Optimistic Query Routing in Clustering-based Approximate Maximum Inner Product Search

0
Sign in to get full access
Overview
- This paper proposes an "Optimistic Query Routing" technique for clustering-based approximate maximum inner product search (AMIPS).
- AMIPS is a method for quickly finding the most similar items in a large dataset to a given query, which is useful for applications like recommendation systems and image retrieval.
- The key idea is to use an "optimistic" approach to decide which clusters to search, aiming to minimize the number of clusters examined while still finding high-quality results.
Plain English Explanation
The paper describes a technique called "Optimistic Query Routing" that can make clustering-based approximate maximum inner product search more efficient. Approximate maximum inner product search (AMIPS) is a way to quickly find the most similar items in a large dataset to a given query. This is really useful for things like recommendation systems and image retrieval.
The key idea behind the "Optimistic Query Routing" technique is to use an "optimistic" approach to decide which clusters of data to search. The goal is to minimize the number of clusters that need to be examined, while still being able to find the high-quality results that the user is looking for. This can make the overall search process much faster and more efficient, which is important when dealing with very large datasets.
The paper builds on previous work on clustering-based AMIPS, and the authors test their new technique on some real-world datasets to show that it can provide significant performance improvements.
Technical Explanation
The proposed "Optimistic Query Routing" technique builds on clustering-based approaches to approximate maximum inner product search (AMIPS). In AMIPS, the dataset is first partitioned into clusters, and then at query time, the most relevant clusters are identified and searched to find the items most similar to the query.
The key innovation in this paper is the "optimistic" approach to deciding which clusters to search. Rather than simply examining clusters in order of their maximum possible similarity to the query, the authors propose a more sophisticated scoring system that takes into account both the maximum and minimum possible similarities. This "optimistic" scoring allows the system to skip over clusters that are unlikely to contain high-quality results, while still ensuring that the top results are found.
The authors evaluate their approach on several real-world datasets, including text and image retrieval tasks. They show that their "Optimistic Query Routing" technique can provide significant speedups over baseline clustering-based AMIPS methods, while maintaining high search quality.
Critical Analysis
The paper provides a thoughtful and well-executed approach to improving the efficiency of clustering-based AMIPS. The key innovation of "Optimistic Query Routing" seems well-justified and the experimental results demonstrate its effectiveness.
One potential limitation is that the technique may not generalize as well to datasets with very complex or non-convex cluster structures. The authors note that their approach relies on the assumption that the cluster centroids provide a good approximation of the cluster contents, which may not hold in all cases.
Additionally, the paper does not provide a detailed analysis of the computational complexity of the proposed approach, or how it scales with the size of the dataset and the number of clusters. This information would be helpful for understanding the practical applicability of the technique.
Overall, the paper presents a valuable contribution to the field of approximate nearest neighbor search, and the "Optimistic Query Routing" technique seems like a promising direction for further research and development.
Conclusion
This paper introduces an "Optimistic Query Routing" technique for improving the efficiency of clustering-based approximate maximum inner product search (AMIPS). AMIPS is a powerful tool for quickly finding the most similar items in a large dataset to a given query, with applications in recommendation systems, image retrieval, and other areas.
The key innovation in this paper is the use of an "optimistic" scoring system to decide which clusters to search, aiming to minimize the number of clusters examined while still finding high-quality results. The authors demonstrate the effectiveness of their approach through experiments on real-world datasets, showing significant performance improvements over baseline clustering-based AMIPS methods.
While the technique may have some limitations in certain cases, it represents an important step forward in making AMIPS more practical and scalable for large-scale applications. The insights and techniques developed in this paper could have a meaningful impact on the development of next-generation search and recommendation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimistic Query Routing in Clustering-based Approximate Maximum Inner Product Search
Sebastian Bruch, Aditya Krishnan, Franco Maria Nardini
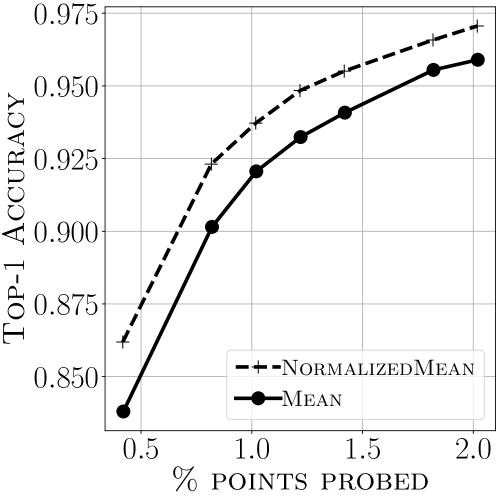
Clustering-based nearest neighbor search is a simple yet effective method in which data points are partitioned into geometric shards to form an index, and only a few shards are searched during query processing to find an approximate set of top-$k$ vectors. Even though the search efficacy is heavily influenced by the algorithm that identifies the set of shards to probe, it has received little attention in the literature. This work attempts to bridge that gap by studying the problem of routing in clustering-based maximum inner product search (MIPS). We begin by unpacking existing routing protocols and notice the surprising contribution of optimism. We then take a page from the sequential decision making literature and formalize that insight following the principle of ``optimism in the face of uncertainty.'' In particular, we present a new framework that incorporates the moments of the distribution of inner products within each shard to optimistically estimate the maximum inner product. We then present a simple instance of our algorithm that uses only the first two moments to reach the same accuracy as state-of-the-art routers such as scann by probing up to $50%$ fewer points on a suite of benchmark MIPS datasets. Our algorithm is also space-efficient: we design a sketch of the second moment whose size is independent of the number of points and in practice requires storing only $O(1)$ additional vectors per shard.
Read more5/21/2024
0
A Learning-to-Rank Formulation of Clustering-Based Approximate Nearest Neighbor Search
Thomas Vecchiato, Claudio Lucchese, Franco Maria Nardini, Sebastian Bruch
A critical piece of the modern information retrieval puzzle is approximate nearest neighbor search. Its objective is to return a set of $k$ data points that are closest to a query point, with its accuracy measured by the proportion of exact nearest neighbors captured in the returned set. One popular approach to this question is clustering: The indexing algorithm partitions data points into non-overlapping subsets and represents each partition by a point such as its centroid. The query processing algorithm first identifies the nearest clusters -- a process known as routing -- then performs a nearest neighbor search over those clusters only. In this work, we make a simple observation: The routing function solves a ranking problem. Its quality can therefore be assessed with a ranking metric, making the function amenable to learning-to-rank. Interestingly, ground-truth is often freely available: Given a query distribution in a top-$k$ configuration, the ground-truth is the set of clusters that contain the exact top-$k$ vectors. We develop this insight and apply it to Maximum Inner Product Search (MIPS). As we demonstrate empirically on various datasets, learning a simple linear function consistently improves the accuracy of clustering-based MIPS.
Read more4/19/2024

0
Efficient Retrieval with Learned Similarities
Bailu Ding, Jiaqi Zhai
Retrieval plays a fundamental role in recommendation systems, search, and natural language processing by efficiently finding relevant items from a large corpus given a query. Dot products have been widely used as the similarity function in such retrieval tasks, thanks to Maximum Inner Product Search (MIPS) that enabled efficient retrieval based on dot products. However, state-of-the-art retrieval algorithms have migrated to learned similarities. Such algorithms vary in form; the queries can be represented with multiple embeddings, complex neural networks can be deployed, the item ids can be decoded directly from queries using beam search, and multiple approaches can be combined in hybrid solutions. Unfortunately, we lack efficient solutions for retrieval in these state-of-the-art setups. Our work investigates techniques for approximate nearest neighbor search with learned similarity functions. We first prove that Mixture-of-Logits (MoL) is a universal approximator, and can express all learned similarity functions. We next propose techniques to retrieve the approximate top K results using MoL with a tight bound. We finally compare our techniques with existing approaches, showing that MoL sets new state-of-the-art results on recommendation retrieval tasks, and our approximate top-k retrieval with learned similarities outperforms baselines by up to two orders of magnitude in latency, while achieving > .99 recall rate of exact algorithms.
Read more8/15/2024
🔄
0
Probabilistic Routing for Graph-Based Approximate Nearest Neighbor Search
Kejing Lu, Chuan Xiao, Yoshiharu Ishikawa
Approximate nearest neighbor search (ANNS) in high-dimensional spaces is a pivotal challenge in the field of machine learning. In recent years, graph-based methods have emerged as the superior approach to ANNS, establishing a new state of the art. Although various optimizations for graph-based ANNS have been introduced, they predominantly rely on heuristic methods that lack formal theoretical backing. This paper aims to enhance routing within graph-based ANNS by introducing a method that offers a probabilistic guarantee when exploring a node's neighbors in the graph. We formulate the problem as probabilistic routing and develop two baseline strategies by incorporating locality-sensitive techniques. Subsequently, we introduce PEOs, a novel approach that efficiently identifies which neighbors in the graph should be considered for exact distance calculation, thus significantly improving efficiency in practice. Our experiments demonstrate that equipping PEOs can increase throughput on commonly utilized graph indexes (HNSW and NSSG) by a factor of 1.6 to 2.5, and its efficiency consistently outperforms the leading-edge routing technique by 1.1 to 1.4 times.
Read more7/11/2024