Online Self-Preferring Language Models
2405.14103
0
0
💬
Abstract
Aligning with human preference datasets has been critical to the success of large language models (LLMs). Reinforcement learning from human feedback (RLHF) employs a costly reward model to provide feedback for on-policy sampling responses. Recently, offline methods that directly fit responses with binary preferences in the dataset have emerged as alternatives. However, existing methods do not explicitly model preference strength information, which is crucial for distinguishing different response pairs. To overcome this limitation, we propose Online Self-Preferring (OSP) language models to learn from self-generated response pairs and self-judged preference strengths. For each prompt and corresponding self-generated responses, we introduce a ranked pairing method to construct multiple response pairs with preference strength information. We then propose the soft-preference cross-entropy loss to leverage such information. Empirically, we demonstrate that leveraging preference strength is crucial for avoiding overfitting and enhancing alignment performance. OSP achieves state-of-the-art alignment performance across various metrics in two widely used human preference datasets. OSP is parameter-efficient and more robust than the dominant online method, RLHF when limited offline data are available and generalizing to out-of-domain tasks. Moreover, OSP language models established by LLMs with proficiency in self-preferring can efficiently self-improve without external supervision.
Create account to get full access
Overview
- Aligning large language models (LLMs) with human preferences has been a critical factor in their success.
- Reinforcement learning from human feedback (RLHF) uses a costly reward model to provide feedback for on-policy sampling responses.
- Offline methods that fit responses directly with binary preferences in the dataset have emerged as alternatives.
- Existing methods do not explicitly model preference strength information, which is crucial for distinguishing different response pairs.
- The paper proposes an approach called Online Self-Preferring (OSP) language models to learn from self-generated response pairs and self-judged preference strengths.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly powerful, but to be truly useful, they need to align with human preferences. Reinforcement learning from human feedback (RLHF) is one way to do this, but it's expensive and requires a lot of human input.
Some researchers have tried simpler offline methods that directly match the language model's responses to human preferences in a dataset. But these approaches don't take into account how strongly people prefer one response over another, which is really important for understanding what humans want.
To address this, the researchers developed a new approach called Online Self-Preferring (OSP) language models. The key idea is to have the language model generate its own responses, and then judge how much it prefers each response compared to the others. This allows the model to learn about human preferences without needing as much external feedback.
The researchers show that this approach is more efficient and robust than RLHF, especially when there's limited human feedback data available. It also allows the language model to continuously improve itself without relying on humans. This could be a big step towards aligning powerful AI systems with human values in a scalable way.
Technical Explanation
The paper proposes an Online Self-Preferring (OSP) approach to align large language models (LLMs) with human preferences. Unlike previous offline methods that directly fit responses to binary preferences in a dataset, OSP models learn from self-generated response pairs and self-judged preference strengths.
For each prompt, the model generates multiple responses and uses a ranked pairing method to construct response pairs with associated preference strengths. This allows the model to learn from nuanced preference information, rather than just binary labels. The researchers then introduce a "soft-preference cross-entropy loss" to leverage this preference strength data during training.
Empirically, the paper demonstrates that modeling preference strength is crucial for avoiding overfitting and enhancing alignment performance. OSP achieves state-of-the-art results on two widely used human preference datasets, outperforming the dominant online RLHF method.
Importantly, OSP is more parameter-efficient and robust than RLHF, especially when limited offline data is available or when generalizing to out-of-domain tasks. The paper also shows that OSP language models can efficiently self-improve without external supervision, by leveraging their own self-preferring capabilities.
Critical Analysis
The paper makes a compelling case for the importance of modeling preference strength information when aligning LLMs with human values. The proposed OSP approach represents a significant advance over previous offline methods that rely on binary preferences.
However, the paper does not address certain limitations of the self-preferring approach. For example, there may be biases and inconsistencies in how the language model judges its own responses, which could lead to suboptimal learning. Prior research has highlighted the challenges of relying solely on self-generated data for preference learning.
Additionally, the paper does not explore the potential risks or downsides of language models continuously self-improving without external oversight. There may be concerns about such models diverging from human values or developing unintended behaviors over time.
Overall, the OSP approach is a promising step forward, but further research is needed to understand its limitations and ensure the safe and responsible development of self-aligning language models.
Conclusion
The paper presents a novel Online Self-Preferring (OSP) approach to aligning large language models (LLMs) with human preferences. By leveraging self-generated response pairs and self-judged preference strengths, OSP can learn nuanced preference information more efficiently and robustly than previous methods.
This research represents an important advancement in the field of AI alignment, as it moves towards scalable techniques for imbuing powerful language models with human values. The ability of OSP models to continuously self-improve without external supervision is especially intriguing, as it could lead to more autonomous and adaptable AI systems.
However, the paper also highlights the need for further exploration of the potential risks and limitations of such self-aligning approaches. Ongoing research and careful development will be crucial to ensuring that these powerful language models remain aligned with human preferences and societal interests as they become increasingly capable and influential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Self-Play Preference Optimization for Language Model Alignment
Yue Wu, Zhiqing Sun, Huizhuo Yuan, Kaixuan Ji, Yiming Yang, Quanquan Gu
0
0
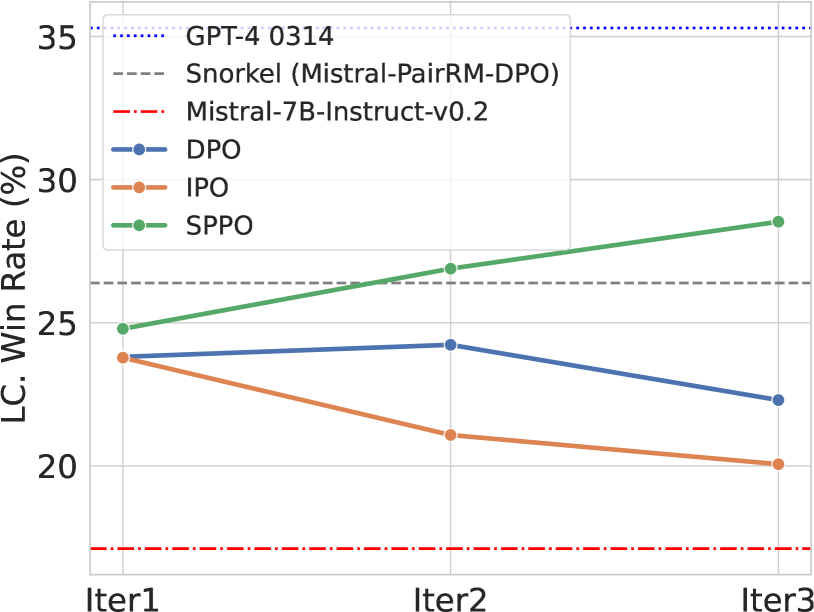
Traditional reinforcement learning from human feedback (RLHF) approaches relying on parametric models like the Bradley-Terry model fall short in capturing the intransitivity and irrationality in human preferences. Recent advancements suggest that directly working with preference probabilities can yield a more accurate reflection of human preferences, enabling more flexible and accurate language model alignment. In this paper, we propose a self-play-based method for language model alignment, which treats the problem as a constant-sum two-player game aimed at identifying the Nash equilibrium policy. Our approach, dubbed Self-Play Preference Optimization (SPPO), approximates the Nash equilibrium through iterative policy updates and enjoys a theoretical convergence guarantee. Our method can effectively increase the log-likelihood of the chosen response and decrease that of the rejected response, which cannot be trivially achieved by symmetric pairwise loss such as Direct Preference Optimization (DPO) and Identity Preference Optimization (IPO). In our experiments, using only 60k prompts (without responses) from the UltraFeedback dataset and without any prompt augmentation, by leveraging a pre-trained preference model PairRM with only 0.4B parameters, SPPO can obtain a model from fine-tuning Mistral-7B-Instruct-v0.2 that achieves the state-of-the-art length-controlled win-rate of 28.53% against GPT-4-Turbo on AlpacaEval 2.0. It also outperforms the (iterative) DPO and IPO on MT-Bench and the Open LLM Leaderboard. Starting from a stronger base model Llama-3-8B-Instruct, we are able to achieve a length-controlled win rate of 38.77%. Notably, the strong performance of SPPO is achieved without additional external supervision (e.g., responses, preferences, etc.) from GPT-4 or other stronger language models. Codes are available at https://github.com/uclaml/SPPO.
6/17/2024

Self-Exploring Language Models: Active Preference Elicitation for Online Alignment
Shenao Zhang, Donghan Yu, Hiteshi Sharma, Ziyi Yang, Shuohang Wang, Hany Hassan, Zhaoran Wang
0
0
Preference optimization, particularly through Reinforcement Learning from Human Feedback (RLHF), has achieved significant success in aligning Large Language Models (LLMs) to adhere to human intentions. Unlike offline alignment with a fixed dataset, online feedback collection from humans or AI on model generations typically leads to more capable reward models and better-aligned LLMs through an iterative process. However, achieving a globally accurate reward model requires systematic exploration to generate diverse responses that span the vast space of natural language. Random sampling from standard reward-maximizing LLMs alone is insufficient to fulfill this requirement. To address this issue, we propose a bilevel objective optimistically biased towards potentially high-reward responses to actively explore out-of-distribution regions. By solving the inner-level problem with the reparameterized reward function, the resulting algorithm, named Self-Exploring Language Models (SELM), eliminates the need for a separate RM and iteratively updates the LLM with a straightforward objective. Compared to Direct Preference Optimization (DPO), the SELM objective reduces indiscriminate favor of unseen extrapolations and enhances exploration efficiency. Our experimental results demonstrate that when finetuned on Zephyr-7B-SFT and Llama-3-8B-Instruct models, SELM significantly boosts the performance on instruction-following benchmarks such as MT-Bench and AlpacaEval 2.0, as well as various standard academic benchmarks in different settings. Our code and models are available at https://github.com/shenao-zhang/SELM.
5/30/2024
SAIL: Self-Improving Efficient Online Alignment of Large Language Models
Mucong Ding, Souradip Chakraborty, Vibhu Agrawal, Zora Che, Alec Koppel, Mengdi Wang, Amrit Bedi, Furong Huang
0
0
Reinforcement Learning from Human Feedback (RLHF) is a key method for aligning large language models (LLMs) with human preferences. However, current offline alignment approaches like DPO, IPO, and SLiC rely heavily on fixed preference datasets, which can lead to sub-optimal performance. On the other hand, recent literature has focused on designing online RLHF methods but still lacks a unified conceptual formulation and suffers from distribution shift issues. To address this, we establish that online LLM alignment is underpinned by bilevel optimization. By reducing this formulation to an efficient single-level first-order method (using the reward-policy equivalence), our approach generates new samples and iteratively refines model alignment by exploring responses and regulating preference labels. In doing so, we permit alignment methods to operate in an online and self-improving manner, as well as generalize prior online RLHF methods as special cases. Compared to state-of-the-art iterative RLHF methods, our approach significantly improves alignment performance on open-sourced datasets with minimal computational overhead.
6/26/2024
💬
Self-Play with Adversarial Critic: Provable and Scalable Offline Alignment for Language Models
Xiang Ji, Sanjeev Kulkarni, Mengdi Wang, Tengyang Xie
0
0
This work studies the challenge of aligning large language models (LLMs) with offline preference data. We focus on alignment by Reinforcement Learning from Human Feedback (RLHF) in particular. While popular preference optimization methods exhibit good empirical performance in practice, they are not theoretically guaranteed to converge to the optimal policy and can provably fail when the data coverage is sparse by classical offline reinforcement learning (RL) results. On the other hand, a recent line of work has focused on theoretically motivated preference optimization methods with provable guarantees, but these are not computationally efficient for large-scale applications like LLM alignment. To bridge this gap, we propose SPAC, a new offline preference optimization method with self-play, inspired by the on-average pessimism technique from the offline RL literature, to be the first provable and scalable approach to LLM alignment. We both provide theoretical analysis for its convergence under single-policy concentrability for the general function approximation setting and demonstrate its competitive empirical performance for LLM alignment on a 7B Mistral model with Open LLM Leaderboard evaluations.
6/7/2024