OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework
2404.14619
4
387
💬
Abstract
The reproducibility and transparency of large language models are crucial for advancing open research, ensuring the trustworthiness of results, and enabling investigations into data and model biases, as well as potential risks. To this end, we release OpenELM, a state-of-the-art open language model. OpenELM uses a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model, leading to enhanced accuracy. For example, with a parameter budget of approximately one billion parameters, OpenELM exhibits a 2.36% improvement in accuracy compared to OLMo while requiring $2times$ fewer pre-training tokens. Diverging from prior practices that only provide model weights and inference code, and pre-train on private datasets, our release includes the complete framework for training and evaluation of the language model on publicly available datasets, including training logs, multiple checkpoints, and pre-training configurations. We also release code to convert models to MLX library for inference and fine-tuning on Apple devices. This comprehensive release aims to empower and strengthen the open research community, paving the way for future open research endeavors. Our source code along with pre-trained model weights and training recipes is available at url{https://github.com/apple/corenet}. Additionally, model models can be found on HuggingFace at: url{https://huggingface.co/apple/OpenELM}.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper discusses the importance of reproducibility and transparency in large language models (LLMs) for advancing open research, ensuring trustworthiness, and investigating biases and potential risks.
- The authors release OpenELM, a state-of-the-art open language model that uses a layer-wise scaling strategy to improve accuracy.
- Unlike previous practices of only providing model weights and inference code, and training on private datasets, the OpenELM release includes the complete framework for training and evaluation on publicly available datasets, along with training logs, checkpoints, and configurations.
- The goal is to empower and strengthen the open research community, paving the way for future open research endeavors.
Plain English Explanation
The paper focuses on the importance of being able to reproduce and understand the inner workings of large language models, which are powerful AI systems that can generate human-like text. This is crucial for advancing open research, ensuring the trustworthiness of the results, and investigating potential biases and risks in the models.
To address this, the researchers have released a new language model called OpenELM. Unlike many previous language models, OpenELM is designed to be more efficient and accurate. It uses a clever trick called "layer-wise scaling" to allocate its parameters (the numbers that define how the model works) in a way that boosts its performance.
But the key difference is that the researchers have also released the complete package for training and evaluating OpenELM, including the code, training logs, and even multiple versions of the trained model. This is in contrast with many other language models, where only the final model is shared, and the details of how it was trained are kept private.
By making everything public, the researchers hope to empower the research community to study, improve, and build upon OpenELM. This "open research" approach is intended to lead to faster progress and more trustworthy results in the field of natural language AI.
Technical Explanation
The paper presents the release of OpenELM, a state-of-the-art open language model that aims to address the need for reproducibility and transparency in large language models. The model uses a layer-wise scaling strategy to efficiently allocate parameters within each transformer layer, leading to enhanced accuracy.
Specifically, the authors show that with a parameter budget of approximately one billion parameters, OpenELM exhibits a 2.36% improvement in accuracy compared to a previous model called OLMo, while requiring half the number of pre-training tokens. This improvement in efficiency and performance is achieved through the layer-wise scaling approach.
Importantly, the authors diverge from the common practice of only providing model weights and inference code, as well as training on private datasets. Instead, the OpenELM release includes the complete framework for training and evaluation on publicly available datasets, including training logs, multiple checkpoints, and pre-training configurations. This comprehensive release is intended to empower the open research community and enable future open research endeavors.
Additionally, the authors provide code to convert the models to the MLX library for inference and fine-tuning on Apple devices, further expanding the accessibility and usability of the OpenELM model.
Critical Analysis
The authors are to be commended for their commitment to reproducibility and transparency in the release of OpenELM. By providing the complete training and evaluation framework, they have made it possible for the research community to thoroughly investigate the model, its performance, and potential biases or limitations.
However, the paper does not delve into the specific details of the layer-wise scaling strategy, nor does it provide a comprehensive analysis of the model's performance across a wide range of benchmarks and tasks. It would be helpful to see a more detailed exploration of the model's strengths, weaknesses, and potential areas for improvement.
Furthermore, while the authors mention the importance of investigating potential risks associated with large language models, the paper does not provide any insights into the specific risks or mitigation strategies employed in the development of OpenELM. A more thorough discussion of these considerations would be valuable for the broader research community.
Overall, the release of OpenELM is a commendable step towards greater transparency and reproducibility in the field of large language models. The authors have laid the groundwork for future open research endeavors, as evidenced by the availability of the model on HuggingFace and the provision of conversion tools for MLX and Apple devices. However, there is still room for further exploration and analysis to fully understand the model's capabilities and limitations.
Conclusion
The paper highlights the importance of reproducibility and transparency in large language models, which are increasingly important for advancing open research, ensuring trustworthiness, and investigating potential biases and risks. The release of OpenELM, a state-of-the-art open language model, is a significant step towards empowering the research community and enabling future open research endeavors.
By providing the complete framework for training and evaluating the model, including training logs, checkpoints, and configurations, the authors have set a new standard for transparency and accessibility in the field of large language models. This comprehensive release, along with the availability of the model on HuggingFace and the inclusion of conversion tools for MLX and Apple devices, is a valuable contribution that can drive further advancements in natural language AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎯
ChuXin: 1.6B Technical Report
Xiaomin Zhuang, Yufan Jiang, Qiaozhi He, Zhihua Wu
0
0
In this report, we present ChuXin, an entirely open-source language model with a size of 1.6 billion parameters. Unlike the majority of works that only open-sourced the model weights and architecture, we have made everything needed to train a model available, including the training data, the training process, and the evaluation code. Our goal is to empower and strengthen the open research community, fostering transparency and enabling a new wave of innovation in the field of language modeling. Furthermore, we extend the context length to 1M tokens through lightweight continual pretraining and demonstrate strong needle-in-a-haystack retrieval performance. The weights for both models are available at Hugging Face to download and use.
5/9/2024
🐍
Tele-FLM Technical Report
Xiang Li, Yiqun Yao, Xin Jiang, Xuezhi Fang, Chao Wang, Xinzhang Liu, Zihan Wang, Yu Zhao, Xin Wang, Yuyao Huang, Shuangyong Song, Yongxiang Li, Zheng Zhang, Bo Zhao, Aixin Sun, Yequan Wang, Zhongjiang He, Zhongyuan Wang, Xuelong Li, Tiejun Huang
0
0
Large language models (LLMs) have showcased profound capabilities in language understanding and generation, facilitating a wide array of applications. However, there is a notable paucity of detailed, open-sourced methodologies on efficiently scaling LLMs beyond 50 billion parameters with minimum trial-and-error cost and computational resources. In this report, we introduce Tele-FLM (aka FLM-2), a 52B open-sourced multilingual large language model that features a stable, efficient pre-training paradigm and enhanced factual judgment capabilities. Tele-FLM demonstrates superior multilingual language modeling abilities, measured by BPB on textual corpus. Besides, in both English and Chinese foundation model evaluation, it is comparable to strong open-sourced models that involve larger pre-training FLOPs, such as Llama2-70B and DeepSeek-67B. In addition to the model weights, we share the core designs, engineering practices, and training details, which we expect to benefit both the academic and industrial communities.
4/26/2024
Aurora-M: The First Open Source Multilingual Language Model Red-teamed according to the U.S. Executive Order
Taishi Nakamura, Mayank Mishra, Simone Tedeschi, Yekun Chai, Jason T Stillerman, Felix Friedrich, Prateek Yadav, Tanmay Laud, Vu Minh Chien, Terry Yue Zhuo, Diganta Misra, Ben Bogin, Xuan-Son Vu, Marzena Karpinska, Arnav Varma Dantuluri, Wojciech Kusa, Tommaso Furlanello, Rio Yokota, Niklas Muennighoff, Suhas Pai, Tosin Adewumi, Veronika Laippala, Xiaozhe Yao, Adalberto Junior, Alpay Ariyak, Aleksandr Drozd, Jordan Clive, Kshitij Gupta, Liangyu Chen, Qi Sun, Ken Tsui, Noah Persaud, Nour Fahmy, Tianlong Chen, Mohit Bansal, Nicolo Monti, Tai Dang, Ziyang Luo, Tien-Tung Bui, Roberto Navigli, Virendra Mehta, Matthew Blumberg, Victor May, Huu Nguyen, Sampo Pyysalo
0
0
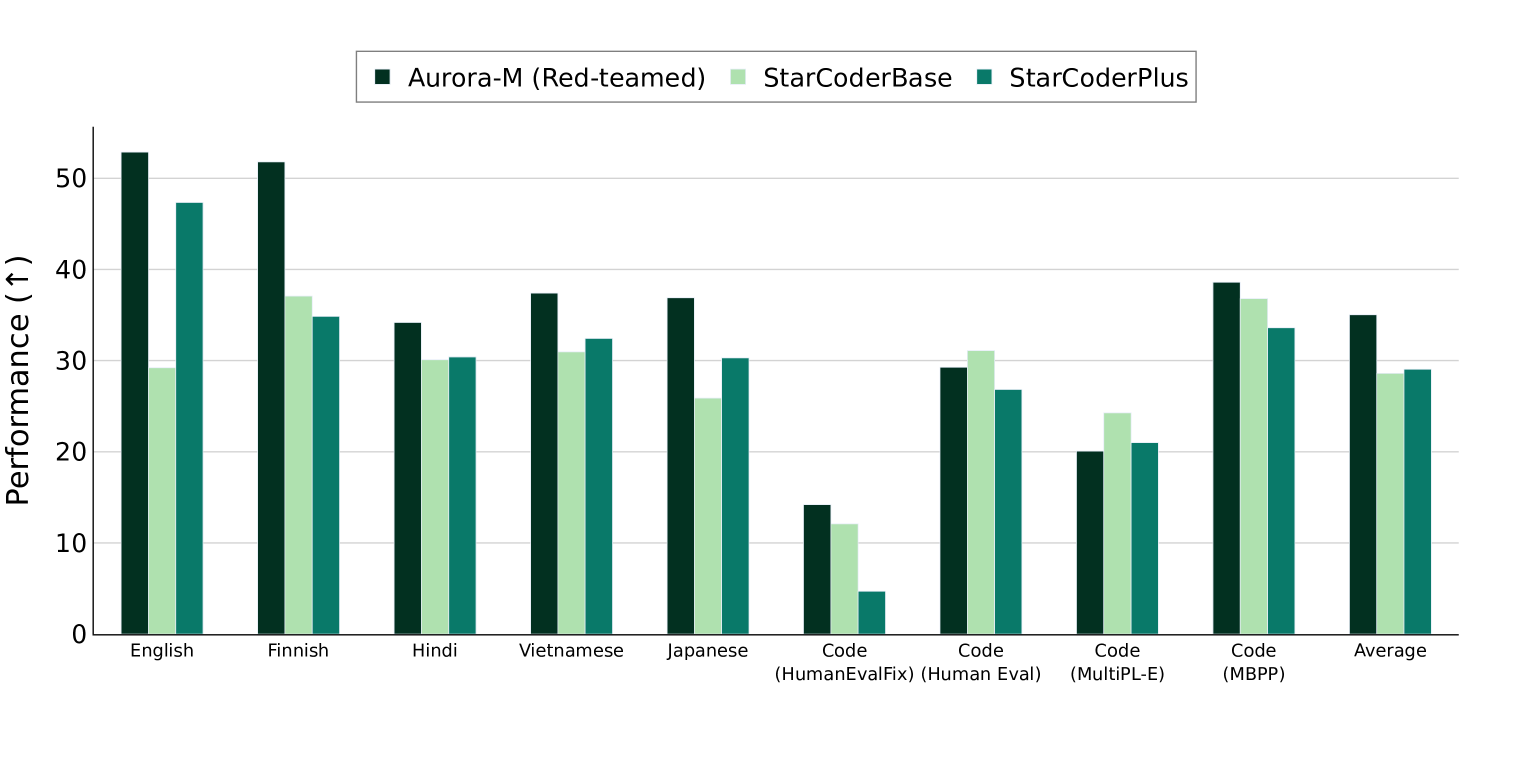
Pretrained language models underpin several AI applications, but their high computational cost for training limits accessibility. Initiatives such as BLOOM and StarCoder aim to democratize access to pretrained models for collaborative community development. However, such existing models face challenges: limited multilingual capabilities, continual pretraining causing catastrophic forgetting, whereas pretraining from scratch is computationally expensive, and compliance with AI safety and development laws. This paper presents Aurora-M, a 15B parameter multilingual open-source model trained on English, Finnish, Hindi, Japanese, Vietnamese, and code. Continually pretrained from StarCoderPlus on 435 billion additional tokens, Aurora-M surpasses 2 trillion tokens in total training token count. It is the first open-source multilingual model fine-tuned on human-reviewed safety instructions, thus aligning its development not only with conventional red-teaming considerations, but also with the specific concerns articulated in the Biden-Harris Executive Order on the Safe, Secure, and Trustworthy Development and Use of Artificial Intelligence. Aurora-M is rigorously evaluated across various tasks and languages, demonstrating robustness against catastrophic forgetting and outperforming alternatives in multilingual settings, particularly in safety evaluations. To promote responsible open-source LLM development, Aurora-M and its variants are released at https://huggingface.co/collections/aurora-m/aurora-m-models-65fdfdff62471e09812f5407 .
4/24/2024
FreeEval: A Modular Framework for Trustworthy and Efficient Evaluation of Large Language Models
Zhuohao Yu, Chang Gao, Wenjin Yao, Yidong Wang, Zhengran Zeng, Wei Ye, Jindong Wang, Yue Zhang, Shikun Zhang
0
0
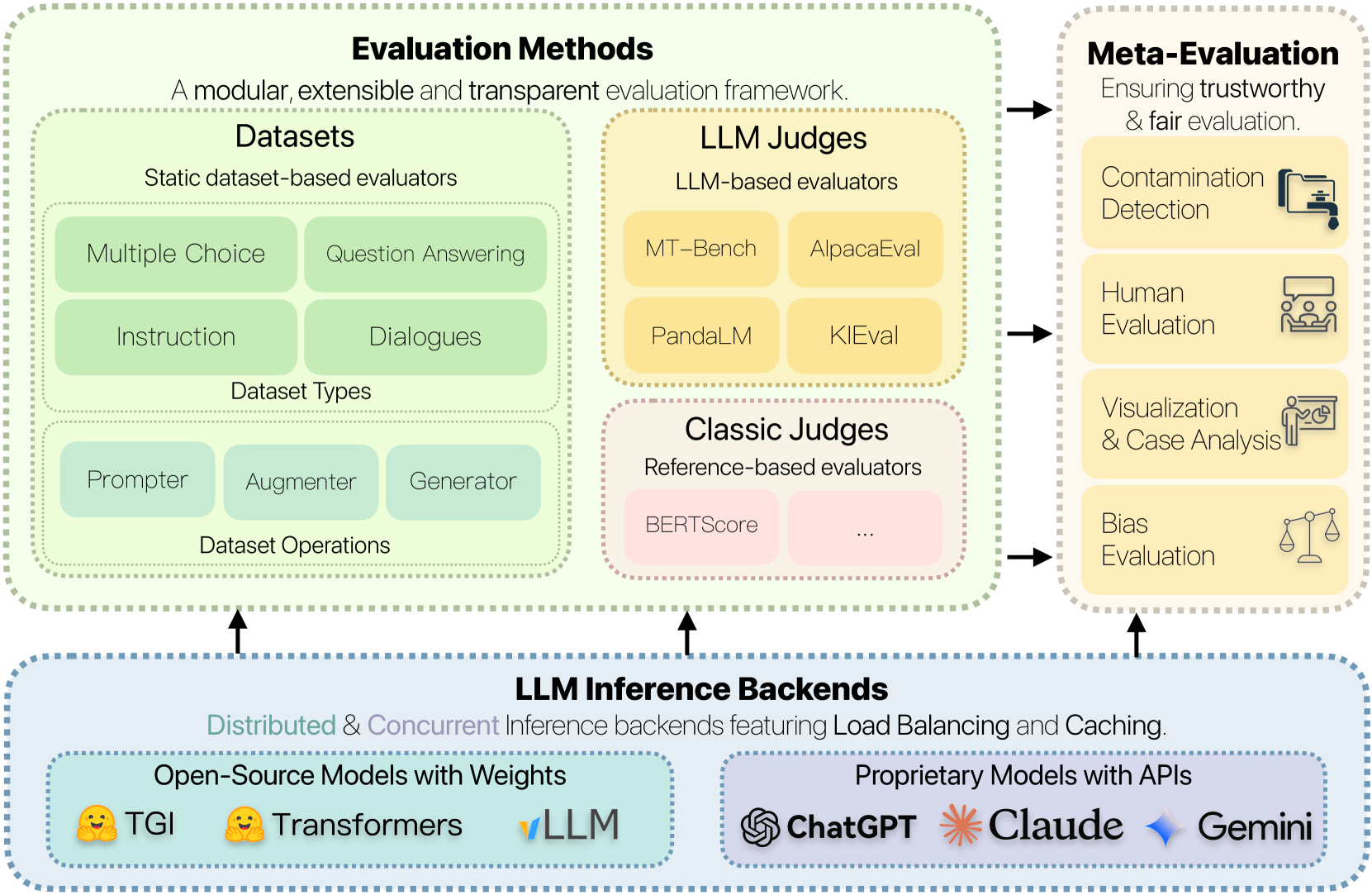
The rapid development of large language model (LLM) evaluation methodologies and datasets has led to a profound challenge: integrating state-of-the-art evaluation techniques cost-effectively while ensuring reliability, reproducibility, and efficiency. Currently, there is a notable absence of a unified and adaptable framework that seamlessly integrates various evaluation approaches. Moreover, the reliability of evaluation findings is often questionable due to potential data contamination, with the evaluation efficiency commonly overlooked when facing the substantial costs associated with LLM inference. In response to these challenges, we introduce FreeEval, a modular and scalable framework crafted to enable trustworthy and efficient automatic evaluations of LLMs. Firstly, FreeEval's unified abstractions simplify the integration and improve the transparency of diverse evaluation methodologies, encompassing dynamic evaluation that demand sophisticated LLM interactions. Secondly, the framework integrates meta-evaluation techniques like human evaluation and data contamination detection, which, along with dynamic evaluation modules in the platform, enhance the fairness of the evaluation outcomes. Lastly, FreeEval is designed with a high-performance infrastructure, including distributed computation and caching strategies, enabling extensive evaluations across multi-node, multi-GPU clusters for open-source and proprietary LLMs.
4/10/2024