Open Panoramic Segmentation

0

Sign in to get full access
Overview
• This paper presents a novel approach for open panoramic segmentation, which aims to segment all visible objects in a panoramic image using an open-vocabulary model.
• The key innovations include leveraging large-scale open-vocabulary instance segmentation and developing a framework for adapting these models to panoramic data.
• The proposed method, called PanoRecon, outperforms previous state-of-the-art approaches on challenging panoramic segmentation benchmarks.
Plain English Explanation
The paper describes a new way to automatically identify and label all the objects visible in a 360-degree panoramic image. This is a challenging task because panoramic images capture a very wide field of view, often including many different types of objects.
The key innovation is to leverage large "open-vocabulary" object detection models that have been trained on vast datasets of labeled images. These models can recognize thousands of different object categories, going far beyond the limited set of classes typically used in segmentation tasks.
The researchers developed a framework called PanoRecon that adapts these open-vocabulary models to work effectively on panoramic data. This involves techniques like flattening the 360-degree view into a standard 2D format and handling distortions caused by the wide-angle lens.
By combining powerful open-vocabulary recognition with specialized panoramic processing, the PanoRecon system is able to segment panoramic images with much greater accuracy and detail than previous methods. This could have applications in areas like robotics, autonomous vehicles, and virtual/augmented reality, where understanding the full 360-degree environment is crucial.
Technical Explanation
The paper introduces a novel approach for open panoramic segmentation, which aims to segment all visible objects in a panoramic image using an open-vocabulary model.
The key technical contributions include:
-
Leveraging Open-Vocabulary Instance Segmentation: The method builds on recent progress in large-scale open-vocabulary instance segmentation, adapting these powerful models to work effectively on panoramic data.
-
Panoramic Adaptation Framework: The researchers develop a specialized framework, called PanoRecon, that can adapt open-vocabulary models to handle the unique challenges of panoramic imagery, such as distortion and discontinuities at the image boundaries.
-
Extensive Experiments: The paper presents a thorough empirical evaluation, demonstrating that PanoRecon outperforms previous state-of-the-art approaches on several challenging panoramic segmentation benchmarks.
The core idea is to leverage the impressive capabilities of modern open-vocabulary instance segmentation models, which can recognize thousands of object categories, and adapt them to work effectively on 360-degree panoramic data. This is achieved through a series of specialized processing steps, including flattening the panoramic view, handling distortions, and integrating the outputs of the open-vocabulary model.
The results show that this 3D open-vocabulary panoptic segmentation approach can significantly outperform previous methods, opening up new possibilities for understanding the full 360-degree environment in applications like robotics, autonomous vehicles, and virtual/augmented reality.
Critical Analysis
The paper presents a compelling approach to the challenging problem of open panoramic segmentation, with a sound technical foundation and strong empirical results. However, there are a few potential limitations and areas for further research:
-
Computational Complexity: The adaptation of large open-vocabulary models to panoramic data may incur significant computational overhead, which could limit the real-world applicability of the method, especially for resource-constrained devices.
-
Generalization to Diverse Panoramas: While the experiments cover a range of panoramic datasets, it would be valuable to further explore the method's performance on an even wider variety of panoramic data, including those captured in more diverse environments and conditions.
-
Robustness to Noise and Occlusions: The paper does not extensively address the method's robustness to common challenges in panoramic imagery, such as sensor noise, lighting variations, and partial occlusions of objects. Investigating these aspects could further strengthen the practical utility of the approach.
-
Integration with 3D Understanding: The paper focuses on 2D panoramic segmentation, but integrating the method with 3D reconstruction and understanding techniques could unlock even more powerful applications, such as 360-degree visual object tracking and segmentation.
Overall, the paper presents a highly promising and technically sound approach to open panoramic segmentation, with the potential to significantly advance the state of the art in this important computer vision task.
Conclusion
This paper introduces a novel framework for open panoramic segmentation, which leverages powerful open-vocabulary instance segmentation models and specialized techniques for adapting them to work effectively on 360-degree panoramic imagery.
The key innovations include the PanoRecon adaptation framework and the empirical demonstration that this approach can outperform previous state-of-the-art methods on challenging panoramic segmentation benchmarks.
The potential applications of this work are wide-ranging, from robotics and autonomous vehicles to virtual and augmented reality, where a comprehensive understanding of the full 360-degree environment is crucial. While the paper identifies some areas for further research, such as computational complexity and robustness, the proposed method represents a significant step forward in the field of panoramic scene understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Open Panoramic Segmentation
Junwei Zheng, Ruiping Liu, Yufan Chen, Kunyu Peng, Chengzhi Wu, Kailun Yang, Jiaming Zhang, Rainer Stiefelhagen
Panoramic images, capturing a 360{deg} field of view (FoV), encompass omnidirectional spatial information crucial for scene understanding. However, it is not only costly to obtain training-sufficient dense-annotated panoramas but also application-restricted when training models in a close-vocabulary setting. To tackle this problem, in this work, we define a new task termed Open Panoramic Segmentation (OPS), where models are trained with FoV-restricted pinhole images in the source domain in an open-vocabulary setting while evaluated with FoV-open panoramic images in the target domain, enabling the zero-shot open panoramic semantic segmentation ability of models. Moreover, we propose a model named OOOPS with a Deformable Adapter Network (DAN), which significantly improves zero-shot panoramic semantic segmentation performance. To further enhance the distortion-aware modeling ability from the pinhole source domain, we propose a novel data augmentation method called Random Equirectangular Projection (RERP) which is specifically designed to address object deformations in advance. Surpassing other state-of-the-art open-vocabulary semantic segmentation approaches, a remarkable performance boost on three panoramic datasets, WildPASS, Stanford2D3D, and Matterport3D, proves the effectiveness of our proposed OOOPS model with RERP on the OPS task, especially +2.2% on outdoor WildPASS and +2.4% mIoU on indoor Stanford2D3D. The source code is publicly available at https://junweizheng93.github.io/publications/OPS/OPS.html.
Read more7/15/2024

0
Multi-source Domain Adaptation for Panoramic Semantic Segmentation
Jing Jiang, Sicheng Zhao, Jiankun Zhu, Wenbo Tang, Zhaopan Xu, Jidong Yang, Pengfei Xu, Hongxun Yao
Panoramic semantic segmentation has received widespread attention recently due to its comprehensive 360degree field of view. However, labeling such images demands greater resources compared to pinhole images. As a result, many unsupervised domain adaptation methods for panoramic semantic segmentation have emerged, utilizing real pinhole images or low-cost synthetic panoramic images. But, the segmentation model lacks understanding of the panoramic structure when only utilizing real pinhole images, and it lacks perception of real-world scenes when only adopting synthetic panoramic images. Therefore, in this paper, we propose a new task of multi-source domain adaptation for panoramic semantic segmentation, aiming to utilize both real pinhole and synthetic panoramic images in the source domains, enabling the segmentation model to perform well on unlabeled real panoramic images in the target domain. Further, we propose Deformation Transform Aligner for Panoramic Semantic Segmentation (DTA4PASS), which converts all pinhole images in the source domains into panoramic-like images, and then aligns the converted source domains with the target domain. Specifically, DTA4PASS consists of two main components: Unpaired Semantic Morphing (USM) and Distortion Gating Alignment (DGA). Firstly, in USM, the Semantic Dual-view Discriminator (SDD) assists in training the diffeomorphic deformation network, enabling the effective transformation of pinhole images without paired panoramic views. Secondly, DGA assigns pinhole-like and panoramic-like features to each image by gating, and aligns these two features through uncertainty estimation. DTA4PASS outperforms the previous state-of-the-art methods by 1.92% and 2.19% on the outdoor and indoor multi-source domain adaptation scenarios, respectively. The source code will be released.
Read more8/30/2024
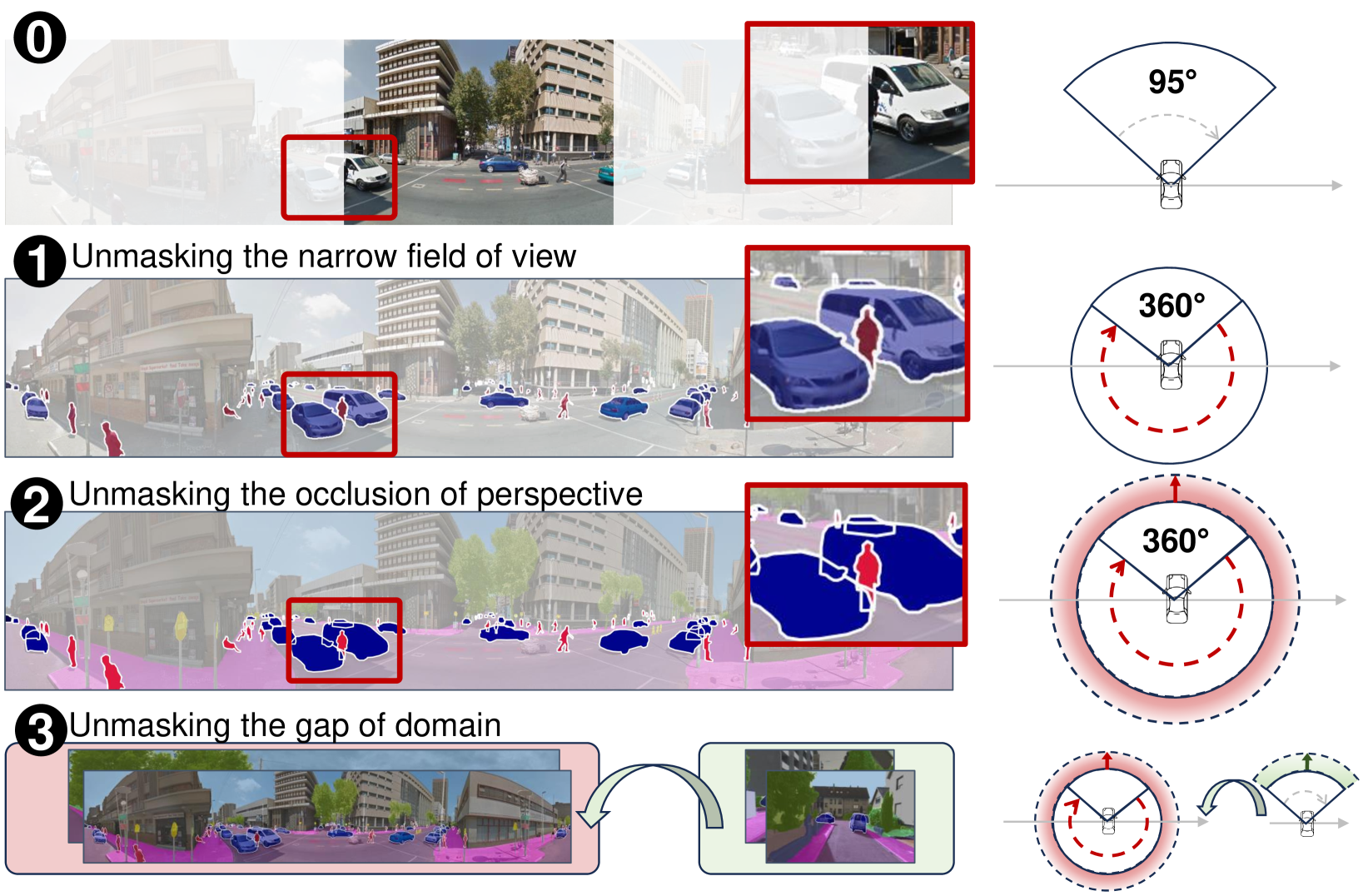
0
Occlusion-Aware Seamless Segmentation
Yihong Cao, Jiaming Zhang, Hao Shi, Kunyu Peng, Yuhongxuan Zhang, Hui Zhang, Rainer Stiefelhagen, Kailun Yang
Panoramic images can broaden the Field of View (FoV), occlusion-aware prediction can deepen the understanding of the scene, and domain adaptation can transfer across viewing domains. In this work, we introduce a novel task, Occlusion-Aware Seamless Segmentation (OASS), which simultaneously tackles all these three challenges. For benchmarking OASS, we establish a new human-annotated dataset for Blending Panoramic Amodal Seamless Segmentation, i.e., BlendPASS. Besides, we propose the first solution UnmaskFormer, aiming at unmasking the narrow FoV, occlusions, and domain gaps all at once. Specifically, UnmaskFormer includes the crucial designs of Unmasking Attention (UA) and Amodal-oriented Mix (AoMix). Our method achieves state-of-the-art performance on the BlendPASS dataset, reaching a remarkable mAPQ of 26.58% and mIoU of 43.66%. On public panoramic semantic segmentation datasets, i.e., SynPASS and DensePASS, our method outperforms previous methods and obtains 45.34% and 48.08% in mIoU, respectively. The fresh BlendPASS dataset and our source code are available at https://github.com/yihong-97/OASS.
Read more7/18/2024

0
PanoVOS: Bridging Non-panoramic and Panoramic Views with Transformer for Video Segmentation
Shilin Yan, Xiaohao Xu, Renrui Zhang, Lingyi Hong, Wenchao Chen, Wenqiang Zhang, Wei Zhang
Panoramic videos contain richer spatial information and have attracted tremendous amounts of attention due to their exceptional experience in some fields such as autonomous driving and virtual reality. However, existing datasets for video segmentation only focus on conventional planar images. To address the challenge, in this paper, we present a panoramic video dataset, PanoVOS. The dataset provides 150 videos with high video resolutions and diverse motions. To quantify the domain gap between 2D planar videos and panoramic videos, we evaluate 15 off-the-shelf video object segmentation (VOS) models on PanoVOS. Through error analysis, we found that all of them fail to tackle pixel-level content discontinues of panoramic videos. Thus, we present a Panoramic Space Consistency Transformer (PSCFormer), which can effectively utilize the semantic boundary information of the previous frame for pixel-level matching with the current frame. Extensive experiments demonstrate that compared with the previous SOTA models, our PSCFormer network exhibits a great advantage in terms of segmentation results under the panoramic setting. Our dataset poses new challenges in panoramic VOS and we hope that our PanoVOS can advance the development of panoramic segmentation/tracking.
Read more7/30/2024