Optimizing Performance on Trinity Utilizing Machine Learning, Proxy Applications and Scheduling Priorities

0

Sign in to get full access
Overview
- The paper explores optimizing performance on the Trinity supercomputer using machine learning, proxy applications, and scheduling priorities.
- It investigates the use of machine learning techniques to model and predict the performance of various workloads on the Trinity system.
- The paper also introduces the concept of proxy applications, which are smaller-scale versions of complex applications, to aid in performance optimization.
- Additionally, the paper explores the impact of scheduling priorities on overall system performance.
Plain English Explanation
The researchers in this paper looked at ways to make the Trinity supercomputer run more efficiently. They used machine learning to create models that could predict how different workloads, or tasks, would perform on the Trinity system. This allowed them to identify ways to optimize the system's performance.
The researchers also used proxy applications - simplified versions of complex software programs - to test different optimization strategies without having to run the full-scale applications. This made the testing process faster and more efficient.
Finally, the paper examines how the priorities assigned to different tasks, or scheduling priorities, can impact the overall performance of the Trinity system. By adjusting these priorities, the researchers were able to further optimize the system's performance.
Technical Explanation
The paper presents a multi-faceted approach to optimizing performance on the Trinity supercomputer. The researchers utilized machine learning techniques to build predictive models of application performance on the Trinity system. These models were trained on historical performance data and were able to forecast the behavior of various workloads.
To assist in their optimization efforts, the researchers also developed a set of proxy applications - smaller, simplified versions of complex applications. These proxy apps allowed the researchers to quickly test different optimization strategies without the time and resource constraints of running the full-scale applications.
Additionally, the paper explores the impact of scheduling priorities on overall system performance. By adjusting the priorities assigned to different tasks, the researchers were able to further optimize the Trinity system's efficiency.
Critical Analysis
The paper presents a comprehensive approach to optimizing performance on the Trinity supercomputer, leveraging a combination of machine learning, proxy applications, and scheduling priorities. The use of predictive models based on historical performance data is a promising approach, as it allows for more informed decision-making regarding resource allocation and workload scheduling.
However, the paper does not provide a detailed discussion of the limitations of the machine learning models. It would be valuable to understand the accuracy and reliability of the predictions, as well as the potential biases or errors that could arise from the training data or model architecture.
Additionally, while the proxy applications seem to be a useful tool for rapid testing, the paper does not address the potential differences between the proxy apps and the full-scale applications. It would be important to understand the extent to which the proxy apps accurately represent the behavior and performance characteristics of their larger counterparts.
Finally, the paper could benefit from a more in-depth analysis of the trade-offs and implications of the scheduling priority adjustments. It would be helpful to understand the specific criteria used to set the priorities, as well as the potential unintended consequences or conflicts that could arise from these decisions.
Conclusion
This paper presents a comprehensive approach to optimizing the performance of the Trinity supercomputer, leveraging a combination of machine learning, proxy applications, and scheduling priorities. The use of predictive models and simplified proxy apps allows for more efficient testing and optimization of the system, while the exploration of scheduling priorities provides insights into how workload management can impact overall performance.
While the paper demonstrates the potential benefits of this multi-faceted approach, it would be valuable to see a more thorough discussion of the limitations and potential drawbacks of the methods employed. Nonetheless, the research presented in this paper contributes to the ongoing efforts to improve the efficiency and performance of high-performance computing systems, which have significant implications for scientific research, technological advancement, and societal progress.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Optimizing Performance on Trinity Utilizing Machine Learning, Proxy Applications and Scheduling Priorities
Phil Romero
The sheer number of nodes continues to increase in todays supercomputers, the first half of Trinity alone contains more than 9400 compute nodes. Since the speed of todays clusters are limited by the slowest nodes, it more important than ever to identify slow nodes, improve their performance if it can be done, and assure minimal usage of slower nodes during performance critical runs. This is an ongoing maintenance task that occurs on a regular basis and, therefore, it is important to minimize the impact upon its users by assessing and addressing slow performing nodes and mitigating their consequences while minimizing down time. These issues can be solved, in large part, through a systematic application of fast running hardware assessment tests, the application of Machine Learning, and making use of performance data to increase efficiency of large clusters. Proxy applications utilizing both MPI and OpenMP were developed to produce data as a substitute for long runtime applications to evaluate node performance. Machine learning is applied to identify underperforming nodes, and policies are being discussed to both minimize the impact of underperforming nodes and increase the efficiency of the system. In this paper, I will describe the process used to produce quickly performing proxy tests, consider various methods to isolate the outliers, and produce ordered lists for use in scheduling to accomplish this task.
Read more4/17/2024
0
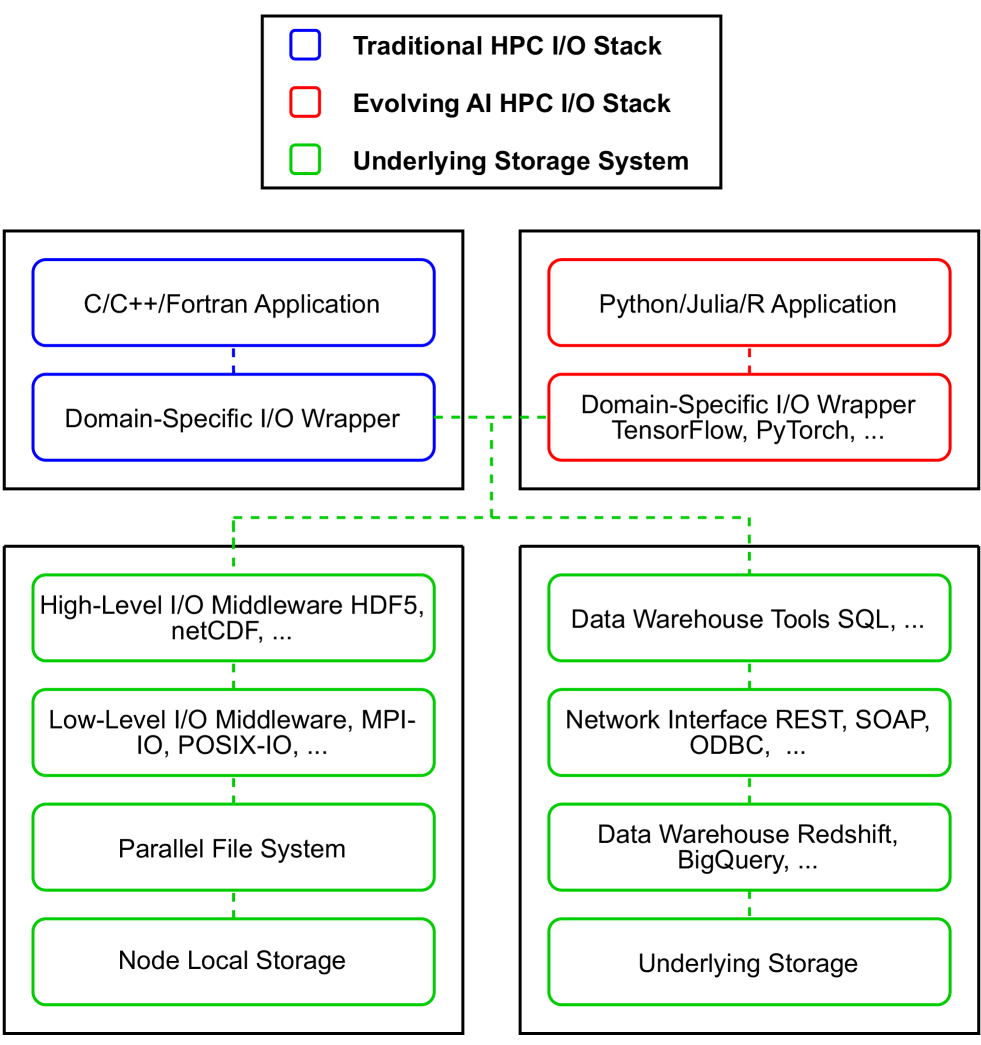
I/O in Machine Learning Applications on HPC Systems: A 360-degree Survey
Noah Lewis, Jean Luca Bez, Suren Byna
High-Performance Computing (HPC) systems excel in managing distributed workloads, and the growing interest in Artificial Intelligence (AI) has resulted in a surge in demand for faster methods of Machine Learning (ML) model training and inference. In the past, research on HPC I/O focused on optimizing the underlying storage system for modeling and simulation applications and checkpointing the results, causing writes to be the dominant I/O operation. These applications typically access large portions of the data written by simulations or experiments. ML workloads, in contrast, perform small I/O reads spread across a large number of random files. This shift of I/O access patterns poses several challenges to HPC storage systems. In this paper, we survey I/O in ML applications on HPC systems, and target literature within a 6-year time window from 2019 to 2024. We provide an overview of the common phases of ML, review available profilers and benchmarks, examine the I/O patterns encountered during ML training, explore I/O optimizations utilized in modern ML frameworks and proposed in recent literature, and lastly, present gaps requiring further R&D. We seek to summarize the common practices used in accessing data by ML applications and expose research gaps that could spawn further R&D.
Read more4/17/2024
0
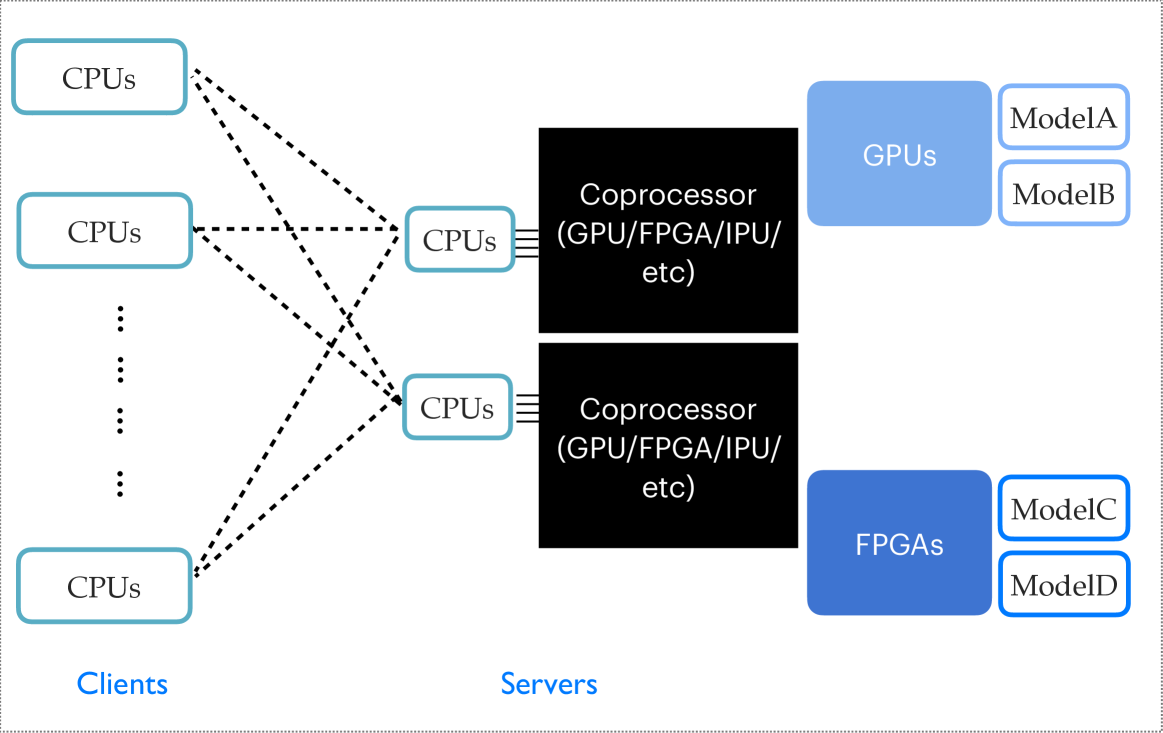
Portable acceleration of CMS computing workflows with coprocessors as a service
CMS Collaboration
Computing demands for large scientific experiments, such as the CMS experiment at the CERN LHC, will increase dramatically in the next decades. To complement the future performance increases of software running on central processing units (CPUs), explorations of coprocessor usage in data processing hold great potential and interest. Coprocessors are a class of computer processors that supplement CPUs, often improving the execution of certain functions due to architectural design choices. We explore the approach of Services for Optimized Network Inference on Coprocessors (SONIC) and study the deployment of this as-a-service approach in large-scale data processing. In the studies, we take a data processing workflow of the CMS experiment and run the main workflow on CPUs, while offloading several machine learning (ML) inference tasks onto either remote or local coprocessors, specifically graphics processing units (GPUs). With experiments performed at Google Cloud, the Purdue Tier-2 computing center, and combinations of the two, we demonstrate the acceleration of these ML algorithms individually on coprocessors and the corresponding throughput improvement for the entire workflow. This approach can be easily generalized to different types of coprocessors and deployed on local CPUs without decreasing the throughput performance. We emphasize that the SONIC approach enables high coprocessor usage and enables the portability to run workflows on different types of coprocessors.
Read more9/9/2024
📈
0
MAD Max Beyond Single-Node: Enabling Large Machine Learning Model Acceleration on Distributed Systems
Samuel Hsia, Alicia Golden, Bilge Acun, Newsha Ardalani, Zachary DeVito, Gu-Yeon Wei, David Brooks, Carole-Jean Wu
Training and deploying large-scale machine learning models is time-consuming, requires significant distributed computing infrastructures, and incurs high operational costs. Our analysis, grounded in real-world large model training on datacenter-scale infrastructures, reveals that 14~32% of all GPU hours are spent on communication with no overlapping computation. To minimize this outstanding communication latency and other inherent at-scale inefficiencies, we introduce an agile performance modeling framework, MAD-Max. This framework is designed to optimize parallelization strategies and facilitate hardware-software co-design opportunities. Through the application of MAD-Max to a suite of real-world large-scale ML models on state-of-the-art GPU clusters, we showcase potential throughput enhancements of up to 2.24x for pre-training and up to 5.2x for inference scenarios, respectively.
Read more6/12/2024