows comparable performance to existing models in generating molecules, and showed by far superior performance in generating molecules with unseen structures. Another advantage of this VAE model is that it generates molecules from latent representation, and therefore properties of molecules can be easily predicted or conditioned with it, and indeed, we show that the latent representation of the model successfully predicts molecular properties. Ablation study suggested the advantage of VAE over other generative models like language model in generating novel molecules. It also indicated that the latent representation can be shortened to ~32 dimensional variables without loss of reconstruction, suggesting the possibility of a much smaller molecular descriptor or model than existing ones. This study is expected to provide a virtual chemical library containing a wide variety of compounds for virtual screening and to enable efficient screening.
Create account to get full access
Overview
- Recent advancements in deep learning have enabled the generation of molecules for drug discovery
- Transformer and Variational Autoencoder (VAE) models are widely used, but are rarely combined due to compatibility issues
- This study proposes a model that bridges the gap between Transformer and VAE models to generate diverse molecules with superior performance
Plain English Explanation
The paper describes a novel approach to generating molecules using deep learning. Researchers in drug discovery often use Transformer and Variational Autoencoder (VAE) models, which are powerful but have compatibility issues when used together.
The proposed model cleverly combines these two types of models through structural and parameter optimization. This allows the model to generate a wider variety of molecules, including those with novel structures that existing models struggle with.
One key advantage of the VAE-based approach is that it generates molecules from a low-dimensional "latent" representation. This makes it easy to predict the properties of the generated molecules or condition the generation process on desired properties. The researchers show that the latent representation can effectively predict molecular properties.
Compared to other generative models like language models, the VAE-based approach demonstrates clear advantages in generating truly novel molecules. The researchers also find that the latent representation can be compressed to just ~32 dimensions without losing reconstruction quality, suggesting the possibility of much more compact molecular representations than existing ones.
This work is expected to enable the creation of virtual chemical libraries with diverse compounds, which can then be efficiently screened for drug discovery applications. The proposed model represents an important advance in the field of deep learning-driven molecular generation.
Technical Explanation
The paper presents a novel model that combines the strengths of Transformer and Variational Autoencoder (VAE) architectures to generate diverse and high-quality molecules for drug discovery.
The researchers first identify the structural and performance mismatch between Transformer and VAE models that has traditionally hindered their combined use. To address this, they propose a model that optimizes the architecture and parameters to bridge the gap between the two approaches.
The key innovations of the proposed model include:
- Careful design of the encoder and decoder components to enable effective information flow between the Transformer and VAE sub-modules
- Parameter sharing and joint optimization of the Transformer and VAE components
Experiments show that this combined model achieves comparable performance to state-of-the-art models in generating diverse molecules. Crucially, it demonstrates far superior performance in generating molecules with unseen structural features, a key challenge in this domain.
The VAE-based nature of the model also provides additional benefits. The low-dimensional latent representation learned by the VAE can effectively predict molecular properties, as the researchers demonstrate. This enables efficient screening and optimization of molecules based on desired characteristics.
Ablation studies further reveal the advantages of the VAE approach over alternative generative models like language models in producing truly novel molecular structures. The researchers also find that the latent representation can be compressed to just ~32 dimensions without compromising reconstruction quality, suggesting the potential for much more compact molecular descriptors.
Critical Analysis
The paper presents a well-designed and thorough study that addresses an important challenge in the field of deep learning-based molecular generation. The proposed model represents a significant technical advance, bridging the gap between two widely used but incompatible model architectures.
However, the paper does not discuss certain limitations or potential issues with the approach. For example, it is unclear how the model would scale to handle an even larger and more diverse set of molecules, or how it would perform on more complex molecular properties beyond the ones tested.
Additionally, while the researchers demonstrate the advantages of the VAE-based approach, they do not provide a deep analysis of why the VAE model outperforms alternatives like language models in generating novel molecules. A more detailed examination of the underlying reasons could yield additional insights.
Further research could also explore ways to leverage large pre-trained language and vision models to enhance the molecular generation capabilities of the proposed model, building on the strengths of multiple deep learning techniques.
Overall, the paper makes a valuable contribution to the field and the proposed model represents an important step forward. However, there are opportunities to delve deeper into the model's limitations and potential future directions to further advance the state of the art in deep learning-driven molecular generation.
Conclusion
This paper presents a novel deep learning model that combines Transformer and Variational Autoencoder (VAE) architectures to generate diverse and high-quality molecules for drug discovery. The key innovation is the structural and parameter optimization that allows these two powerful but historically incompatible models to work together effectively.
The resulting model demonstrates comparable performance to existing state-of-the-art approaches in generating diverse molecules, while showing far superior capability in generating molecules with unseen structural features. The VAE-based nature of the model also provides additional benefits, such as the ability to easily predict molecular properties from the learned latent representation.
Ablation studies and further analysis reveal the advantages of the VAE approach over alternative generative models, as well as the potential for even more compact molecular representations. This work is expected to enable the creation of virtual chemical libraries with diverse compounds, facilitating more efficient and effective drug discovery through virtual screening.
Overall, this paper represents an important advancement in the field of deep learning-driven molecular generation, paving the way for further innovations in this critical area of drug discovery research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
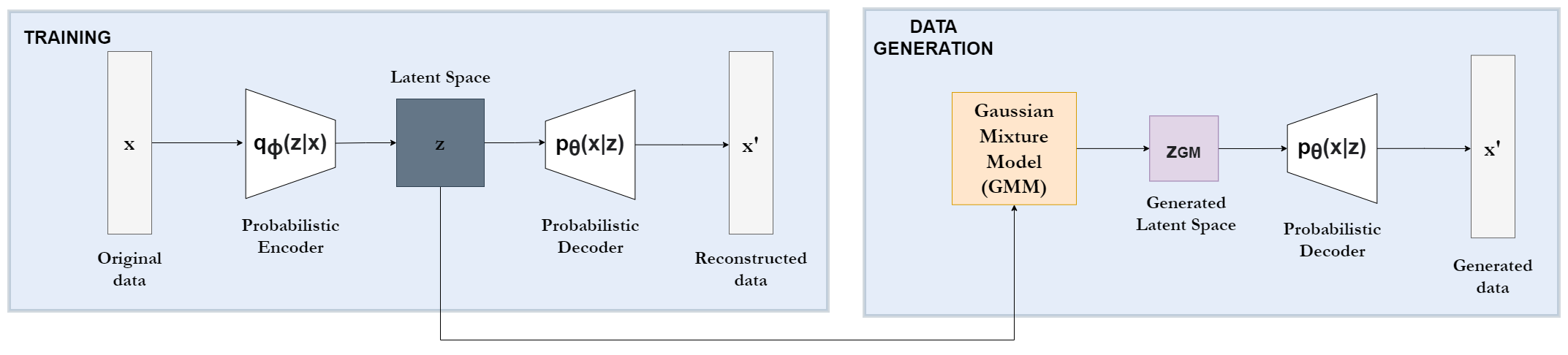
An improved tabular data generator with VAE-GMM integration
Patricia A. Apell'aniz, Juan Parras, Santiago Zazo
0
0
The rising use of machine learning in various fields requires robust methods to create synthetic tabular data. Data should preserve key characteristics while addressing data scarcity challenges. Current approaches based on Generative Adversarial Networks, such as the state-of-the-art CTGAN model, struggle with the complex structures inherent in tabular data. These data often contain both continuous and discrete features with non-Gaussian distributions. Therefore, we propose a novel Variational Autoencoder (VAE)-based model that addresses these limitations. Inspired by the TVAE model, our approach incorporates a Bayesian Gaussian Mixture model (BGM) within the VAE architecture. This avoids the limitations imposed by assuming a strictly Gaussian latent space, allowing for a more accurate representation of the underlying data distribution during data generation. Furthermore, our model offers enhanced flexibility by allowing the use of various differentiable distributions for individual features, making it possible to handle both continuous and discrete data types. We thoroughly validate our model on three real-world datasets with mixed data types, including two medically relevant ones, based on their resemblance and utility. This evaluation demonstrates significant outperformance against CTGAN and TVAE, establishing its potential as a valuable tool for generating synthetic tabular data in various domains, particularly in healthcare.
4/15/2024

Enhancing Generative Molecular Design via Uncertainty-guided Fine-tuning of Variational Autoencoders
A N M Nafiz Abeer, Sanket Jantre, Nathan M Urban, Byung-Jun Yoon
0
0
In recent years, deep generative models have been successfully adopted for various molecular design tasks, particularly in the life and material sciences. A critical challenge for pre-trained generative molecular design (GMD) models is to fine-tune them to be better suited for downstream design tasks aimed at optimizing specific molecular properties. However, redesigning and training an existing effective generative model from scratch for each new design task is impractical. Furthermore, the black-box nature of typical downstream tasks$unicode{x2013}$such as property prediction$unicode{x2013}$makes it nontrivial to optimize the generative model in a task-specific manner. In this work, we propose a novel approach for a model uncertainty-guided fine-tuning of a pre-trained variational autoencoder (VAE)-based GMD model through performance feedback in an active learning setting. The main idea is to quantify model uncertainty in the generative model, which is made efficient by working within a low-dimensional active subspace of the high-dimensional VAE parameters explaining most of the variability in the model's output. The inclusion of model uncertainty expands the space of viable molecules through decoder diversity. We then explore the resulting model uncertainty class via black-box optimization made tractable by low-dimensionality of the active subspace. This enables us to identify and leverage a diverse set of high-performing models to generate enhanced molecules. Empirical results across six target molecular properties, using multiple VAE-based generative models, demonstrate that our uncertainty-guided fine-tuning approach consistently outperforms the original pre-trained models.
6/3/2024
🛠️
Human-level molecular optimization driven by mol-gene evolution
Jiebin Fang (Hainan Institute of Zhejiang University, Institute of Marine Biology and Pharmacology, Ocean College, Zhejiang University), Churu Mao (Institute of Marine Biology and Pharmacology, Ocean College, Zhejiang University), Yuchen Zhu (College of Pharmaceutical Sciences and Cancer Center, Zhejiang University), Xiaoming Chen (Institute of Marine Biology and Pharmacology, Ocean College, Zhejiang University), Chang-Yu Hsieh (College of Pharmaceutical Sciences and Cancer Center, Zhejiang University), Zhongjun Ma (Hainan Institute of Zhejiang University, Institute of Marine Biology and Pharmacology, Ocean College, Zhejiang University)
0
0
De novo molecule generation allows the search for more drug-like hits across a vast chemical space. However, lead optimization is still required, and the process of optimizing molecular structures faces the challenge of balancing structural novelty with pharmacological properties. This study introduces the Deep Genetic Molecular Modification Algorithm (DGMM), which brings structure modification to the level of medicinal chemists. A discrete variational autoencoder (D-VAE) is used in DGMM to encode molecules as quantization code, mol-gene, which incorporates deep learning into genetic algorithms for flexible structural optimization. The mol-gene allows for the discovery of pharmacologically similar but structurally distinct compounds, and reveals the trade-offs of structural optimization in drug discovery. We demonstrate the effectiveness of the DGMM in several applications.
6/21/2024
Explainable Molecular Property Prediction: Aligning Chemical Concepts with Predictions via Language Models
Zhenzhong Wang, Zehui Lin, Wanyu Lin, Ming Yang, Minggang Zeng, Kay Chen Tan
0
0
Providing explainable molecule property predictions is critical for many scientific domains, such as drug discovery and material science. Though transformer-based language models have shown great potential in accurate molecular property prediction, they neither provide chemically meaningful explanations nor faithfully reveal the molecular structure-property relationships. In this work, we develop a new framework for explainable molecular property prediction based on language models, dubbed as Lamole, which can provide chemical concepts-aligned explanations. We first leverage a designated molecular representation -- the Group SELFIES -- as it can provide chemically meaningful semantics. Because attention mechanisms in Transformers can inherently capture relationships within the input, we further incorporate the attention weights and gradients together to generate explanations for capturing the functional group interactions. We then carefully craft a marginal loss to explicitly optimize the explanations to be able to align with the chemists' annotations. We bridge the manifold hypothesis with the elaborated marginal loss to prove that the loss can align the explanations with the tangent space of the data manifold, leading to concept-aligned explanations. Experimental results over six mutagenicity datasets and one hepatotoxicity dataset demonstrate Lamole can achieve comparable classification accuracy and boost the explanation accuracy by up to 14.8%, being the state-of-the-art in explainable molecular property prediction.
6/4/2024