View-Invariant Policy Learning via Zero-Shot Novel View Synthesis

0

Sign in to get full access
Overview
- Introduces a novel approach for learning view-invariant policies in reinforcement learning tasks
- Leverages a zero-shot novel view synthesis model to generate diverse viewpoints of the environment, enabling the policy to learn from a single camera view
- Demonstrates improved performance on several robotic manipulation tasks compared to baseline methods
Plain English Explanation
The paper presents a new technique for training reinforcement learning agents to perform tasks in a way that is not dependent on the specific camera viewpoint. This is an important challenge, as real-world robotic systems often have limited sensor coverage and can only observe the environment from a single perspective.
The key insight is to use a zero-shot novel view synthesis model to generate diverse views of the environment from a single camera feed. This allows the reinforcement learning agent to train on a wider variety of viewpoints, making it more robust to changes in camera position or orientation.
During training, the agent learns a "view-invariant" policy that can perform the task effectively regardless of the camera's perspective. This is in contrast to standard approaches that rely on the agent learning a separate policy for each possible viewpoint, which can be inefficient and impractical.
The researchers demonstrate the effectiveness of their method on several robotic manipulation tasks, showing improved performance compared to baseline techniques that do not leverage the synthetic viewpoints. This suggests the approach could be valuable for developing autonomous systems that need to operate reliably in complex, real-world environments with limited sensing capabilities.
Technical Explanation
The paper introduces a novel framework for view-invariant policy learning in reinforcement learning. The key component is a zero-shot novel view synthesis model that can generate diverse viewpoints of the agent's environment from a single camera feed.
The architecture consists of three main modules:
- View Synthesis Network: Takes a single camera observation as input and generates novel views of the environment using a PolyOculus style model.
- Policy Network: The reinforcement learning agent's policy network, which takes the original camera view and the synthesized views as input and outputs actions to perform the task.
- Discriminator Network: Ensures the synthesized views are realistic and consistent with the original observation through an adversarial training process.
During training, the agent learns a view-invariant policy by training on the diverse set of viewpoints generated by the view synthesis network. This allows the policy to generalize beyond the specific camera perspective seen during data collection, enabling robust performance in novel viewpoints.
The researchers evaluate their approach on several robotic manipulation tasks, including peg insertion, block stacking, and door opening. They show that the view-invariant policies learned using their framework outperform baseline methods that do not leverage the synthetic viewpoints.
Critical Analysis
The paper presents a promising approach for addressing the challenge of view-invariant policy learning in reinforcement learning. By integrating a zero-shot novel view synthesis model, the framework can generate diverse viewpoints of the environment, enabling the agent to learn policies that are robust to changes in camera perspective.
One potential limitation is the reliance on the accuracy and fidelity of the view synthesis model. If the generated views do not accurately capture the true environment, it could lead to sub-optimal policy learning. The authors acknowledge this and suggest further research is needed to improve the view synthesis capabilities.
Additionally, the evaluation is focused on relatively simple robotic manipulation tasks. It would be valuable to see how the approach scales to more complex, real-world environments with higher-dimensional state and action spaces. Deploying the method in the real world would also require addressing potential issues with sim-to-real transfer and domain adaptation.
Overall, the paper makes a compelling case for the value of view-invariant policy learning and demonstrates a promising technical approach. Further research and development in this area could lead to more robust and capable autonomous systems that can operate effectively in diverse, unconstrained environments.
Conclusion
This paper presents a novel framework for learning view-invariant policies in reinforcement learning tasks. By leveraging a zero-shot novel view synthesis model, the approach can generate diverse viewpoints of the agent's environment, enabling the policy to learn from a single camera feed.
The researchers demonstrate the effectiveness of their method on several robotic manipulation tasks, showing improved performance compared to baseline techniques. This suggests the framework could be valuable for developing autonomous systems that need to operate reliably in complex, real-world environments with limited sensing capabilities.
While the paper highlights some potential limitations, the core idea of using synthetic viewpoints to enable view-invariant policy learning is a promising direction for future research. Continued advancements in this area could lead to more robust and capable robotic and AI systems that can adapt to a wide range of environmental conditions and sensor configurations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
View-Invariant Policy Learning via Zero-Shot Novel View Synthesis
Stephen Tian, Blake Wulfe, Kyle Sargent, Katherine Liu, Sergey Zakharov, Vitor Guizilini, Jiajun Wu
Large-scale visuomotor policy learning is a promising approach toward developing generalizable manipulation systems. Yet, policies that can be deployed on diverse embodiments, environments, and observational modalities remain elusive. In this work, we investigate how knowledge from large-scale visual data of the world may be used to address one axis of variation for generalizable manipulation: observational viewpoint. Specifically, we study single-image novel view synthesis models, which learn 3D-aware scene-level priors by rendering images of the same scene from alternate camera viewpoints given a single input image. For practical application to diverse robotic data, these models must operate zero-shot, performing view synthesis on unseen tasks and environments. We empirically analyze view synthesis models within a simple data-augmentation scheme that we call View Synthesis Augmentation (VISTA) to understand their capabilities for learning viewpoint-invariant policies from single-viewpoint demonstration data. Upon evaluating the robustness of policies trained with our method to out-of-distribution camera viewpoints, we find that they outperform baselines in both simulated and real-world manipulation tasks. Videos and additional visualizations are available at https://s-tian.github.io/projects/vista.
Read more9/6/2024
0
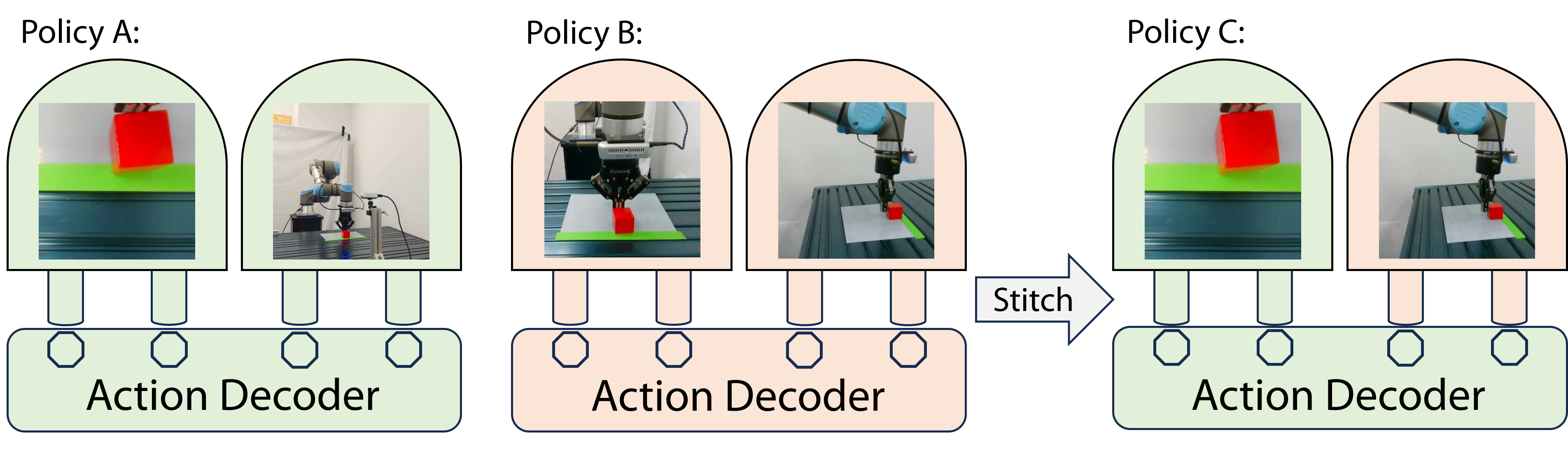
Perception Stitching: Zero-Shot Perception Encoder Transfer for Visuomotor Robot Policies
Pingcheng Jian, Easop Lee, Zachary Bell, Michael M. Zavlanos, Boyuan Chen
Vision-based imitation learning has shown promising capabilities of endowing robots with various motion skills given visual observation. However, current visuomotor policies fail to adapt to drastic changes in their visual observations. We present Perception Stitching that enables strong zero-shot adaptation to large visual changes by directly stitching novel combinations of visual encoders. Our key idea is to enforce modularity of visual encoders by aligning the latent visual features among different visuomotor policies. Our method disentangles the perceptual knowledge with the downstream motion skills and allows the reuse of the visual encoders by directly stitching them to a policy network trained with partially different visual conditions. We evaluate our method in various simulated and real-world manipulation tasks. While baseline methods failed at all attempts, our method could achieve zero-shot success in real-world visuomotor tasks. Our quantitative and qualitative analysis of the learned features of the policy network provides more insights into the high performance of our proposed method.
Read more7/1/2024
🛸
0
PolyOculus: Simultaneous Multi-view Image-based Novel View Synthesis
Jason J. Yu, Tristan Aumentado-Armstrong, Fereshteh Forghani, Konstantinos G. Derpanis, Marcus A. Brubaker
This paper considers the problem of generative novel view synthesis (GNVS), generating novel, plausible views of a scene given a limited number of known views. Here, we propose a set-based generative model that can simultaneously generate multiple, self-consistent new views, conditioned on any number of views. Our approach is not limited to generating a single image at a time and can condition on a variable number of views. As a result, when generating a large number of views, our method is not restricted to a low-order autoregressive generation approach and is better able to maintain generated image quality over large sets of images. We evaluate our model on standard NVS datasets and show that it outperforms the state-of-the-art image-based GNVS baselines. Further, we show that the model is capable of generating sets of views that have no natural sequential ordering, like loops and binocular trajectories, and significantly outperforms other methods on such tasks.
Read more7/29/2024

0
Omniview-Tuning: Boosting Viewpoint Invariance of Vision-Language Pre-training Models
Shouwei Ruan, Yinpeng Dong, Hanqing Liu, Yao Huang, Hang Su, Xingxing Wei
Vision-Language Pre-training (VLP) models like CLIP have achieved remarkable success in computer vision and particularly demonstrated superior robustness to distribution shifts of 2D images. However, their robustness under 3D viewpoint variations is still limited, which can hinder the development for real-world applications. This paper successfully addresses this concern while keeping VLPs' original performance by breaking through two primary obstacles: 1) the scarcity of training data and 2) the suboptimal fine-tuning paradigms. To combat data scarcity, we build the Multi-View Caption (MVCap) dataset -- a comprehensive collection of over four million multi-view image-text pairs across more than 100K objects, providing more potential for VLP models to develop generalizable viewpoint-invariant representations. To address the limitations of existing paradigms in performance trade-offs and training efficiency, we design a novel fine-tuning framework named Omniview-Tuning (OVT). Specifically, OVT introduces a Cross-Viewpoint Alignment objective through a minimax-like optimization strategy, which effectively aligns representations of identical objects from diverse viewpoints without causing overfitting. Additionally, OVT fine-tunes VLP models in a parameter-efficient manner, leading to minimal computational cost. Extensive experiments on various VLP models with different architectures validate that OVT significantly improves the models' resilience to viewpoint shifts and keeps the original performance, establishing a pioneering standard for boosting the viewpoint invariance of VLP models.
Read more4/19/2024