Harnessing the Power of Multiple Minds: Lessons Learned from LLM Routing

0

Sign in to get full access
Overview
- This paper explores the lessons learned from using large language models (LLMs) to route queries to the most appropriate model or assistant.
- The authors present a system that dynamically routes user queries to different LLMs based on the query's requirements, aiming to provide efficient and high-quality responses.
- The paper discusses the challenges and insights gained from deploying this routing system, which can inform the development of future LLM-based assistants.
Plain English Explanation
The paper discusses a system that tries to find the best way to answer a user's question or request by automatically sending it to the most suitable large language model (LLM) or assistant. LLMs are powerful AI models that can understand and generate human-like text, but they each have their own strengths and weaknesses. The authors' system evaluates the user's query and routes it to the LLM or assistant that is most likely to provide an efficient and high-quality response.
For example, if a user asks a factual question, the system might send it to an LLM that is particularly good at retrieving and summarizing information from the internet. If the user asks for creative writing assistance, the system might route the request to an LLM that excels at generating original, engaging text. By dynamically matching the query to the appropriate LLM, the system aims to provide the user with the best possible outcome.
The paper shares the lessons the authors learned from developing and deploying this LLM routing system, which can help guide the creation of future AI-powered assistants that leverage multiple LLMs or other AI models.
Technical Explanation
The paper presents a system that routes user queries to the most appropriate large language model (LLM) or assistant in order to provide efficient and high-quality responses. The authors developed a query routing mechanism that evaluates the characteristics of each incoming query and selects the LLM or assistant best suited to handle it.
The routing system considers factors such as the query's complexity, the required response quality, and the capabilities of the available LLMs. It then directs the query to the model or assistant most likely to provide an optimal result, drawing on insights from related research on reasoning-efficient knowledge paths and LLMs as assistants.
The paper discusses the challenges the authors faced in developing and deploying this routing system, such as accurately evaluating query requirements, maintaining model performance, and ensuring seamless user experiences. The authors also share insights on topics like cross-data knowledge graph construction and structured graph reasoning, which informed the design of their routing mechanisms.
Critical Analysis
The paper provides valuable insights into the practical challenges of deploying LLM-based systems in real-world scenarios. The authors acknowledge that accurately assessing the requirements of user queries and matching them to the most suitable LLMs is a complex task, with room for improvement.
One potential limitation is the reliance on pre-defined capabilities of the available LLMs. As language models continue to rapidly evolve, the routing system may need frequent updates to account for changes in model performance and specialization. Additionally, the paper does not fully address the potential risks of routing sensitive or personal queries to third-party LLMs, which could raise privacy and security concerns.
Further research could explore more dynamic and adaptive routing approaches, perhaps leveraging meta-learning or other techniques to continuously optimize the matching of queries to LLMs. Investigating the ethical implications of LLM-based assistants, particularly around issues of bias, transparency, and accountability, would also be a valuable direction for future work.
Conclusion
This paper offers valuable lessons and insights for the development of LLM-based assistants that can effectively leverage the capabilities of multiple language models. By dynamically routing queries to the most appropriate LLM, the authors demonstrate a promising approach to providing efficient and high-quality responses to user requests.
The challenges and insights shared in this work can inform the design of future AI-powered systems that aim to harness the collective intelligence of large language models. As the field of LLM-based assistants continues to evolve, the lessons learned from this research can help guide the creation of more sophisticated and user-centric applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Harnessing the Power of Multiple Minds: Lessons Learned from LLM Routing
KV Aditya Srivatsa, Kaushal Kumar Maurya, Ekaterina Kochmar
With the rapid development of LLMs, it is natural to ask how to harness their capabilities efficiently. In this paper, we explore whether it is feasible to direct each input query to a single most suitable LLM. To this end, we propose LLM routing for challenging reasoning tasks. Our extensive experiments suggest that such routing shows promise but is not feasible in all scenarios, so more robust approaches should be investigated to fill this gap.
Read more5/2/2024

0
RouteLLM: Learning to Route LLMs with Preference Data
Isaac Ong, Amjad Almahairi, Vincent Wu, Wei-Lin Chiang, Tianhao Wu, Joseph E. Gonzalez, M Waleed Kadous, Ion Stoica
Large language models (LLMs) exhibit impressive capabilities across a wide range of tasks, yet the choice of which model to use often involves a trade-off between performance and cost. More powerful models, though effective, come with higher expenses, while less capable models are more cost-effective. To address this dilemma, we propose several efficient router models that dynamically select between a stronger and a weaker LLM during inference, aiming to optimize the balance between cost and response quality. We develop a training framework for these routers leveraging human preference data and data augmentation techniques to enhance performance. Our evaluation on widely-recognized benchmarks shows that our approach significantly reduces costs-by over 2 times in certain cases-without compromising the quality of responses. Interestingly, our router models also demonstrate significant transfer learning capabilities, maintaining their performance even when the strong and weak models are changed at test time. This highlights the potential of these routers to provide a cost-effective yet high-performance solution for deploying LLMs.
Read more7/23/2024
🛸
0
Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing
Dujian Ding, Ankur Mallick, Chi Wang, Robert Sim, Subhabrata Mukherjee, Victor Ruhle, Laks V. S. Lakshmanan, Ahmed Hassan Awadallah
Large language models (LLMs) excel in most NLP tasks but also require expensive cloud servers for deployment due to their size, while smaller models that can be deployed on lower cost (e.g., edge) devices, tend to lag behind in terms of response quality. Therefore in this work we propose a hybrid inference approach which combines their respective strengths to save cost and maintain quality. Our approach uses a router that assigns queries to the small or large model based on the predicted query difficulty and the desired quality level. The desired quality level can be tuned dynamically at test time to seamlessly trade quality for cost as per the scenario requirements. In experiments our approach allows us to make up to 40% fewer calls to the large model, with no drop in response quality.
Read more4/24/2024
0
PolyRouter: A Multi-LLM Querying System
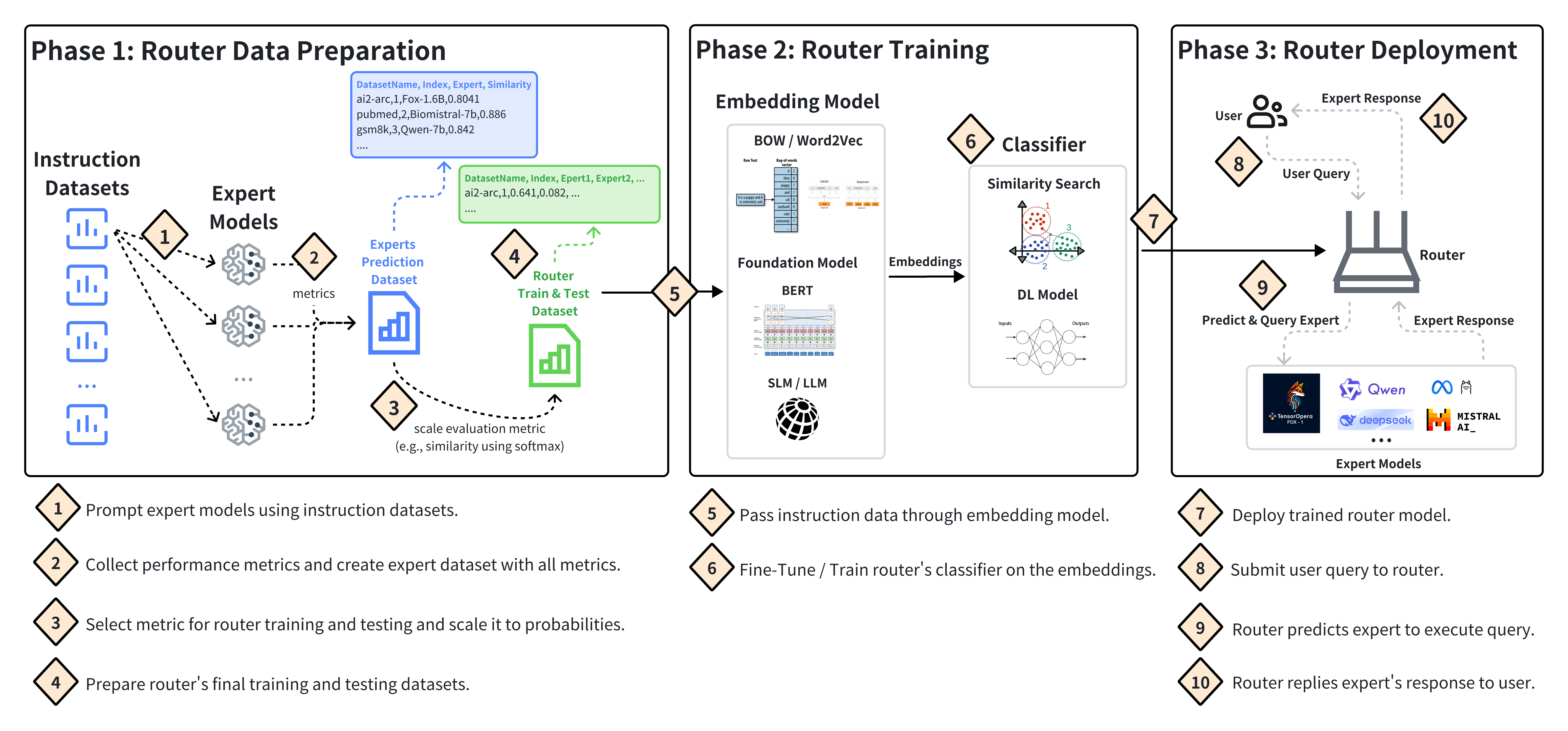
Dimitris Stripelis, Zijian Hu, Jipeng Zhang, Zhaozhuo Xu, Alay Dilipbhai Shah, Han Jin, Yuhang Yao, Salman Avestimehr, Chaoyang He
With the rapid growth of Large Language Models (LLMs) across various domains, numerous new LLMs have emerged, each possessing domain-specific expertise. This proliferation has highlighted the need for quick, high-quality, and cost-effective LLM query response methods. Yet, no single LLM exists to efficiently balance this trilemma. Some models are powerful but extremely costly, while others are fast and inexpensive but qualitatively inferior. To address this challenge, we present PolyRouter, a non-monolithic LLM querying system that seamlessly integrates various LLM experts into a single query interface and dynamically routes incoming queries to the most high-performant expert based on query's requirements. Through extensive experiments, we demonstrate that when compared to standalone expert models, PolyRouter improves query efficiency by up to 40%, and leads to significant cost reductions of up to 30%, while maintaining or enhancing model performance by up to 10%.
Read more8/28/2024