Transformers for molecular property prediction: Lessons learned from the past five years
2404.03969
0
0

Abstract
Molecular Property Prediction (MPP) is vital for drug discovery, crop protection, and environmental science. Over the last decades, diverse computational techniques have been developed, from using simple physical and chemical properties and molecular fingerprints in statistical models and classical machine learning to advanced deep learning approaches. In this review, we aim to distill insights from current research on employing transformer models for MPP. We analyze the currently available models and explore key questions that arise when training and fine-tuning a transformer model for MPP. These questions encompass the choice and scale of the pre-training data, optimal architecture selections, and promising pre-training objectives. Our analysis highlights areas not yet covered in current research, inviting further exploration to enhance the field's understanding. Additionally, we address the challenges in comparing different models, emphasizing the need for standardized data splitting and robust statistical analysis.
Create account to get full access
Overview
- This paper presents a detailed technical explanation of transformer models, a type of deep learning architecture that has revolutionized natural language processing and other AI applications.
- The paper covers the core principles behind how transformer models work, their key architectural components, and the insights they have provided for understanding attention mechanisms in neural networks.
- The authors also discuss several real-world applications of transformer models, including attending to graph transformers, novel molecule generative models, generative software engineering, and mapping attention mechanisms to generalized Potts models.
Plain English Explanation
Transformer models are a type of artificial intelligence that has become very popular in recent years. They are particularly good at understanding and generating human language, but they can also be used for other tasks like generating new software code or designing new molecules.
The key idea behind transformer models is that they use an "attention" mechanism to focus on the most important parts of the input when processing it. This is kind of like how humans pay attention to certain words or phrases when trying to understand what someone is saying. Transformers can learn to do this automatically, without being explicitly programmed.
Transformer models have been used for all sorts of applications, from translating between languages to analyzing complex networks and graphs. They have proven to be very powerful and flexible, and researchers are continuing to find new and innovative ways to use them.
Technical Explanation
Transformer models are a type of deep learning architecture that have become widely used in natural language processing and other AI applications. At a high level, transformers work by using an "attention" mechanism to selectively focus on the most relevant parts of the input when processing it.
The core architecture of a transformer model consists of several key components:
- An encoder that takes the input (e.g. a sentence) and produces a set of internal representations
- A decoder that generates the output (e.g. a translation or summary) based on those representations
- Multiple "attention" layers that allow the model to focus on the most important parts of the input when producing the output
The attention mechanism works by learning a set of weights that determine how much each part of the input should contribute to the output. This allows the model to dynamically focus on the most relevant information, rather than treating all parts of the input equally.
Transformers have been applied to a wide range of problems, from generating new software code to designing novel molecules. The key benefits of transformers are their ability to capture long-range dependencies, their parallelizability, and their flexibility in handling various types of data.
Critical Analysis
The paper provides a comprehensive technical overview of transformer models, highlighting their key architectural components and the insights they have provided for understanding attention mechanisms in neural networks. However, the authors do acknowledge several important caveats and limitations:
- Transformer models can be computationally expensive and require large amounts of training data, which may limit their applicability in certain real-world scenarios.
- The attention mechanism, while powerful, is not fully understood, and there are open questions about how it relates to human attention and cognition.
- Transformer models can be vulnerable to adversarial attacks and biases in their training data, which can lead to unintended behaviors or outputs.
Additionally, while the paper covers several impressive applications of transformer models, it does not delve into potential ethical or societal implications of these technologies. As transformer models become more powerful and ubiquitous, it will be important for researchers and practitioners to carefully consider the broader impacts and responsible development of these systems.
Conclusion
In summary, this paper provides a detailed technical overview of transformer models, a powerful deep learning architecture that has revolutionized natural language processing and other AI applications. The authors explain the core principles behind how transformers work, their key architectural components, and the insights they have provided for understanding attention mechanisms in neural networks.
The paper also highlights several real-world applications of transformer models, demonstrating their flexibility and versatility. While there are important caveats and limitations to consider, the continued development and refinement of transformer models is likely to have significant implications for a wide range of industries and domains, from software engineering to drug discovery. As such, the insights and principles outlined in this paper will be valuable for both researchers and practitioners working in the field of AI and machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Transfer Learning for Molecular Property Predictions from Small Data Sets
Thorren Kirschbaum, Annika Bande
0
0
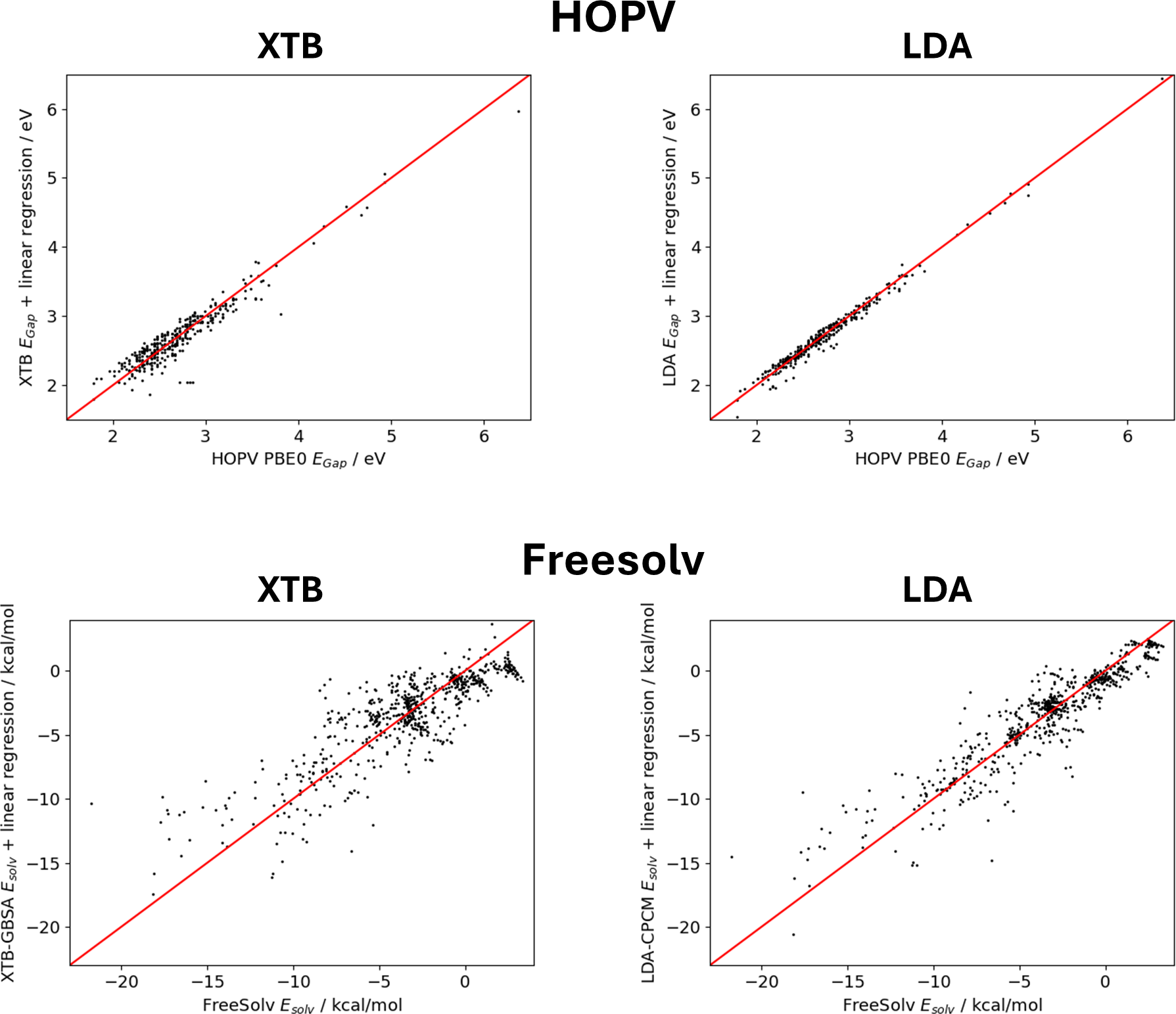
Machine learning has emerged as a new tool in chemistry to bypass expensive experiments or quantum-chemical calculations, for example, in high-throughput screening applications. However, many machine learning studies rely on small data sets, making it difficult to efficiently implement powerful deep learning architectures such as message passing neural networks. In this study, we benchmark common machine learning models for the prediction of molecular properties on small data sets, for which the best results are obtained with the message passing neural network PaiNN, as well as SOAP molecular descriptors concatenated to a set of simple molecular descriptors tailored to gradient boosting with regression trees. To further improve the predictive capabilities of PaiNN, we present a transfer learning strategy that uses large data sets to pre-train the respective models and allows to obtain more accurate models after fine-tuning on the original data sets. The pre-training labels are obtained from computationally cheap ab initio or semi-empirical models and corrected by simple linear regression on the target data set to obtain labels that are close to those of the original data. This strategy is tested on the Harvard Oxford Photovoltaics data set (HOPV, HOMO-LUMO-gaps), for which excellent results are obtained, and on the Freesolv data set (solvation energies), where this method is unsuccessful due to a complex underlying learning task and the dissimilar methods used to obtain pre-training and fine-tuning labels. Finally, we find that the final training results do not improve monotonically with the size of the pre-training data set, but pre-training with fewer data points can lead to more biased pre-trained models and higher accuracy after fine-tuning.
4/23/2024

MolecularGPT: Open Large Language Model (LLM) for Few-Shot Molecular Property Prediction
Yuyan Liu, Sirui Ding, Sheng Zhou, Wenqi Fan, Qiaoyu Tan
0
0
Molecular property prediction (MPP) is a fundamental and crucial task in drug discovery. However, prior methods are limited by the requirement for a large number of labeled molecules and their restricted ability to generalize for unseen and new tasks, both of which are essential for real-world applications. To address these challenges, we present MolecularGPT for few-shot MPP. From a perspective on instruction tuning, we fine-tune large language models (LLMs) based on curated molecular instructions spanning over 1000 property prediction tasks. This enables building a versatile and specialized LLM that can be adapted to novel MPP tasks without any fine-tuning through zero- and few-shot in-context learning (ICL). MolecularGPT exhibits competitive in-context reasoning capabilities across 10 downstream evaluation datasets, setting new benchmarks for few-shot molecular prediction tasks. More importantly, with just two-shot examples, MolecularGPT can outperform standard supervised graph neural network methods on 4 out of 7 datasets. It also excels state-of-the-art LLM baselines by up to 16.6% increase on classification accuracy and decrease of 199.17 on regression metrics (e.g., RMSE) under zero-shot. This study demonstrates the potential of LLMs as effective few-shot molecular property predictors. The code is available at https://github.com/NYUSHCS/MolecularGPT.
6/21/2024

New!Impact of Domain Knowledge and Multi-Modality on Intelligent Molecular Property Prediction: A Systematic Survey
Taojie Kuang, Pengfei Liu, Zhixiang Ren
0
0
The precise prediction of molecular properties is essential for advancements in drug development, particularly in virtual screening and compound optimization. The recent introduction of numerous deep learning-based methods has shown remarkable potential in enhancing molecular property prediction (MPP), especially improving accuracy and insights into molecular structures. Yet, two critical questions arise: does the integration of domain knowledge augment the accuracy of molecular property prediction and does employing multi-modal data fusion yield more precise results than unique data source methods? To explore these matters, we comprehensively review and quantitatively analyze recent deep learning methods based on various benchmarks. We discover that integrating molecular information significantly improves molecular property prediction (MPP) for both regression and classification tasks. Specifically, regression improvements, measured by reductions in root mean square error (RMSE), are up to 4.0%, while classification enhancements, measured by the area under the receiver operating characteristic curve (ROC-AUC), are up to 1.7%. We also discover that enriching 2D graphs with 1D SMILES boosts multi-modal learning performance for regression tasks by up to 9.1%, and augmenting 2D graphs with 3D information increases performance for classification tasks by up to 13.2%, with both enhancements measured using ROC-AUC. The two consolidated insights offer crucial guidance for future advancements in drug discovery.
7/1/2024
Explainable Molecular Property Prediction: Aligning Chemical Concepts with Predictions via Language Models
Zhenzhong Wang, Zehui Lin, Wanyu Lin, Ming Yang, Minggang Zeng, Kay Chen Tan
0
0
Providing explainable molecule property predictions is critical for many scientific domains, such as drug discovery and material science. Though transformer-based language models have shown great potential in accurate molecular property prediction, they neither provide chemically meaningful explanations nor faithfully reveal the molecular structure-property relationships. In this work, we develop a new framework for explainable molecular property prediction based on language models, dubbed as Lamole, which can provide chemical concepts-aligned explanations. We first leverage a designated molecular representation -- the Group SELFIES -- as it can provide chemically meaningful semantics. Because attention mechanisms in Transformers can inherently capture relationships within the input, we further incorporate the attention weights and gradients together to generate explanations for capturing the functional group interactions. We then carefully craft a marginal loss to explicitly optimize the explanations to be able to align with the chemists' annotations. We bridge the manifold hypothesis with the elaborated marginal loss to prove that the loss can align the explanations with the tangent space of the data manifold, leading to concept-aligned explanations. Experimental results over six mutagenicity datasets and one hepatotoxicity dataset demonstrate Lamole can achieve comparable classification accuracy and boost the explanation accuracy by up to 14.8%, being the state-of-the-art in explainable molecular property prediction.
6/4/2024