Omniview-Tuning: Boosting Viewpoint Invariance of Vision-Language Pre-training Models

0

Sign in to get full access
Overview
- Introduces a new technique called "Omniview-Tuning" to improve the viewpoint invariance of vision-language pre-training models.
- Viewpoint invariance is the ability of a model to recognize and understand objects and scenes from different perspectives.
- Improving viewpoint invariance can enhance the performance and robustness of vision-language models in real-world applications.
Plain English Explanation
The paper presents a novel method called "Omniview-Tuning" that aims to make vision-language pre-training models more robust to changes in viewpoint. Viewpoint invariance is an important capability for these models, as it allows them to recognize and understand objects and scenes from different angles or perspectives.
For example, if you show a model a chair from the front, it should be able to recognize that same chair if it's shown from the side or from above. This viewpoint invariance can be crucial for real-world applications, such as Vitamin: Designing Scalable Vision Models for Vision-Language or Distilling Vision-Language Models from Millions of Videos, where the model needs to work reliably in diverse environments and conditions.
The paper introduces a new training technique that helps to boost this viewpoint invariance in vision-language models, making them more versatile and effective in practical settings. By incorporating this Omniview-Tuning approach, the models can better recognize and understand objects and scenes from a wide range of perspectives.
Technical Explanation
The key idea behind Omniview-Tuning is to augment the training data with multiple viewpoints of the same objects and scenes. This is achieved by applying a set of geometric transformations, such as rotations and reflections, to the input images during the pre-training stage.
By exposing the model to these diverse viewpoints, the authors hypothesize that the model will learn to extract features that are more invariant to changes in perspective. This, in turn, can improve the model's ability to recognize and understand objects and scenes from different angles, as demonstrated in Collavo: A Large Language-Vision Model with Efficient Finetuning and Anchor-based Robust Finetuning of Vision-Language Models.
The paper also introduces a novel self-supervised pretext task, called "Viewpoint Prediction," which further encourages the model to learn viewpoint-invariant representations. In this task, the model is tasked with predicting the geometric transformation applied to the input image during the data augmentation process.
Through extensive experiments on various vision-language benchmarks, the authors show that Omniview-Tuning can significantly boost the viewpoint invariance of pre-trained models, leading to improved performance on tasks that require understanding objects and scenes from different perspectives, such as Bridging Vision and Language Spaces for Assignment Prediction.
Critical Analysis
The paper presents a compelling approach to improving the viewpoint invariance of vision-language pre-training models, which is an important capability for real-world applications. The authors provide a thorough evaluation of their method on various benchmarks, demonstrating its effectiveness.
One potential limitation of the approach is that the data augmentation and viewpoint prediction pretext task may introduce additional complexity and computational overhead during the pre-training stage. The authors do not provide a detailed analysis of the trade-offs between the performance gains and the increased training time or resource requirements.
Additionally, the paper does not explore the potential limitations or failure modes of Omniview-Tuning, such as how the method might perform on highly occluded or noisy input images, or how it compares to other viewpoint-invariant techniques like Vitamin: Designing Scalable Vision Models for Vision-Language.
Further research could investigate the generalization of Omniview-Tuning to other vision-language tasks, as well as its performance on more diverse and challenging datasets. Exploring the interpretability and robustness of the learned representations would also be valuable.
Conclusion
The Omniview-Tuning technique presented in this paper represents a promising approach to improving the viewpoint invariance of vision-language pre-training models. By incorporating diverse viewpoints during the pre-training stage and introducing a novel pretext task, the authors demonstrate significant performance gains on benchmarks that require understanding objects and scenes from different perspectives.
This work has the potential to enhance the robustness and real-world applicability of vision-language models, enabling them to perform more reliably in diverse environments and conditions. Further research and refinement of the Omniview-Tuning method could lead to even more versatile and capable vision-language systems that can better serve a wide range of practical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Omniview-Tuning: Boosting Viewpoint Invariance of Vision-Language Pre-training Models
Shouwei Ruan, Yinpeng Dong, Hanqing Liu, Yao Huang, Hang Su, Xingxing Wei
Vision-Language Pre-training (VLP) models like CLIP have achieved remarkable success in computer vision and particularly demonstrated superior robustness to distribution shifts of 2D images. However, their robustness under 3D viewpoint variations is still limited, which can hinder the development for real-world applications. This paper successfully addresses this concern while keeping VLPs' original performance by breaking through two primary obstacles: 1) the scarcity of training data and 2) the suboptimal fine-tuning paradigms. To combat data scarcity, we build the Multi-View Caption (MVCap) dataset -- a comprehensive collection of over four million multi-view image-text pairs across more than 100K objects, providing more potential for VLP models to develop generalizable viewpoint-invariant representations. To address the limitations of existing paradigms in performance trade-offs and training efficiency, we design a novel fine-tuning framework named Omniview-Tuning (OVT). Specifically, OVT introduces a Cross-Viewpoint Alignment objective through a minimax-like optimization strategy, which effectively aligns representations of identical objects from diverse viewpoints without causing overfitting. Additionally, OVT fine-tunes VLP models in a parameter-efficient manner, leading to minimal computational cost. Extensive experiments on various VLP models with different architectures validate that OVT significantly improves the models' resilience to viewpoint shifts and keeps the original performance, establishing a pioneering standard for boosting the viewpoint invariance of VLP models.
Read more4/19/2024

0
3D Vision and Language Pretraining with Large-Scale Synthetic Data
Dejie Yang, Zhu Xu, Wentao Mo, Qingchao Chen, Siyuan Huang, Yang Liu
3D Vision-Language Pre-training (3D-VLP) aims to provide a pre-train model which can bridge 3D scenes with natural language, which is an important technique for embodied intelligence. However, current 3D-VLP datasets are hindered by limited scene-level diversity and insufficient fine-grained annotations (only 1.2K scenes and 280K textual annotations in ScanScribe), primarily due to the labor-intensive of collecting and annotating 3D scenes. To overcome these obstacles, we construct SynVL3D, a comprehensive synthetic scene-text corpus with 10K indoor scenes and 1M descriptions at object, view, and room levels, which has the advantages of diverse scene data, rich textual descriptions, multi-grained 3D-text associations, and low collection cost. Utilizing the rich annotations in SynVL3D, we pre-train a simple and unified Transformer for aligning 3D and language with multi-grained pretraining tasks. Moreover, we propose a synthetic-to-real domain adaptation in downstream task fine-tuning process to address the domain shift. Through extensive experiments, we verify the effectiveness of our model design by achieving state-of-the-art performance on downstream tasks including visual grounding, dense captioning, and question answering.
Read more7/9/2024

0
View-Invariant Policy Learning via Zero-Shot Novel View Synthesis
Stephen Tian, Blake Wulfe, Kyle Sargent, Katherine Liu, Sergey Zakharov, Vitor Guizilini, Jiajun Wu
Large-scale visuomotor policy learning is a promising approach toward developing generalizable manipulation systems. Yet, policies that can be deployed on diverse embodiments, environments, and observational modalities remain elusive. In this work, we investigate how knowledge from large-scale visual data of the world may be used to address one axis of variation for generalizable manipulation: observational viewpoint. Specifically, we study single-image novel view synthesis models, which learn 3D-aware scene-level priors by rendering images of the same scene from alternate camera viewpoints given a single input image. For practical application to diverse robotic data, these models must operate zero-shot, performing view synthesis on unseen tasks and environments. We empirically analyze view synthesis models within a simple data-augmentation scheme that we call View Synthesis Augmentation (VISTA) to understand their capabilities for learning viewpoint-invariant policies from single-viewpoint demonstration data. Upon evaluating the robustness of policies trained with our method to out-of-distribution camera viewpoints, we find that they outperform baselines in both simulated and real-world manipulation tasks. Videos and additional visualizations are available at https://s-tian.github.io/projects/vista.
Read more9/6/2024
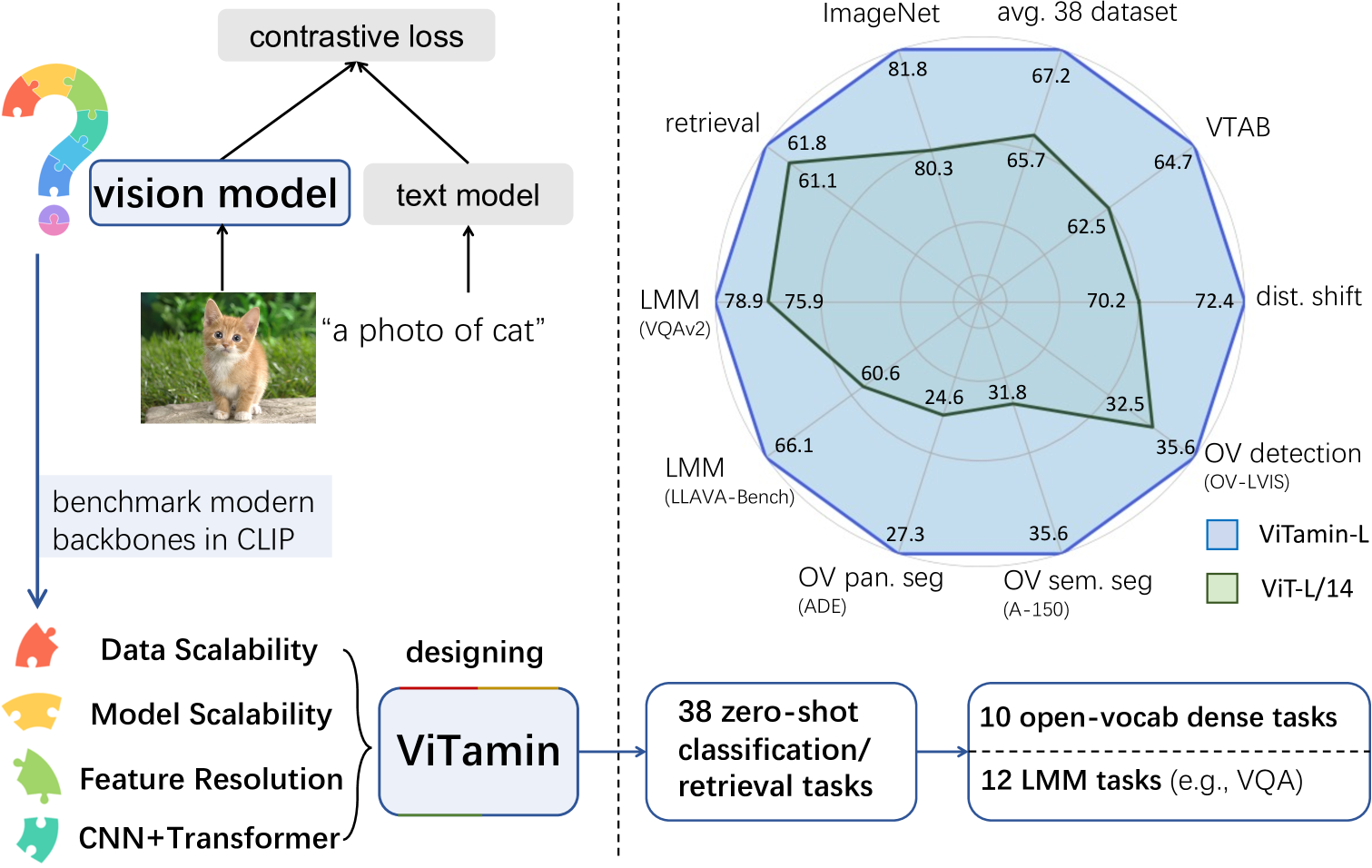
0
ViTamin: Designing Scalable Vision Models in the Vision-Language Era
Jieneng Chen, Qihang Yu, Xiaohui Shen, Alan Yuille, Liang-Chieh Chen
Recent breakthroughs in vision-language models (VLMs) start a new page in the vision community. The VLMs provide stronger and more generalizable feature embeddings compared to those from ImageNet-pretrained models, thanks to the training on the large-scale Internet image-text pairs. However, despite the amazing achievement from the VLMs, vanilla Vision Transformers (ViTs) remain the default choice for the image encoder. Although pure transformer proves its effectiveness in the text encoding area, it remains questionable whether it is also the case for image encoding, especially considering that various types of networks are proposed on the ImageNet benchmark, which, unfortunately, are rarely studied in VLMs. Due to small data/model scale, the original conclusions of model design on ImageNet can be limited and biased. In this paper, we aim at building an evaluation protocol of vision models in the vision-language era under the contrastive language-image pretraining (CLIP) framework. We provide a comprehensive way to benchmark different vision models, covering their zero-shot performance and scalability in both model and training data sizes. To this end, we introduce ViTamin, a new vision models tailored for VLMs. ViTamin-L significantly outperforms ViT-L by 2.0% ImageNet zero-shot accuracy, when using the same publicly available DataComp-1B dataset and the same OpenCLIP training scheme. ViTamin-L presents promising results on 60 diverse benchmarks, including classification, retrieval, open-vocabulary detection and segmentation, and large multi-modal models. When further scaling up the model size, our ViTamin-XL with only 436M parameters attains 82.9% ImageNet zero-shot accuracy, surpassing 82.0% achieved by EVA-E that has ten times more parameters (4.4B).
Read more4/5/2024