Tensor-based Graph Learning with Consistency and Specificity for Multi-view Clustering
2403.18393
0
0
Abstract
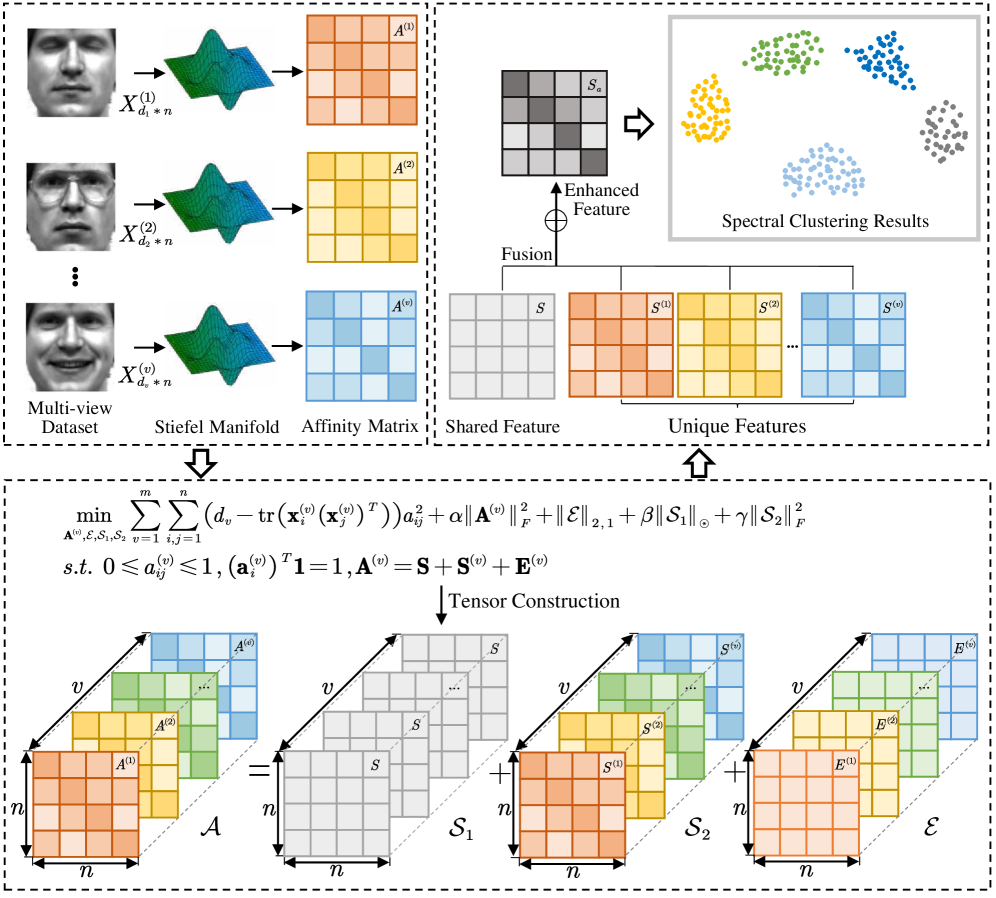
In the context of multi-view clustering, graph learning is recognized as a crucial technique, which generally involves constructing an adaptive neighbor graph based on probabilistic neighbors, and then learning a consensus graph to for clustering. However, they are confronted with two limitations. Firstly, they often rely on Euclidean distance to measure similarity when constructing the adaptive neighbor graph, which proves inadequate in capturing the intrinsic structure among data points in practice. Secondly, most of these methods focus solely on consensus graph, ignoring unique information from each view. Although a few graph-based studies have considered using specific information as well, the modelling approach employed does not exclude the noise impact from the specific component. To this end, we propose a novel tensor-based multi-view graph learning framework that simultaneously considers consistency and specificity, while effectively eliminating the influence of noise. Specifically, we calculate similarity distance on the Stiefel manifold to preserve the intrinsic properties of data. By making an assumption that the learned neighbor graph of each view comprises a consistent part, a specific part, and a noise part, we formulate a new tensor-based target graph learning paradigm for noise-free graph fusion. Owing to the benefits of tensor singular value decomposition (t-SVD) in uncovering high-order correlations, this model is capable of achieving a complete understanding of the target graph. Furthermore, we derive an algorithm to address the optimization problem. Experiments on six datasets have demonstrated the superiority of our method. We have released the source code on https://github.com/lshi91/CSTGL-Code.
Create account to get full access
Overview
- This paper proposes a tensor-based graph learning method for multi-view clustering that aims to learn consistent and view-specific graphs.
- The method optimizes for graph consistency across views while preserving the unique characteristics of each view.
- The authors formulate the problem as an optimization on the Stiefel manifold and provide an efficient algorithm to solve it.
Plain English Explanation
In this research, the authors developed a new way to group similar data points from different "views" or perspectives. For example, you might have images of an object from different angles, or text and audio describing the same thing. The goal is to cluster the data into meaningful groups, even though the different views may have distinct characteristics.
The key idea is to learn a consistent graph that captures the overall similarity between data points, while also learning view-specific graphs that preserve the unique aspects of each view. This is done by formulating the problem as an optimization on a mathematical structure called the Stiefel manifold, which allows the method to efficiently find the optimal solutions.
By learning both consistent and view-specific graphs, this approach can better utilize the information contained in the multiple views to improve the clustering performance, compared to methods that only consider a single view or assume all views are equally important.
Technical Explanation
The authors propose a tensor-based graph learning method for multi-view clustering that learns a consistent graph across views as well as view-specific graphs. This is achieved by formulating the problem as an optimization on the Stiefel manifold, which allows the method to jointly optimize the consistent and view-specific graphs.
The consistent graph captures the overall similarity between data points, while the view-specific graphs preserve the unique characteristics of each view. This approach aims to bridge the projection gap and overcome projection bias that can occur when only considering a single view or assuming equal importance of all views.
The authors provide an efficient optimization algorithm to solve the problem and demonstrate the effectiveness of their method on several benchmark multi-view datasets.
Critical Analysis
The paper presents a well-designed and technically sound approach for multi-view clustering. The authors thoroughly discuss the theoretical properties of the proposed method and provide comprehensive experiments to validate its performance.
One potential limitation is that the method assumes the availability of multiple views for each data point. In some real-world scenarios, this may not always be the case, and the method may need to be extended to handle missing views or incomplete data.
Additionally, the computational complexity of the optimization process may be a concern for very large-scale datasets. The authors mention that their algorithm is efficient, but further investigation into the scalability of the method could be valuable.
Overall, the research offers a promising direction for leveraging the complementary information in multi-view data for improved clustering and data analysis. The robust theoretical foundation and empirical results make this work a valuable contribution to the field of multi-view learning.
Conclusion
This paper presents a tensor-based graph learning approach for multi-view clustering that learns both consistent and view-specific graphs. By optimizing for graph consistency across views while preserving the unique characteristics of each view, the method can better utilize the information contained in multiple data sources to enhance clustering performance.
The authors' innovative formulation of the problem on the Stiefel manifold and the efficient optimization algorithm provide a solid foundation for this line of research. The results demonstrate the effectiveness of the proposed method on various benchmark datasets, highlighting its potential for real-world applications involving heterogeneous data.
This work contributes to the broader field of multi-view learning by offering a principled and robust solution for leveraging complementary information from different data modalities. Further research could explore extensions to handle missing views, improve scalability, and investigate the broader applicability of the tensor-based graph learning framework.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

S^2MVTC: a Simple yet Efficient Scalable Multi-View Tensor Clustering
Zhen Long, Qiyuan Wang, Yazhou Ren, Yipeng Liu, Ce Zhu
0
0
Anchor-based large-scale multi-view clustering has attracted considerable attention for its effectiveness in handling massive datasets. However, current methods mainly seek the consensus embedding feature for clustering by exploring global correlations between anchor graphs or projection matrices.In this paper, we propose a simple yet efficient scalable multi-view tensor clustering (S^2MVTC) approach, where our focus is on learning correlations of embedding features within and across views. Specifically, we first construct the embedding feature tensor by stacking the embedding features of different views into a tensor and rotating it. Additionally, we build a novel tensor low-frequency approximation (TLFA) operator, which incorporates graph similarity into embedding feature learning, efficiently achieving smooth representation of embedding features within different views. Furthermore, consensus constraints are applied to embedding features to ensure inter-view semantic consistency. Experimental results on six large-scale multi-view datasets demonstrate that S^2MVTC significantly outperforms state-of-the-art algorithms in terms of clustering performance and CPU execution time, especially when handling massive data. The code of S^2MVTC is publicly available at https://github.com/longzhen520/S2MVTC.
4/12/2024
Multi-View Stochastic Block Models
Vincent Cohen-Addad, Tommaso d'Orsi, Silvio Lattanzi, Rajai Nasser
0
0
Graph clustering is a central topic in unsupervised learning with a multitude of practical applications. In recent years, multi-view graph clustering has gained a lot of attention for its applicability to real-world instances where one has access to multiple data sources. In this paper we formalize a new family of models, called textit{multi-view stochastic block models} that captures this setting. For this model, we first study efficient algorithms that naively work on the union of multiple graphs. Then, we introduce a new efficient algorithm that provably outperforms previous approaches by analyzing the structure of each graph separately. Furthermore, we complement our results with an information-theoretic lower bound studying the limits of what can be done in this model. Finally, we corroborate our results with experimental evaluations.
6/10/2024

Multi-view Graph Structural Representation Learning via Graph Coarsening
Xiaorui Qi, Qijie Bai, Yanlong Wen, Haiwei Zhang, Xiaojie Yuan
0
0
Graph Transformers (GTs) have made remarkable achievements in graph-level tasks. However, most existing works regard graph structures as a form of guidance or bias for enhancing node representations, which focuses on node-central perspectives and lacks explicit representations of edges and structures. One natural question is, can we treat graph structures node-like as a whole to learn high-level features? Through experimental analysis, we explore the feasibility of this assumption. Based on our findings, we propose a novel multi-view graph representation learning model via structure-aware searching and coarsening (GRLsc) on GT architecture for graph classification. Specifically, we build three unique views, original, coarsening, and conversion, to learn a thorough structural representation. We compress loops and cliques via hierarchical heuristic graph coarsening and restrict them with well-designed constraints, which builds the coarsening view to learn high-level interactions between structures. We also introduce line graphs for edge embeddings and switch to edge-central perspective to construct the conversion view. Experiments on eight real-world datasets demonstrate the improvements of GRLsc over 28 baselines from various architectures.
6/26/2024
Synergistic Deep Graph Clustering Network
Benyu Wu, Shifei Ding, Xiao Xu, Lili Guo, Ling Ding, Xindong Wu
0
0
Employing graph neural networks (GNNs) to learn cohesive and discriminative node representations for clustering has shown promising results in deep graph clustering. However, existing methods disregard the reciprocal relationship between representation learning and structure augmentation. This study suggests that enhancing embedding and structure synergistically becomes imperative for GNNs to unleash their potential in deep graph clustering. A reliable structure promotes obtaining more cohesive node representations, while high-quality node representations can guide the augmentation of the structure, enhancing structural reliability in return. Moreover, the generalization ability of existing GNNs-based models is relatively poor. While they perform well on graphs with high homogeneity, they perform poorly on graphs with low homogeneity. To this end, we propose a graph clustering framework named Synergistic Deep Graph Clustering Network (SynC). In our approach, we design a Transform Input Graph Auto-Encoder (TIGAE) to obtain high-quality embeddings for guiding structure augmentation. Then, we re-capture neighborhood representations on the augmented graph to obtain clustering-friendly embeddings and conduct self-supervised clustering. Notably, representation learning and structure augmentation share weights, significantly reducing the number of model parameters. Additionally, we introduce a structure fine-tuning strategy to improve the model's generalization. Extensive experiments on benchmark datasets demonstrate the superiority and effectiveness of our method. The code is released on GitHub and Code Ocean.
6/26/2024