Offline Inverse RL: New Solution Concepts and Provably Efficient Algorithms
2402.15392
0
0
👁️
Abstract
Inverse reinforcement learning (IRL) aims to recover the reward function of an expert agent from demonstrations of behavior. It is well-known that the IRL problem is fundamentally ill-posed, i.e., many reward functions can explain the demonstrations. For this reason, IRL has been recently reframed in terms of estimating the feasible reward set (Metelli et al., 2021), thus, postponing the selection of a single reward. However, so far, the available formulations and algorithmic solutions have been proposed and analyzed mainly for the online setting, where the learner can interact with the environment and query the expert at will. This is clearly unrealistic in most practical applications, where the availability of an offline dataset is a much more common scenario. In this paper, we introduce a novel notion of feasible reward set capturing the opportunities and limitations of the offline setting and we analyze the complexity of its estimation. This requires the introduction an original learning framework that copes with the intrinsic difficulty of the setting, for which the data coverage is not under control. Then, we propose two computationally and statistically efficient algorithms, IRLO and PIRLO, for addressing the problem. In particular, the latter adopts a specific form of pessimism to enforce the novel desirable property of inclusion monotonicity of the delivered feasible set. With this work, we aim to provide a panorama of the challenges of the offline IRL problem and how they can be fruitfully addressed.
Create account to get full access
Overview
- Inverse reinforcement learning (IRL) aims to recover the reward function of an expert agent from demonstrations of behavior.
- The IRL problem is fundamentally ill-posed, meaning many reward functions can explain the demonstrations.
- Recent work has reframed IRL in terms of estimating the feasible reward set, postponing the selection of a single reward.
- However, previous formulations and algorithms have focused on the online setting, where the learner can interact with the environment and query the expert at will.
- This paper introduces a novel notion of feasible reward set for the offline setting, where the availability of an offline dataset is more common.
- The paper analyzes the complexity of estimating this feasible reward set and proposes two efficient algorithms, IRLO and PIRLO, to address the problem.
Plain English Explanation
In this research, the researchers are working on a problem called "inverse reinforcement learning" (IRL). The goal of IRL is to figure out the "reward function" that an expert agent is using to make decisions, based on watching the expert's behavior.
The challenge is that there can be many different reward functions that could explain the expert's behavior. This makes the IRL problem quite difficult to solve. Recently, researchers have started to think about IRL in a different way - instead of trying to find a single reward function, they try to find the "set" of all possible reward functions that could explain the expert's behavior.
However, most of the previous work on this problem has focused on a setting where the learner can actively interact with the environment and ask the expert for more information. In reality, this is often not the case - we may only have a fixed dataset of the expert's behavior, without the ability to get more information.
This paper introduces a new way of thinking about the "feasible reward set" in this offline setting, where we only have a dataset to work with. The researchers analyze how difficult it is to estimate this reward set, and then propose two efficient algorithms, called IRLO and PIRLO, to address the problem.
The key idea is to find the set of all reward functions that are consistent with the expert's behavior in the dataset, without being able to actively query the expert or interact with the environment. This is a more realistic and challenging setting, but the researchers show how it can be addressed effectively.
Technical Explanation
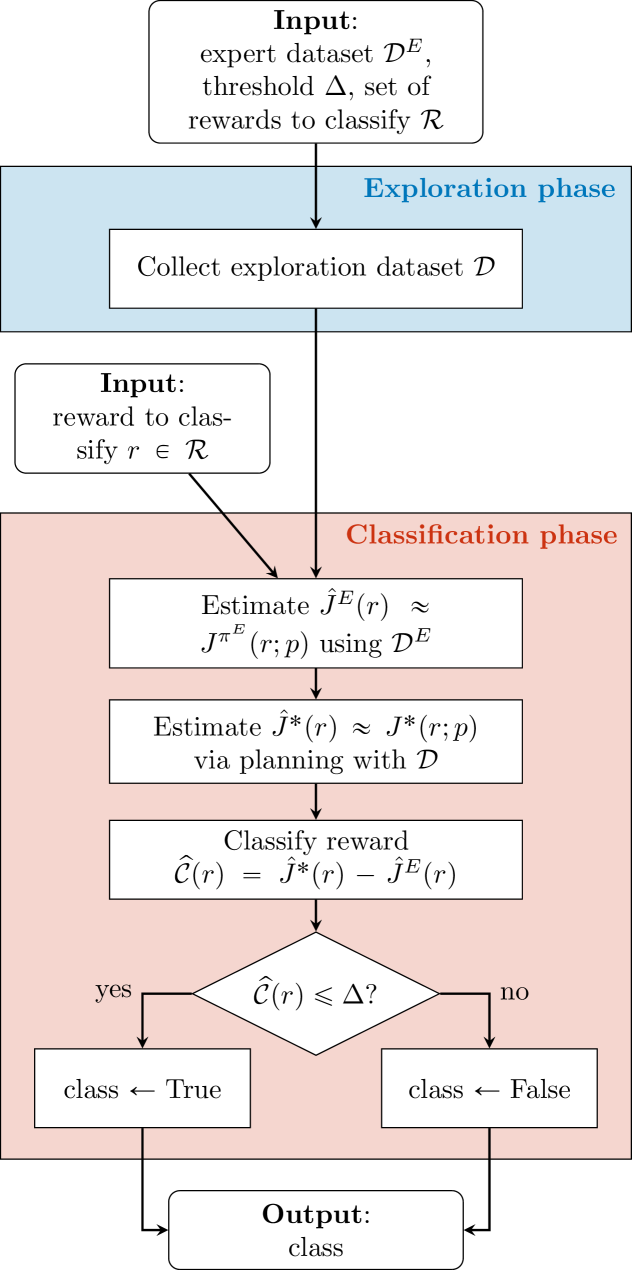
The paper introduces a novel notion of the "feasible reward set" for the offline IRL setting, where the learner has access to a fixed dataset of the expert's behavior, rather than being able to actively interact with the environment and query the expert.
The researchers first analyze the complexity of estimating this feasible reward set in the offline setting. They show that this problem is inherently more difficult than the online setting, where the learner has more control over the data. This is because the offline dataset may not provide sufficient coverage of the environment and expert's behavior.
To address this challenge, the paper proposes two computationally and statistically efficient algorithms: IRLO and PIRLO. IRLO is a straightforward extension of previous IRL approaches to the offline setting. PIRLO, on the other hand, adopts a specific form of "pessimism" to enforce a desirable property called "inclusion monotonicity" - the feasible reward set delivered by PIRLO is guaranteed to be a superset of the set delivered by previous iterations.
The key insight behind PIRLO is to leverage the structure of the offline IRL problem to define a robust optimization problem that can be solved efficiently. This allows PIRLO to provide meaningful guarantees on the quality of the estimated feasible reward set, even in the face of the inherent difficulties of the offline setting.
The paper also provides a comprehensive experimental evaluation of the proposed algorithms, demonstrating their effectiveness in recovering the feasible reward set from offline datasets in a variety of benchmark domains.
Critical Analysis
The paper makes an important contribution by addressing the offline IRL problem, which is a more realistic setting compared to the online IRL problem considered in much of the prior work. By introducing a novel notion of the feasible reward set and proposing efficient algorithms to estimate it, the researchers have taken a significant step forward in making IRL more applicable to real-world scenarios.
One potential limitation of the work is that the analysis and algorithms are still focused on the setting where the learner has access to a fixed offline dataset. In many real-world applications, the dataset may be continuously growing or changing, and the learner may need to adapt their approach accordingly. Extensions of this work to the "online" or "continual" IRL setting could be an important area for future research.
Additionally, the paper does not address the issue of how to select a single reward function from the estimated feasible set. While postponing this decision can be useful, ultimately, a practical IRL system will need to make this choice, potentially by incorporating additional information or preferences. Techniques for scaling IRL to large and complex domains could also be an important area for further research.
Overall, this paper makes a valuable contribution to the field of IRL by introducing a new perspective on the offline setting and proposing efficient algorithms to address the challenges it presents. The work lays the groundwork for further advancements in making IRL more applicable to real-world problems.
Conclusion
This paper introduces a novel formulation of the inverse reinforcement learning (IRL) problem for the offline setting, where the learner has access to a fixed dataset of an expert's behavior, rather than being able to actively interact with the environment and query the expert.
The researchers analyze the complexity of estimating the "feasible reward set" in this offline setting, which is shown to be more challenging than the online setting. To address this, the paper proposes two efficient algorithms, IRLO and PIRLO, that can effectively recover the feasible reward set from the offline data.
By shifting the focus of IRL from finding a single reward function to estimating the set of all possible reward functions, this work opens up new opportunities for applying IRL in realistic scenarios where the learner has limited access to the expert and environment. The insights and techniques developed in this paper lay the foundation for further advancements in making IRL a more practical and widely applicable tool for AI and robotics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
A Unified Linear Programming Framework for Offline Reward Learning from Human Demonstrations and Feedback
Kihyun Kim, Jiawei Zhang, Asuman Ozdaglar, Pablo A. Parrilo
0
0
Inverse Reinforcement Learning (IRL) and Reinforcement Learning from Human Feedback (RLHF) are pivotal methodologies in reward learning, which involve inferring and shaping the underlying reward function of sequential decision-making problems based on observed human demonstrations and feedback. Most prior work in reward learning has relied on prior knowledge or assumptions about decision or preference models, potentially leading to robustness issues. In response, this paper introduces a novel linear programming (LP) framework tailored for offline reward learning. Utilizing pre-collected trajectories without online exploration, this framework estimates a feasible reward set from the primal-dual optimality conditions of a suitably designed LP, and offers an optimality guarantee with provable sample efficiency. Our LP framework also enables aligning the reward functions with human feedback, such as pairwise trajectory comparison data, while maintaining computational tractability and sample efficiency. We demonstrate that our framework potentially achieves better performance compared to the conventional maximum likelihood estimation (MLE) approach through analytical examples and numerical experiments.
6/5/2024
🏅
Convergence of a model-free entropy-regularized inverse reinforcement learning algorithm
Titouan Renard, Andreas Schlaginhaufen, Tingting Ni, Maryam Kamgarpour
0
0
Given a dataset of expert demonstrations, inverse reinforcement learning (IRL) aims to recover a reward for which the expert is optimal. This work proposes a model-free algorithm to solve entropy-regularized IRL problem. In particular, we employ a stochastic gradient descent update for the reward and a stochastic soft policy iteration update for the policy. Assuming access to a generative model, we prove that our algorithm is guaranteed to recover a reward for which the expert is $varepsilon$-optimal using $mathcal{O}(1/varepsilon^{2})$ samples of the Markov decision process (MDP). Furthermore, with $mathcal{O}(1/varepsilon^{4})$ samples we prove that the optimal policy corresponding to the recovered reward is $varepsilon$-close to the expert policy in total variation distance.
4/24/2024
🏅
A Bayesian Approach to Robust Inverse Reinforcement Learning
Ran Wei, Siliang Zeng, Chenliang Li, Alfredo Garcia, Anthony McDonald, Mingyi Hong
0
0
We consider a Bayesian approach to offline model-based inverse reinforcement learning (IRL). The proposed framework differs from existing offline model-based IRL approaches by performing simultaneous estimation of the expert's reward function and subjective model of environment dynamics. We make use of a class of prior distributions which parameterizes how accurate the expert's model of the environment is to develop efficient algorithms to estimate the expert's reward and subjective dynamics in high-dimensional settings. Our analysis reveals a novel insight that the estimated policy exhibits robust performance when the expert is believed (a priori) to have a highly accurate model of the environment. We verify this observation in the MuJoCo environments and show that our algorithms outperform state-of-the-art offline IRL algorithms.
4/9/2024
How to Scale Inverse RL to Large State Spaces? A Provably Efficient Approach
Filippo Lazzati, Mirco Mutti, Alberto Maria Metelli
0
0
In online Inverse Reinforcement Learning (IRL), the learner can collect samples about the dynamics of the environment to improve its estimate of the reward function. Since IRL suffers from identifiability issues, many theoretical works on online IRL focus on estimating the entire set of rewards that explain the demonstrations, named the feasible reward set. However, none of the algorithms available in the literature can scale to problems with large state spaces. In this paper, we focus on the online IRL problem in Linear Markov Decision Processes (MDPs). We show that the structure offered by Linear MDPs is not sufficient for efficiently estimating the feasible set when the state space is large. As a consequence, we introduce the novel framework of rewards compatibility, which generalizes the notion of feasible set, and we develop CATY-IRL, a sample efficient algorithm whose complexity is independent of the cardinality of the state space in Linear MDPs. When restricted to the tabular setting, we demonstrate that CATY-IRL is minimax optimal up to logarithmic factors. As a by-product, we show that Reward-Free Exploration (RFE) enjoys the same worst-case rate, improving over the state-of-the-art lower bound. Finally, we devise a unifying framework for IRL and RFE that may be of independent interest.
6/7/2024