An Offline Adaptation Framework for Constrained Multi-Objective Reinforcement Learning

0

Sign in to get full access
Overview
- Presents an offline adaptation framework for constrained multi-objective reinforcement learning (CMRL)
- Addresses the challenge of balancing multiple, potentially conflicting objectives in reinforcement learning (RL) tasks
- Proposes a novel algorithm to learn a diverse set of policies that satisfy given constraints
Plain English Explanation
The research paper introduces an offline adaptation framework for constrained multi-objective reinforcement learning (CMRL). In many real-world scenarios, AI systems need to balance multiple, potentially conflicting objectives, such as maximizing reward while minimizing cost or risk. This is known as the constrained multi-objective reinforcement learning (CMRL) problem.
The key idea is to learn a diverse set of policies that can satisfy the given constraints, rather than trying to find a single optimal solution. This allows the system to adapt to different user preferences or environmental conditions by selecting the appropriate policy. The proposed offline adaptation framework leverages existing offline RL techniques to efficiently explore the policy space and discover a set of high-performing, diverse policies.
By taking an offline approach, the framework can learn from previously collected data without requiring additional interactions with the environment, which can be costly or dangerous in many real-world applications. The framework also includes a novel algorithm to discover multiple solutions from a single task, further enhancing the diversity of the learned policies.
Overall, the offline adaptation framework for CMRL aims to enable AI systems to optimize human-centric objectives by providing them with a diverse set of adaptable policies that can balance multiple, sometimes conflicting goals.
Technical Explanation
The paper proposes an offline adaptation framework for solving constrained multi-objective reinforcement learning (CMRL) problems. The key components of the framework include:
-
Offline Data Collection: The framework leverages previously collected offline data, which can be obtained from expert demonstrations, previous interactions with the environment, or a combination of both.
-
Policy Parameterization: The framework represents policies using a flexible, multi-head neural network architecture, where each head corresponds to a different objective or constraint.
-
Diversity-Promoting Exploration: The framework employs a novel algorithm to discover multiple solutions from a single task, encouraging the exploration of diverse policies that satisfy the given constraints.
-
Offline Adaptation: During the training process, the framework optimizes the policy parameters to maximize the cumulative reward while satisfying the constraints. The resulting set of diverse policies can then be adapted to different user preferences or environmental conditions.
The paper evaluates the proposed framework on several simulated constrained multi-objective reinforcement learning tasks, demonstrating its ability to learn a diverse set of high-performing policies that can satisfy the given constraints.
Critical Analysis
The research paper presents a novel and promising approach to addressing the constrained multi-objective reinforcement learning (CMRL) problem. The key strengths of the proposed offline adaptation framework include its ability to learn a diverse set of policies from offline data and its potential to enable AI systems to optimize human-centric objectives.
However, the paper also acknowledges several limitations and areas for further research:
-
Scalability: The framework's performance on more complex, high-dimensional tasks is not evaluated, and its scalability to real-world applications may be a concern.
-
Constraint Handling: The paper focuses on satisfying hard constraints, but in many practical scenarios, soft constraints or preferences may be more appropriate. Extending the framework to handle such cases could be a valuable direction for future work.
-
Generalization: The paper does not explicitly address the issue of how well the learned policies can generalize to new environments or user preferences. Investigating the framework's ability to adapt to such changes would be an important area for further research.
-
Interpretability: While the multi-head policy representation provides some degree of interpretability, the paper does not explore methods to enhance the transparency and explainability of the learned policies, which could be crucial for building trust in real-world applications.
Overall, the offline adaptation framework for CMRL represents a promising step towards enabling AI systems to optimize human-centric objectives in complex, constrained environments. Addressing the identified limitations and exploring further extensions could help unlock the full potential of this approach.
Conclusion
The research paper presents an offline adaptation framework for constrained multi-objective reinforcement learning (CMRL), which aims to address the challenge of balancing multiple, potentially conflicting objectives in reinforcement learning tasks. By leveraging offline RL techniques and a novel algorithm for discovering multiple solutions from a single task, the framework can learn a diverse set of adaptable policies that satisfy given constraints.
The proposed approach has the potential to enable AI systems to optimize human-centric objectives in complex, real-world scenarios by providing them with a range of high-performing policies that can be selected based on user preferences or environmental conditions. While the paper identifies several limitations and areas for further research, the offline adaptation framework for CMRL represents a promising step towards more versatile and adaptable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Offline Adaptation Framework for Constrained Multi-Objective Reinforcement Learning
Qian Lin, Zongkai Liu, Danying Mo, Chao Yu
In recent years, significant progress has been made in multi-objective reinforcement learning (RL) research, which aims to balance multiple objectives by incorporating preferences for each objective. In most existing studies, specific preferences must be provided during deployment to indicate the desired policies explicitly. However, designing these preferences depends heavily on human prior knowledge, which is typically obtained through extensive observation of high-performing demonstrations with expected behaviors. In this work, we propose a simple yet effective offline adaptation framework for multi-objective RL problems without assuming handcrafted target preferences, but only given several demonstrations to implicitly indicate the preferences of expected policies. Additionally, we demonstrate that our framework can naturally be extended to meet constraints on safety-critical objectives by utilizing safe demonstrations, even when the safety thresholds are unknown. Empirical results on offline multi-objective and safe tasks demonstrate the capability of our framework to infer policies that align with real preferences while meeting the constraints implied by the provided demonstrations.
Read more9/17/2024
0
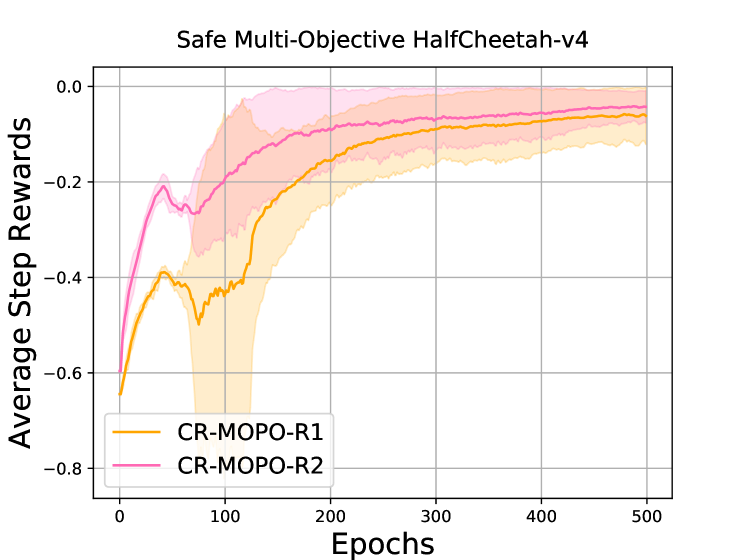
Safe and Balanced: A Framework for Constrained Multi-Objective Reinforcement Learning
Shangding Gu, Bilgehan Sel, Yuhao Ding, Lu Wang, Qingwei Lin, Alois Knoll, Ming Jin
In numerous reinforcement learning (RL) problems involving safety-critical systems, a key challenge lies in balancing multiple objectives while simultaneously meeting all stringent safety constraints. To tackle this issue, we propose a primal-based framework that orchestrates policy optimization between multi-objective learning and constraint adherence. Our method employs a novel natural policy gradient manipulation method to optimize multiple RL objectives and overcome conflicting gradients between different tasks, since the simple weighted average gradient direction may not be beneficial for specific tasks' performance due to misaligned gradients of different task objectives. When there is a violation of a hard constraint, our algorithm steps in to rectify the policy to minimize this violation. We establish theoretical convergence and constraint violation guarantees in a tabular setting. Empirically, our proposed method also outperforms prior state-of-the-art methods on challenging safe multi-objective reinforcement learning tasks.
Read more5/28/2024
0
Preference Elicitation for Offline Reinforcement Learning
Aliz'ee Pace, Bernhard Scholkopf, Gunnar Ratsch, Giorgia Ramponi
Applying reinforcement learning (RL) to real-world problems is often made challenging by the inability to interact with the environment and the difficulty of designing reward functions. Offline RL addresses the first challenge by considering access to an offline dataset of environment interactions labeled by the reward function. In contrast, Preference-based RL does not assume access to the reward function and learns it from preferences, but typically requires an online interaction with the environment. We bridge the gap between these frameworks by exploring efficient methods for acquiring preference feedback in a fully offline setup. We propose Sim-OPRL, an offline preference-based reinforcement learning algorithm, which leverages a learned environment model to elicit preference feedback on simulated rollouts. Drawing on insights from both the offline RL and the preference-based RL literature, our algorithm employs a pessimistic approach for out-of-distribution data, and an optimistic approach for acquiring informative preferences about the optimal policy. We provide theoretical guarantees regarding the sample complexity of our approach, dependent on how well the offline data covers the optimal policy. Finally, we demonstrate the empirical performance of Sim-OPRL in different environments.
Read more6/27/2024
0
Discovering Multiple Solutions from a Single Task in Offline Reinforcement Learning
Takayuki Osa, Tatsuya Harada
Recent studies on online reinforcement learning (RL) have demonstrated the advantages of learning multiple behaviors from a single task, as in the case of few-shot adaptation to a new environment. Although this approach is expected to yield similar benefits in offline RL, appropriate methods for learning multiple solutions have not been fully investigated in previous studies. In this study, we therefore addressed the problem of finding multiple solutions from a single task in offline RL. We propose algorithms that can learn multiple solutions in offline RL, and empirically investigate their performance. Our experimental results show that the proposed algorithm learns multiple qualitatively and quantitatively distinctive solutions in offline RL.
Read more6/11/2024