S^2MVTC: a Simple yet Efficient Scalable Multi-View Tensor Clustering
2403.09107
0
0

Abstract
Anchor-based large-scale multi-view clustering has attracted considerable attention for its effectiveness in handling massive datasets. However, current methods mainly seek the consensus embedding feature for clustering by exploring global correlations between anchor graphs or projection matrices.In this paper, we propose a simple yet efficient scalable multi-view tensor clustering (S^2MVTC) approach, where our focus is on learning correlations of embedding features within and across views. Specifically, we first construct the embedding feature tensor by stacking the embedding features of different views into a tensor and rotating it. Additionally, we build a novel tensor low-frequency approximation (TLFA) operator, which incorporates graph similarity into embedding feature learning, efficiently achieving smooth representation of embedding features within different views. Furthermore, consensus constraints are applied to embedding features to ensure inter-view semantic consistency. Experimental results on six large-scale multi-view datasets demonstrate that S^2MVTC significantly outperforms state-of-the-art algorithms in terms of clustering performance and CPU execution time, especially when handling massive data. The code of S^2MVTC is publicly available at https://github.com/longzhen520/S2MVTC.
Create account to get full access
Overview
- Proposes a new multi-view tensor clustering algorithm called S²MVTC (Simple and Scalable Multi-View Tensor Clustering)
- Aims to effectively cluster multi-view data represented as tensors
- Designed to be scalable and computationally efficient
Plain English Explanation
S²MVTC is a method for grouping and organizing multi-view data, which means data that can be looked at from different perspectives or "views". The data is represented in the form of a tensor, which is like a multi-dimensional array. The key idea behind S²MVTC is to find a way to effectively cluster this multi-view tensor data in a simple and efficient manner, without requiring a lot of computational power.
The method works by first reducing the dimensionality of the data, making it easier to process, and then iteratively updating the clustering assignments. This allows the algorithm to scale well to large datasets, unlike some previous approaches that may have been more complex and resource-intensive. By focusing on simplicity and efficiency, the researchers hope S²MVTC can be a useful tool for analyzing and understanding multi-view data in a wide range of applications.
Technical Explanation
S²MVTC is a novel multi-view tensor clustering algorithm that aims to be both simple and scalable. The method first performs dimensionality reduction on the input tensor data, compressing the information into a more manageable form. It then iteratively updates the cluster assignments, alternating between estimating the cluster centroids and assigning data points to clusters.
The key innovations of S²MVTC include:
- An efficient dimensionality reduction step that preserves the multi-view structure of the data
- A scalable iterative clustering algorithm that can handle large-scale multi-view tensors
- A flexible framework that can incorporate different loss functions and optimization approaches
Experiments on several real-world datasets demonstrate the effectiveness of S²MVTC compared to state-of-the-art multi-view clustering methods, in terms of clustering accuracy and computational efficiency. The results suggest S²MVTC is a promising approach for tackling complex multi-view data analysis tasks.
Critical Analysis
The authors acknowledge several limitations of the S²MVTC method. First, the dimensionality reduction step relies on a specific tensor decomposition technique, which may not be optimal for all types of multi-view data. Exploring alternative dimensionality reduction strategies could potentially improve the algorithm's performance.
Additionally, the iterative clustering updates assume the cluster centroids are fixed during each iteration, which may not always be the most accurate representation of the data. Relaxing this assumption or incorporating more flexible clustering models could be an area for future research.
Overall, S²MVTC represents a significant step forward in the field of multi-view tensor clustering, balancing simplicity, scalability, and performance. However, as with any algorithm, there is room for further refinement and exploration of more advanced techniques to address the specific challenges of multi-view data analysis.
Conclusion
The S²MVTC algorithm proposed in this paper offers a simple yet efficient approach to clustering multi-view tensor data. By focusing on dimensionality reduction and scalable iterative clustering, the method can effectively analyze large-scale, complex datasets without excessive computational requirements.
The results demonstrate the potential of S²MVTC to serve as a valuable tool for a wide range of applications involving multi-view data, from computer vision to social network analysis. As the volume and complexity of data continues to grow, the need for sophisticated yet practical clustering algorithms like S²MVTC will only increase, making this research an important contribution to the field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Tensor-based Graph Learning with Consistency and Specificity for Multi-view Clustering
Long Shi, Lei Cao, Yunshan Ye, Yu Zhao, Badong Chen
0
0
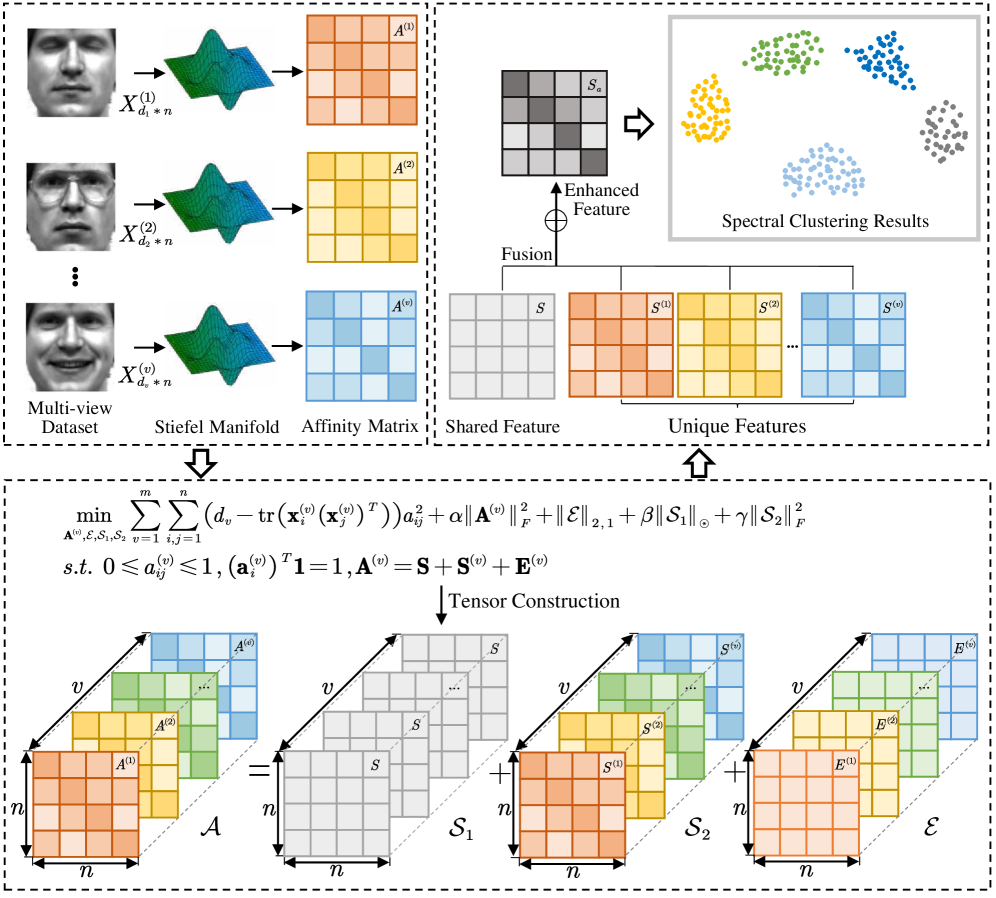
In the context of multi-view clustering, graph learning is recognized as a crucial technique, which generally involves constructing an adaptive neighbor graph based on probabilistic neighbors, and then learning a consensus graph to for clustering. However, they are confronted with two limitations. Firstly, they often rely on Euclidean distance to measure similarity when constructing the adaptive neighbor graph, which proves inadequate in capturing the intrinsic structure among data points in practice. Secondly, most of these methods focus solely on consensus graph, ignoring unique information from each view. Although a few graph-based studies have considered using specific information as well, the modelling approach employed does not exclude the noise impact from the specific component. To this end, we propose a novel tensor-based multi-view graph learning framework that simultaneously considers consistency and specificity, while effectively eliminating the influence of noise. Specifically, we calculate similarity distance on the Stiefel manifold to preserve the intrinsic properties of data. By making an assumption that the learned neighbor graph of each view comprises a consistent part, a specific part, and a noise part, we formulate a new tensor-based target graph learning paradigm for noise-free graph fusion. Owing to the benefits of tensor singular value decomposition (t-SVD) in uncovering high-order correlations, this model is capable of achieving a complete understanding of the target graph. Furthermore, we derive an algorithm to address the optimization problem. Experiments on six datasets have demonstrated the superiority of our method. We have released the source code on https://github.com/lshi91/CSTGL-Code.
4/4/2024
Anchor-based Multi-view Subspace Clustering with Hierarchical Feature Descent
Qiyuan Ou, Siwei Wang, Pei Zhang, Sihang Zhou, En Zhu
0
0
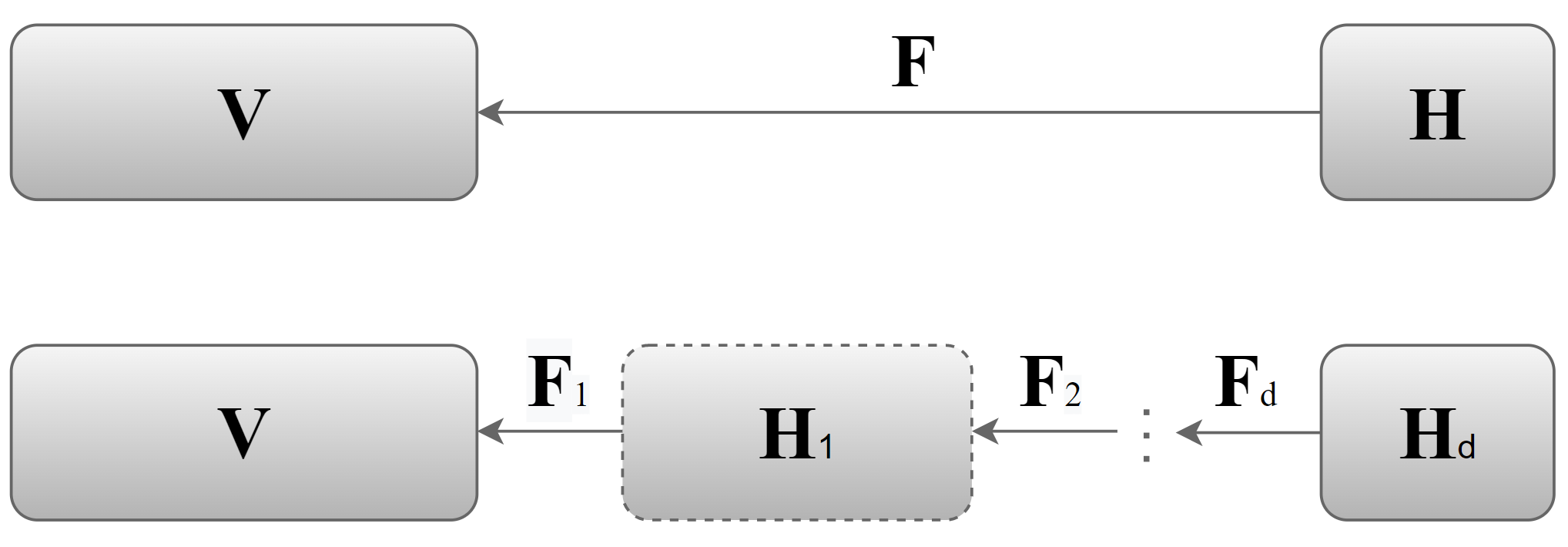
Multi-view clustering has attracted growing attention owing to its capabilities of aggregating information from various sources and its promising horizons in public affairs. Up till now, many advanced approaches have been proposed in recent literature. However, there are several ongoing difficulties to be tackled. One common dilemma occurs while attempting to align the features of different views. {Moreover, due to the fact that many existing multi-view clustering algorithms stem from spectral clustering, this results to cubic time complexity w.r.t. the number of dataset. However, we propose Anchor-based Multi-view Subspace Clustering with Hierarchical Feature Descent(MVSC-HFD) to tackle the discrepancy among views through hierarchical feature descent and project to a common subspace( STAGE 1), which reveals dependency of different views. We further reduce the computational complexity to linear time cost through a unified sampling strategy in the common subspace( STAGE 2), followed by anchor-based subspace clustering to learn the bipartite graph collectively( STAGE 3). }Extensive experimental results on public benchmark datasets demonstrate that our proposed model consistently outperforms the state-of-the-art techniques.
4/10/2024
Rectified Gaussian kernel multi-view k-means clustering
Kristina P. Sinaga
0
0
In this paper, we show two new variants of multi-view k-means (MVKM) algorithms to address multi-view data. The general idea is to outline the distance between $h$-th view data points $x_i^h$ and $h$-th view cluster centers $a_k^h$ in a different manner of centroid-based approach. Unlike other methods, our proposed methods learn the multi-view data by calculating the similarity using Euclidean norm in the space of Gaussian-kernel, namely as multi-view k-means with exponent distance (MVKM-ED). By simultaneously aligning the stabilizer parameter $p$ and kernel coefficients $beta^h$, the compression of Gaussian-kernel based weighted distance in Euclidean norm reduce the sensitivity of MVKM-ED. To this end, this paper designated as Gaussian-kernel multi-view k-means (GKMVKM) clustering algorithm. Numerical evaluation of five real-world multi-view data demonstrates the robustness and efficiency of our proposed MVKM-ED and GKMVKM approaches.
5/17/2024
Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Stereo
Tianqi Liu, Guangcong Wang, Shoukang Hu, Liao Shen, Xinyi Ye, Yuhang Zang, Zhiguo Cao, Wei Li, Ziwei Liu
0
0
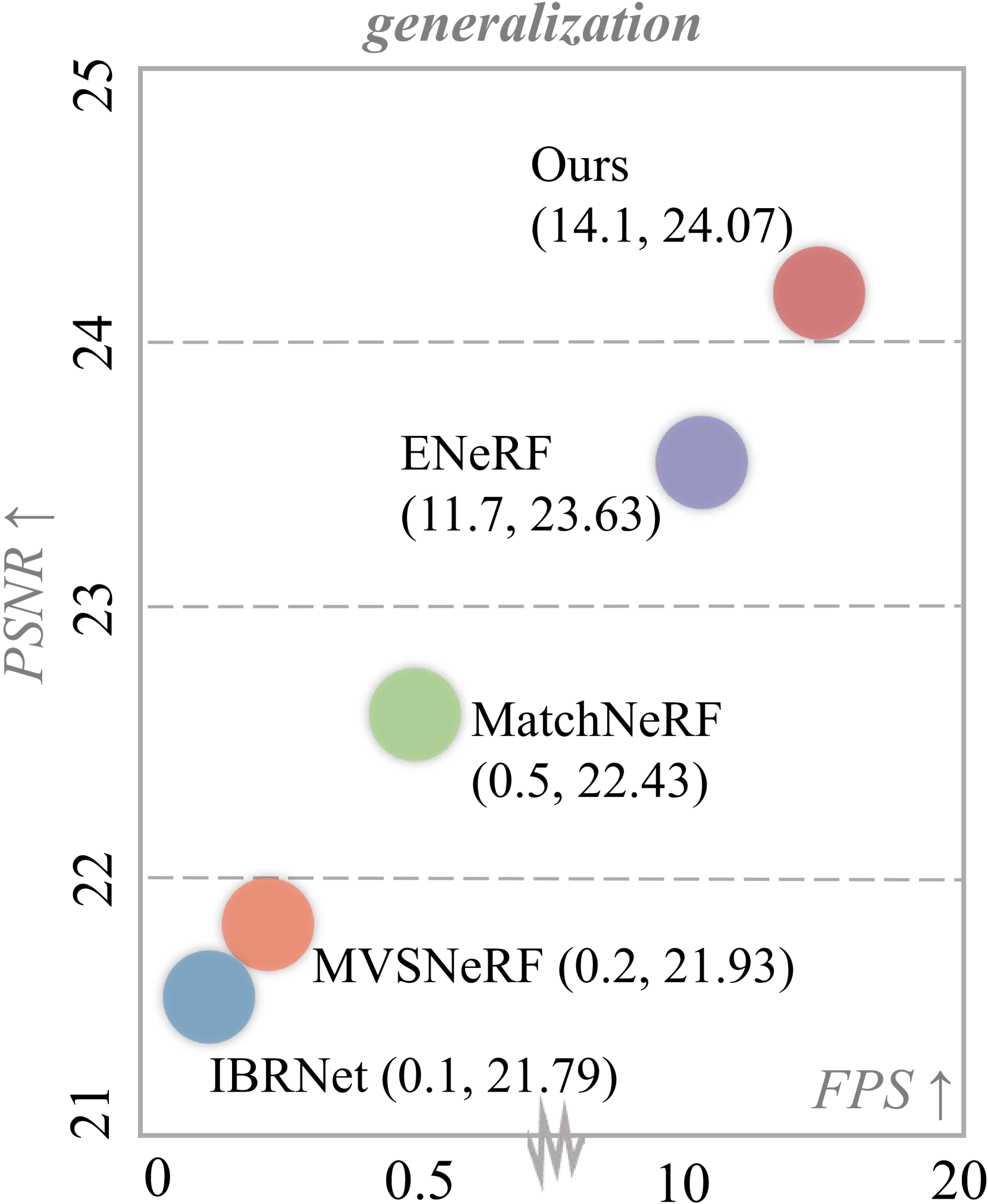
We present MVSGaussian, a new generalizable 3D Gaussian representation approach derived from Multi-View Stereo (MVS) that can efficiently reconstruct unseen scenes. Specifically, 1) we leverage MVS to encode geometry-aware Gaussian representations and decode them into Gaussian parameters. 2) To further enhance performance, we propose a hybrid Gaussian rendering that integrates an efficient volume rendering design for novel view synthesis. 3) To support fast fine-tuning for specific scenes, we introduce a multi-view geometric consistent aggregation strategy to effectively aggregate the point clouds generated by the generalizable model, serving as the initialization for per-scene optimization. Compared with previous generalizable NeRF-based methods, which typically require minutes of fine-tuning and seconds of rendering per image, MVSGaussian achieves real-time rendering with better synthesis quality for each scene. Compared with the vanilla 3D-GS, MVSGaussian achieves better view synthesis with less training computational cost. Extensive experiments on DTU, Real Forward-facing, NeRF Synthetic, and Tanks and Temples datasets validate that MVSGaussian attains state-of-the-art performance with convincing generalizability, real-time rendering speed, and fast per-scene optimization.
5/21/2024