Offline and Distributional Reinforcement Learning for Radio Resource Management

0

Sign in to get full access
Overview
- Offline and distributional reinforcement learning for radio resource management
- Focuses on using offline (pre-collected) data and distributional RL to optimize radio resource allocation
- Aims to improve efficiency and performance of wireless communication systems
Plain English Explanation
The paper explores using [object Object] and [object Object] techniques to manage radio resources in wireless communication systems.
In traditional reinforcement learning, an agent learns by interacting with an environment and receiving rewards. However, in many real-world scenarios, it may be difficult or expensive to collect this interactive data. Offline reinforcement learning allows the agent to learn from pre-collected, historical data without needing to explore the environment directly.
[object Object] goes a step further by modeling the entire distribution of possible rewards, rather than just the expected value. This can provide a richer understanding of the environment and lead to better decision-making.
The researchers apply these techniques to the problem of radio resource management - determining how to allocate limited radio resources like frequency bands, time slots, and transmission power to maximize the performance of a wireless system. By learning from offline data, the system can optimize resource allocation without the need for extensive real-world experimentation, which is costly and disruptive.
Technical Explanation
The paper proposes an [object Object] framework for radio resource management, where the agent learns a policy for allocating resources based on pre-collected data rather than direct interaction.
The key elements of the framework include:
-
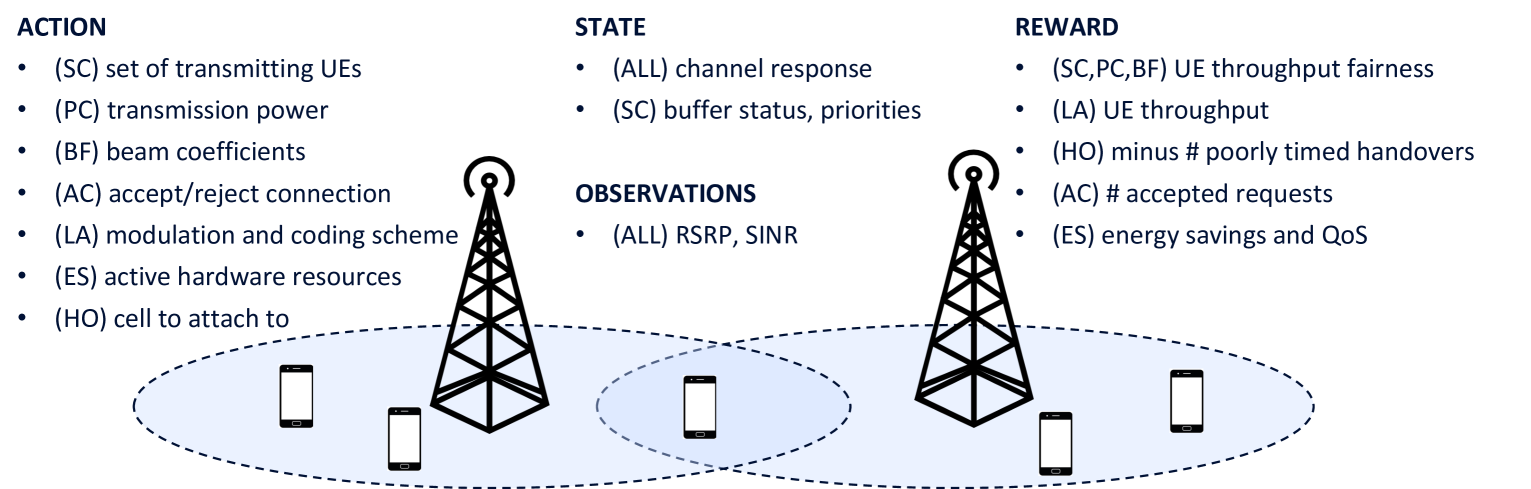
System Model: The researchers model a wireless communication system with multiple users, each with their own resource requirements and channel conditions.
-
Offline Dataset: Instead of interacting with the live system, the agent learns from a pre-collected dataset of past system states, actions, and rewards.
-
Distributional Reinforcement Learning: Rather than estimating just the expected reward, the agent models the entire distribution of possible rewards. This provides a richer understanding of the system dynamics.
-
Optimization Algorithm: The researchers develop a novel optimization algorithm that can efficiently learn an optimal resource allocation policy from the offline dataset and distributional reward model.
Through extensive simulations, the authors demonstrate that their offline, distributional RL approach outperforms traditional online RL and heuristic resource allocation schemes, achieving higher system throughput and lower latency.
Critical Analysis
The paper makes a strong case for the benefits of offline and distributional RL in the context of radio resource management. By leveraging pre-collected data, the system can be optimized without the need for disruptive real-world experimentation, which is a significant practical advantage.
However, the authors note that the offline dataset must be sufficiently representative of the system's operating conditions for the learned policy to generalize well. Additionally, the distributional RL approach adds additional computational complexity that may be a limitation in some real-time applications.
Further research could explore techniques to [object Object] from the offline data, as well as methods to [object Object] to better align with the desired system objectives.
Conclusion
This paper demonstrates the potential of offline and distributional reinforcement learning for optimizing radio resource management in wireless communication systems. By learning from pre-collected data and modeling the full reward distribution, the proposed framework can improve the efficiency and performance of these critical infrastructure systems without the need for extensive real-world experimentation.
The insights from this research could have broader implications for applying advanced RL techniques to other resource allocation problems in various industries, reducing the barriers to adoption and enabling more effective optimization.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Offline and Distributional Reinforcement Learning for Radio Resource Management
Eslam Eldeeb, Hirley Alves
Reinforcement learning (RL) has proved to have a promising role in future intelligent wireless networks. Online RL has been adopted for radio resource management (RRM), taking over traditional schemes. However, due to its reliance on online interaction with the environment, its role becomes limited in practical, real-world problems where online interaction is not feasible. In addition, traditional RL stands short in front of the uncertainties and risks in real-world stochastic environments. In this manner, we propose an offline and distributional RL scheme for the RRM problem, enabling offline training using a static dataset without any interaction with the environment and considering the sources of uncertainties using the distributions of the return. Simulation results demonstrate that the proposed scheme outperforms conventional resource management models. In addition, it is the only scheme that surpasses online RL and achieves a $16 %$ gain over online RL.
Read more9/26/2024
0
To RL or not to RL? An Algorithmic Cheat-Sheet for AI-Based Radio Resource Management
Lorenzo Maggi, Matthew Andrews, Ryo Koblitz
Several Radio Resource Management (RRM) use cases can be framed as sequential decision planning problems, where an agent (the base station, typically) makes decisions that influence the network utility and state. While Reinforcement Learning (RL) in its general form can address this scenario, it is known to be sample inefficient. Following the principle of Occam's razor, we argue that the choice of the solution technique for RRM should be guided by questions such as, Is it a short or long-term planning problem?, Is the underlying model known or does it need to be learned?, Can we solve the problem analytically? or Is an expert-designed policy available?. A wide range of techniques exists to address these questions, including static and stochastic optimization, bandits, model predictive control (MPC) and, indeed, RL. We review some of these techniques that have already been successfully applied to RRM, and we believe that others, such as MPC, may present exciting research opportunities for the future.
Read more5/31/2024
0
Preference Elicitation for Offline Reinforcement Learning
Aliz'ee Pace, Bernhard Scholkopf, Gunnar Ratsch, Giorgia Ramponi
Applying reinforcement learning (RL) to real-world problems is often made challenging by the inability to interact with the environment and the difficulty of designing reward functions. Offline RL addresses the first challenge by considering access to an offline dataset of environment interactions labeled by the reward function. In contrast, Preference-based RL does not assume access to the reward function and learns it from preferences, but typically requires an online interaction with the environment. We bridge the gap between these frameworks by exploring efficient methods for acquiring preference feedback in a fully offline setup. We propose Sim-OPRL, an offline preference-based reinforcement learning algorithm, which leverages a learned environment model to elicit preference feedback on simulated rollouts. Drawing on insights from both the offline RL and the preference-based RL literature, our algorithm employs a pessimistic approach for out-of-distribution data, and an optimistic approach for acquiring informative preferences about the optimal policy. We provide theoretical guarantees regarding the sample complexity of our approach, dependent on how well the offline data covers the optimal policy. Finally, we demonstrate the empirical performance of Sim-OPRL in different environments.
Read more6/27/2024

0
Offline Reinforcement Learning with Imputed Rewards
Carlo Romeo, Andrew D. Bagdanov
Offline Reinforcement Learning (ORL) offers a robust solution to training agents in applications where interactions with the environment must be strictly limited due to cost, safety, or lack of accurate simulation environments. Despite its potential to facilitate deployment of artificial agents in the real world, Offline Reinforcement Learning typically requires very many demonstrations annotated with ground-truth rewards. Consequently, state-of-the-art ORL algorithms can be difficult or impossible to apply in data-scarce scenarios. In this paper we propose a simple but effective Reward Model that can estimate the reward signal from a very limited sample of environment transitions annotated with rewards. Once the reward signal is modeled, we use the Reward Model to impute rewards for a large sample of reward-free transitions, thus enabling the application of ORL techniques. We demonstrate the potential of our approach on several D4RL continuous locomotion tasks. Our results show that, using only 1% of reward-labeled transitions from the original datasets, our learned reward model is able to impute rewards for the remaining 99% of the transitions, from which performant agents can be learned using Offline Reinforcement Learning.
Read more7/16/2024