Online DPO: Online Direct Preference Optimization with Fast-Slow Chasing
2406.05534
0
0

Abstract
Direct Preference Optimization (DPO) improves the alignment of large language models (LLMs) with human values by training directly on human preference datasets, eliminating the need for reward models. However, due to the presence of cross-domain human preferences, direct continual training can lead to catastrophic forgetting, limiting DPO's performance and efficiency. Inspired by intraspecific competition driving species evolution, we propose a Online Fast-Slow chasing DPO (OFS-DPO) for preference alignment, simulating competition through fast and slow chasing among models to facilitate rapid adaptation. Specifically, we first derive the regret upper bound for online learning, validating our motivation with a min-max optimization pattern. Based on this, we introduce two identical modules using Low-rank Adaptive (LoRA) with different optimization speeds to simulate intraspecific competition, and propose a new regularization term to guide their learning. To further mitigate catastrophic forgetting in cross-domain scenarios, we extend the OFS-DPO with LoRA modules combination strategy, resulting in the Cross domain Online Fast-Slow chasing DPO (COFS-DPO). This method leverages linear combinations of fast modules parameters from different task domains, fully utilizing historical information to achive continual value alignment. Experimental results show that OFS-DPO outperforms DPO in in-domain alignment, while COFS-DPO excels in cross-domain continual learning scenarios.
Create account to get full access
Overview
- This paper introduces "Online Direct Preference Optimization with Fast-Slow Chasing" (Online DPO), a novel approach to direct preference optimization for training large language models.
- Online DPO uses a "fast-slow" chasing technique to efficiently optimize the model's parameters to match a user's preferences, without the need for explicit reward functions.
- The paper demonstrates the effectiveness of Online DPO on a variety of tasks, including fine-tuning large language models and simple preference optimization.
Plain English Explanation
Online DPO is a technique for training large language models to behave in a way that aligns with a user's preferences, without the need for complex reward functions. Instead of explicitly defining what the model should do, the method uses a "fast-slow" chasing approach to efficiently optimize the model's parameters to match the user's preferences.
The "fast-slow" chasing technique involves two separate optimization processes: a "fast" process that quickly adapts the model to the user's preferences, and a "slow" process that gradually updates the model's underlying parameters to maintain the desired behavior over time. This approach allows the model to adapt quickly to the user's preferences while also ensuring that the learned behavior is stable and consistent.
One key advantage of Online DPO is that it can be used to fine-tune large language models to match a user's specific preferences, without the need for extensive retraining or explicit reward functions. This makes it a powerful tool for customizing the behavior of AI systems to suit the needs and preferences of individual users.
Another application of Online DPO is simple preference optimization, where the method can be used to optimize the behavior of AI systems without relying on complex reward functions or reference data. This can be particularly useful in scenarios where it is difficult to define explicit rewards or where the desired behavior is difficult to specify in advance.
Technical Explanation
The Online DPO algorithm works by maintaining two separate optimization processes: a "fast" process that quickly adapts the model's behavior to match the user's preferences, and a "slow" process that gradually updates the model's underlying parameters to maintain the desired behavior over time.
The fast process uses a technique called "chasing" to quickly align the model's outputs with the user's preferences. This involves continuously updating the model's parameters to minimize the distance between the model's outputs and the user's preferred outputs, as indicated by their feedback or actions.
The slow process, on the other hand, is responsible for updating the model's underlying parameters to ensure that the learned behavior is stable and consistent over time. This process uses a more gradual optimization approach, such as stochastic gradient descent, to update the model's parameters in a way that preserves the desired behavior while also allowing the model to continue learning and adapting.
The combination of the fast and slow processes allows Online DPO to efficiently optimize the model's parameters to match the user's preferences, without the need for explicit reward functions or extensive retraining. This makes the method particularly useful for fine-tuning large language models or simple preference optimization tasks, where traditional approaches may be less effective or more computationally intensive.
Critical Analysis
The paper presents a promising approach to direct preference optimization, but it also acknowledges several limitations and areas for further research.
One potential concern is the stability of the learned behavior over time. While the slow process is designed to maintain the desired behavior, it is not clear how well the model would perform in the face of changing user preferences or long-term drift in the underlying data distribution. Further research may be needed to better understand the long-term stability and robustness of the learned behavior.
Another potential issue is the scalability of the approach, particularly for very large language models or complex preference optimization tasks. The paper demonstrates the effectiveness of Online DPO on a variety of tasks, but it is not clear how well the method would scale to even larger or more complex models and datasets. Filtered direct preference optimization may be one approach to address this challenge.
Overall, the Online DPO method presents an interesting and promising approach to direct preference optimization, with potential applications in a wide range of AI systems and tasks. However, further research and experimentation will be needed to fully understand the limitations and potential of this approach.
Conclusion
The Online DPO method introduced in this paper offers a novel approach to direct preference optimization for training large language models. By using a "fast-slow" chasing technique, the method can efficiently optimize the model's parameters to match a user's preferences, without the need for explicit reward functions or extensive retraining.
The paper demonstrates the effectiveness of Online DPO on a variety of tasks, including fine-tuning large language models and simple preference optimization. The method's ability to customize the behavior of AI systems to suit individual user preferences makes it a potentially valuable tool for a wide range of applications.
While the paper acknowledges several limitations and areas for further research, the Online DPO approach represents an important step forward in the development of more flexible and user-centric AI systems. As the field of AI continues to evolve, techniques like Online DPO may play an increasingly important role in shaping the way these systems are designed and deployed.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Direct Preference Optimization with an Offset
Afra Amini, Tim Vieira, Ryan Cotterell
0
0
Direct preference optimization (DPO) is a successful fine-tuning strategy for aligning large language models with human preferences without the need to train a reward model or employ reinforcement learning. DPO, as originally formulated, relies on binary preference data and fine-tunes a language model to increase the likelihood of a preferred response over a dispreferred response. However, not all preference pairs are equal. Sometimes, the preferred response is only slightly better than the dispreferred one. In other cases, the preference is much stronger. For instance, if a response contains harmful or toxic content, the annotator will have a strong preference for that response. In this paper, we propose a generalization of DPO, termed DPO with an offset (ODPO), that does not treat every preference pair equally during fine-tuning. Intuitively, ODPO requires the difference between the likelihood of the preferred and dispreferred response to be greater than an offset value. The offset is determined based on the extent to which one response is preferred over another. Our experiments on various tasks suggest that ODPO significantly outperforms DPO in aligning language models, especially when the number of preference pairs is limited.
6/7/2024
Mallows-DPO: Fine-Tune Your LLM with Preference Dispersions
Haoxian Chen, Hanyang Zhao, Henry Lam, David Yao, Wenpin Tang
0
0
Direct Preference Optimization (DPO) has recently emerged as a popular approach to improve reinforcement learning with human feedback (RLHF), leading to better techniques to fine-tune large language models (LLM). A weakness of DPO, however, lies in its lack of capability to characterize the diversity of human preferences. Inspired by Mallows' theory of preference ranking, we develop in this paper a new approach, the Mallows-DPO. A distinct feature of this approach is a dispersion index, which reflects the dispersion of human preference to prompts. We show that existing DPO models can be reduced to special cases of this dispersion index, thus unified with Mallows-DPO. More importantly, we demonstrate (empirically) how to use this dispersion index to enhance the performance of DPO in a broad array of benchmark tasks, from synthetic bandit selection to controllable generations and dialogues, while maintaining great generalization capabilities.
5/27/2024
🛠️
SimPO: Simple Preference Optimization with a Reference-Free Reward
Yu Meng, Mengzhou Xia, Danqi Chen
0
0
Direct Preference Optimization (DPO) is a widely used offline preference optimization algorithm that reparameterizes reward functions in reinforcement learning from human feedback (RLHF) to enhance simplicity and training stability. In this work, we propose SimPO, a simpler yet more effective approach. The effectiveness of SimPO is attributed to a key design: using the average log probability of a sequence as the implicit reward. This reward formulation better aligns with model generation and eliminates the need for a reference model, making it more compute and memory efficient. Additionally, we introduce a target reward margin to the Bradley-Terry objective to encourage a larger margin between the winning and losing responses, further enhancing the algorithm's performance. We compare SimPO to DPO and its latest variants across various state-of-the-art training setups, including both base and instruction-tuned models like Mistral and Llama3. We evaluated on extensive instruction-following benchmarks, including AlpacaEval 2, MT-Bench, and the recent challenging Arena-Hard benchmark. Our results demonstrate that SimPO consistently and significantly outperforms existing approaches without substantially increasing response length. Specifically, SimPO outperforms DPO by up to 6.4 points on AlpacaEval 2 and by up to 7.5 points on Arena-Hard. Our top-performing model, built on Llama3-8B-Instruct, achieves a remarkable 44.7 length-controlled win rate on AlpacaEval 2 -- surpassing Claude 3 Opus on the leaderboard, and a 33.8 win rate on Arena-Hard -- making it the strongest 8B open-source model.
5/24/2024
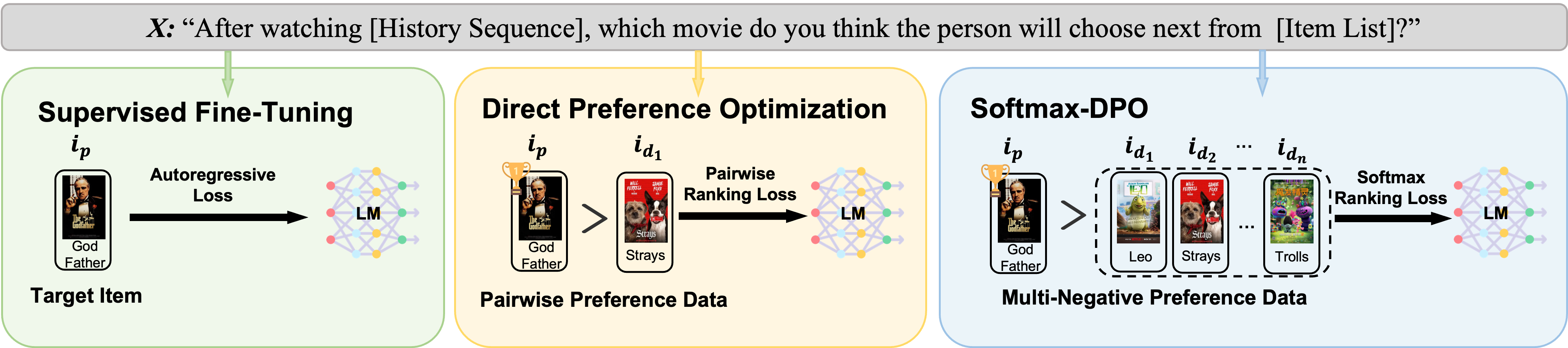
On Softmax Direct Preference Optimization for Recommendation
Yuxin Chen, Junfei Tan, An Zhang, Zhengyi Yang, Leheng Sheng, Enzhi Zhang, Xiang Wang, Tat-Seng Chua
0
0
Recommender systems aim to predict personalized rankings based on user preference data. With the rise of Language Models (LMs), LM-based recommenders have been widely explored due to their extensive world knowledge and powerful reasoning abilities. Most of the LM-based recommenders convert historical interactions into language prompts, pairing with a positive item as the target response and fine-tuning LM with a language modeling loss. However, the current objective fails to fully leverage preference data and is not optimized for personalized ranking tasks, which hinders the performance of LM-based recommenders. Inspired by the current advancement of Direct Preference Optimization (DPO) in human preference alignment and the success of softmax loss in recommendations, we propose Softmax-DPO (S-DPO) to instill ranking information into the LM to help LM-based recommenders distinguish preferred items from negatives, rather than solely focusing on positives. Specifically, we incorporate multiple negatives in user preference data and devise an alternative version of DPO loss tailored for LM-based recommenders, connected to softmax sampling strategies. Theoretically, we bridge S-DPO with the softmax loss over negative sampling and find that it has a side effect of mining hard negatives, which assures its exceptional capabilities in recommendation tasks. Empirically, extensive experiments conducted on three real-world datasets demonstrate the superiority of S-DPO to effectively model user preference and further boost recommendation performance while mitigating the data likelihood decline issue of DPO. Our codes are available at https://github.com/chenyuxin1999/S-DPO.
6/17/2024