Towards Robust Few-shot Class Incremental Learning in Audio Classification using Contrastive Representation

0

Sign in to get full access
Overview
- Explores a method for improving audio classification in a class-incremental learning setting using contrastive representation learning
- Focuses on the challenge of learning new audio classes while maintaining performance on previously learned classes
- Proposes a novel approach that leverages contrastive learning to build robust representations that can adapt to new classes
Plain English Explanation
This research paper introduces a new approach to class-incremental learning for audio classification. The key challenge in this area is to teach an AI system to recognize new sound classes (e.g., a new type of bird call) without forgetting what it has already learned (e.g., other bird calls).
The researchers' solution is to use contrastive learning - a technique that encourages the AI to build robust representations of audio signals. By training the system to compare and contrast different sound samples, it learns features that are more general and adaptable.
This allows the AI to more easily incorporate new sound classes into its existing knowledge, without catastrophically forgetting the old classes. The researchers show that this contrastive approach outperforms other class-incremental learning methods for audio classification tasks, particularly in few-shot learning scenarios where only a small number of examples are available for new classes.
Technical Explanation
The paper proposes a Bayesian learning-driven Prototypical Contrastive Loss (BLPCL) framework for class-incremental audio classification. The key components are:
-
Contrastive Representation Learning: The model is trained to learn audio representations that maximize the similarity between samples from the same class and minimize the similarity between samples from different classes. This builds robust, generalizable features.
-
Bayesian Learning-Driven Prototypes: The model maintains a set of class prototypes that are updated in a Bayesian manner as new classes are learned. This allows the model to adapt its understanding of each class over time.
-
Few-Shot Class Incremental Learning: The model is designed to efficiently learn new audio classes from only a few examples, by leveraging the contrastive representations and Bayesian prototypes.
The researchers evaluate their approach on several audio classification datasets, including ESC-50 and FSD50K. They demonstrate significant performance improvements over other class-incremental learning methods, especially in few-shot scenarios.
Critical Analysis
The paper makes a strong case for the benefits of contrastive learning in the context of class-incremental audio classification. The proposed BLPCL framework appears to be a promising approach for overcoming the catastrophic forgetting problem that often arises in these types of learning scenarios.
However, the paper does not discuss some potential limitations or areas for further research:
- Scalability: It's unclear how well the BLPCL framework would scale to learning a very large number of audio classes over time. The computational and memory requirements may become prohibitive.
- Interpretability: The paper does not provide much insight into the learned audio representations or how the Bayesian prototypes evolve. More interpretability could help understand the model's inner workings.
- Real-world Applicability: The experiments are conducted on curated audio datasets, but the performance on more complex, real-world audio data remains to be seen.
Overall, the research represents an important step forward in few-shot class incremental learning for audio, but further work may be needed to fully realize the potential of this approach.
Conclusion
This paper presents a novel framework for class-incremental audio classification that leverages contrastive representation learning and Bayesian prototypes. The results demonstrate significant improvements over existing methods, especially in few-shot learning scenarios.
The proposed approach shows promise for building audio AI systems that can continually adapt to new sound classes without forgetting previous knowledge. This could have important applications in areas like environmental monitoring, assistive technology, and audio analysis.
However, further research is needed to address scalability, interpretability, and real-world performance challenges. Continued advancements in this area could lead to more flexible and robust audio classification systems that can keep pace with the ever-changing acoustic environments we live in.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Robust Few-shot Class Incremental Learning in Audio Classification using Contrastive Representation
Riyansha Singh, Parinita Nema, Vinod K Kurmi
In machine learning applications, gradual data ingress is common, especially in audio processing where incremental learning is vital for real-time analytics. Few-shot class-incremental learning addresses challenges arising from limited incoming data. Existing methods often integrate additional trainable components or rely on a fixed embedding extractor post-training on base sessions to mitigate concerns related to catastrophic forgetting and the dangers of model overfitting. However, using cross-entropy loss alone during base session training is suboptimal for audio data. To address this, we propose incorporating supervised contrastive learning to refine the representation space, enhancing discriminative power and leading to better generalization since it facilitates seamless integration of incremental classes, upon arrival. Experimental results on NSynth and LibriSpeech datasets with 100 classes, as well as ESC dataset with 50 and 10 classes, demonstrate state-of-the-art performance.
Read more8/9/2024
0
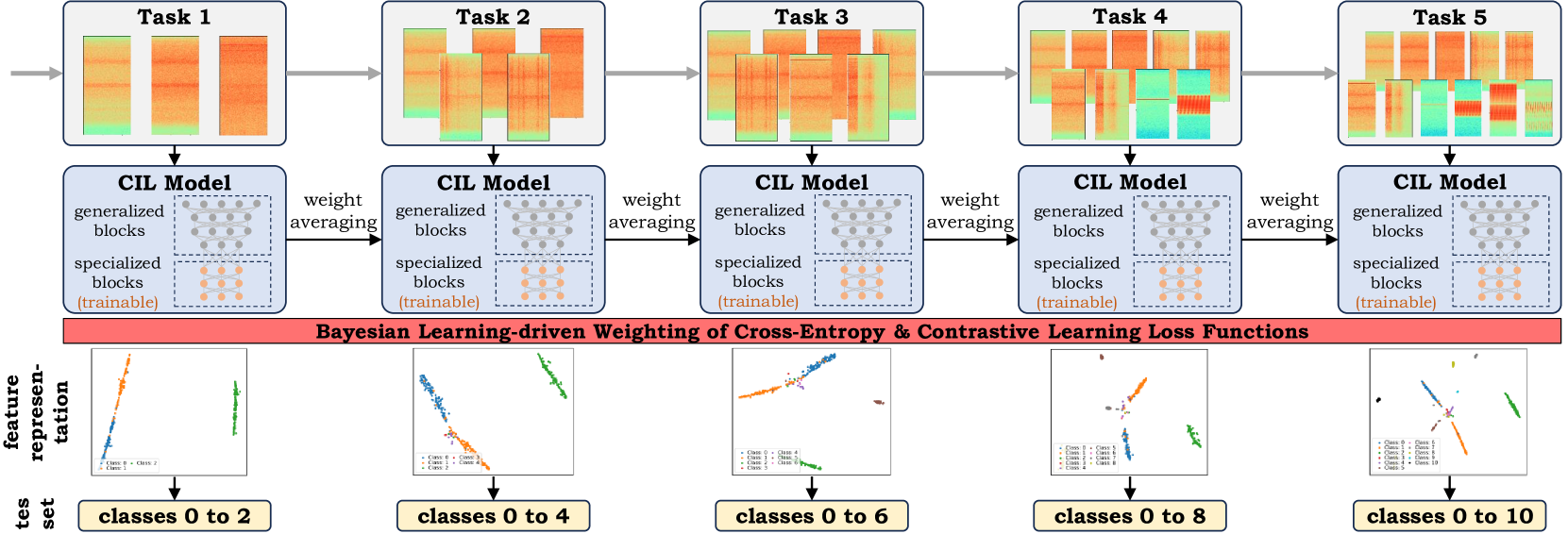
Bayesian Learning-driven Prototypical Contrastive Loss for Class-Incremental Learning
Nisha L. Raichur, Lucas Heublein, Tobias Feigl, Alexander Rugamer, Christopher Mutschler, Felix Ott
The primary objective of methods in continual learning is to learn tasks in a sequential manner over time from a stream of data, while mitigating the detrimental phenomenon of catastrophic forgetting. In this paper, we focus on learning an optimal representation between previous class prototypes and newly encountered ones. We propose a prototypical network with a Bayesian learning-driven contrastive loss (BLCL) tailored specifically for class-incremental learning scenarios. Therefore, we introduce a contrastive loss that incorporates new classes into the latent representation by reducing the intra-class distance and increasing the inter-class distance. Our approach dynamically adapts the balance between the cross-entropy and contrastive loss functions with a Bayesian learning technique. Empirical evaluations conducted on both the CIFAR-10 and CIFAR-100 dataset for image classification and images of a GNSS-based dataset for interference classification validate the efficacy of our method, showcasing its superiority over existing state-of-the-art approaches.
Read more7/15/2024
✨
0
Feature Expansion and enhanced Compression for Class Incremental Learning
Quentin Ferdinand (ENSTA Bretagne, Lab-STICC_MATRIX), Gilles Le Chenadec (ENSTA Bretagne, Lab-STICC_MATRIX), Benoit Clement (CROSSING, ENSTA Bretagne, Lab-STICC_MATRIX), Panagiotis Papadakis (Lab-STICC_RAMBO, IMT Atlantique - INFO), Quentin Oliveau
Class incremental learning consists in training discriminative models to classify an increasing number of classes over time. However, doing so using only the newly added class data leads to the known problem of catastrophic forgetting of the previous classes. Recently, dynamic deep learning architectures have been shown to exhibit a better stability-plasticity trade-off by dynamically adding new feature extractors to the model in order to learn new classes followed by a compression step to scale the model back to its original size, thus avoiding a growing number of parameters. In this context, we propose a new algorithm that enhances the compression of previous class knowledge by cutting and mixing patches of previous class samples with the new images during compression using our Rehearsal-CutMix method. We show that this new data augmentation reduces catastrophic forgetting by specifically targeting past class information and improving its compression. Extensive experiments performed on the CIFAR and ImageNet datasets under diverse incremental learning evaluation protocols demonstrate that our approach consistently outperforms the state-of-the-art . The code will be made available upon publication of our work.
Read more5/15/2024
0
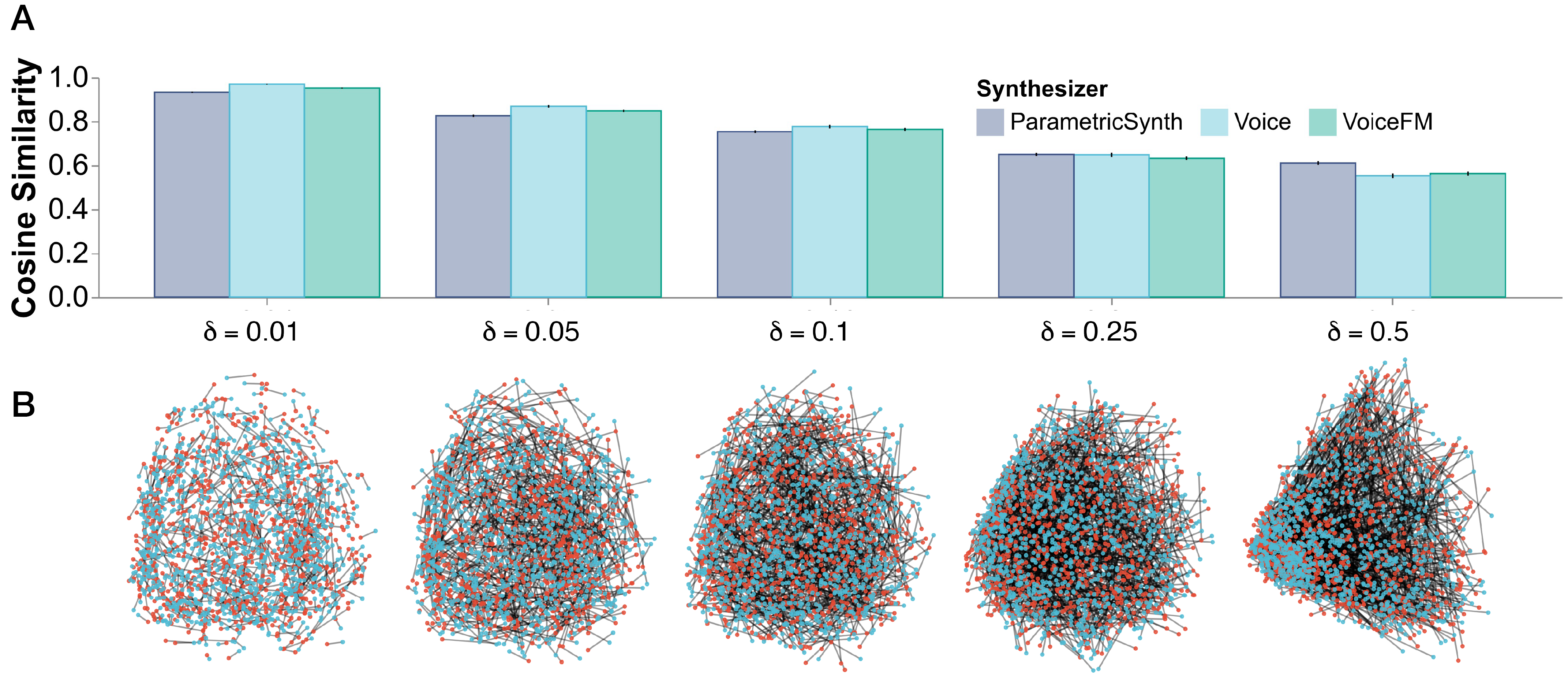
Contrastive Learning from Synthetic Audio Doppelgangers
Manuel Cherep, Nikhil Singh
Learning robust audio representations currently demands extensive datasets of real-world sound recordings. By applying artificial transformations to these recordings, models can learn to recognize similarities despite subtle variations through techniques like contrastive learning. However, these transformations are only approximations of the true diversity found in real-world sounds, which are generated by complex interactions of physical processes, from vocal cord vibrations to the resonance of musical instruments. We propose a solution to both the data scale and transformation limitations, leveraging synthetic audio. By randomly perturbing the parameters of a sound synthesizer, we generate audio doppelgangers-synthetic positive pairs with causally manipulated variations in timbre, pitch, and temporal envelopes. These variations, difficult to achieve through transformations of existing audio, provide a rich source of contrastive information. Despite the shift to randomly generated synthetic data, our method produces strong representations, competitive with real data on standard audio classification benchmarks. Notably, our approach is lightweight, requires no data storage, and has only a single hyperparameter, which we extensively analyze. We offer this method as a complement to existing strategies for contrastive learning in audio, using synthesized sounds to reduce the data burden on practitioners.
Read more6/11/2024