Union: An Automatic Workload Manager for Accelerating Network Simulation

0
Sign in to get full access
Overview
- Introduces Union, an automatic workload manager for accelerating network simulation
- Focuses on addressing the challenge of interference between heterogeneous workloads in high-performance computing environments
- Proposes a novel approach to intelligently schedule and route simulation tasks to improve overall performance
Plain English Explanation
Union is a tool designed to help researchers and engineers who work with complex network simulations. These simulations often involve running many different types of tasks at the same time, which can cause interference and slow down the overall process.
Union's key innovation is its ability to automatically manage these heterogeneous workloads. It does this by intelligently scheduling and routing the different simulation tasks to minimize interference and maximize performance. For example, it might decide to run certain tasks on different hardware resources to avoid conflicts, or adjust the priority of tasks based on their importance and resource needs.
By taking care of this workload management automatically, Union allows researchers to focus on the core aspects of their simulations, rather than having to constantly monitor and optimize the underlying infrastructure. This can lead to significant time savings and more efficient use of computing resources.
The study on workload interference and intelligent routing in Dragonfly networks and the TACOS algorithm for topology-aware collective operations are examples of research areas that could benefit from the capabilities provided by Union.
Technical Explanation
The Union system is designed to address the challenge of interference between heterogeneous workloads in high-performance computing (HPC) environments. When running a diverse set of tasks, such as network simulations, machine learning models, and scientific computations, on shared computing resources, these workloads can interfere with each other, leading to performance degradation.
Union aims to intelligently schedule and route these simulation tasks to minimize interference and maximize overall performance. It does this by modeling the resource requirements and interference patterns of different workloads, and then using this information to make scheduling decisions that optimize for total throughput.
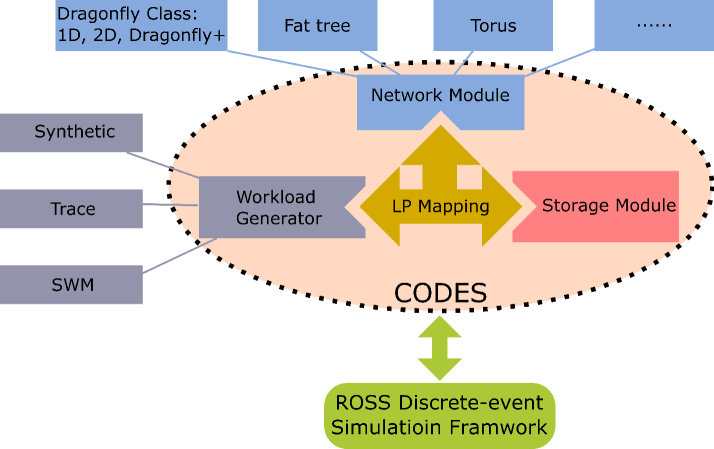
Key components of the Union architecture include:
- Workload Profiler: Collects detailed performance metrics and resource utilization data for each simulation task.
- Interference Model: Analyzes the profiled data to learn how different workloads interact and interfere with each other.
- Scheduler: Uses the interference model to make intelligent scheduling decisions, such as placing compatible tasks on the same hardware or routing tasks to avoid known interference bottlenecks.
The paper on enhancing multi-objective optimization through machine learning and the hybrid unsupervised learning strategy for industrial batch monitoring provide relevant context on the machine learning techniques that could be leveraged within the Union system.
Critical Analysis
The Union paper presents a promising approach to addressing the challenge of workload interference in HPC environments. By automatically managing heterogeneous workloads, it has the potential to significantly improve the efficiency and throughput of complex network simulations and other computational tasks.
However, the paper does not provide a detailed evaluation of the Union system's performance in real-world scenarios. While the authors describe the key components and overall architecture, more empirical evidence is needed to validate the effectiveness of their approach, especially in the face of diverse and dynamically changing workloads.
Additionally, the paper does not address potential limitations or edge cases that could arise when deploying Union in production environments. For example, the system's ability to handle highly volatile or unpredictable workloads, or its scalability and robustness when managing a large number of simulation tasks, are not clearly discussed.
The collaborative optimization of wireless communication and computing resource allocation is a related research area that could provide valuable insights into the challenges of resource management in complex, heterogeneous computing environments.
Conclusion
The Union paper presents an innovative approach to managing the interference between heterogeneous workloads in high-performance computing environments, with a focus on accelerating network simulations. By automatically scheduling and routing simulation tasks to minimize interference, Union has the potential to significantly improve the efficiency and throughput of these computationally intensive workloads.
While the paper outlines the key components and architectural design of the Union system, further empirical evaluation and analysis of its real-world performance and scalability are needed to fully assess its capabilities and potential impact. Nonetheless, the core ideas behind Union represent an important step forward in addressing the challenges of resource management and workload interference in HPC, with implications for a wide range of computational domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Union: An Automatic Workload Manager for Accelerating Network Simulation
Xin Wang, Misbah Mubarak, Yao Kang, Robert B. Ross, Zhiling Lan
With the rapid growth of the machine learning applications, the workloads of future HPC systems are anticipated to be a mix of scientific simulation, big data analytics, and machine learning applications. Simulation is a great research vehicle to understand the performance implications of co-running scientific applications with big data and machine learning workloads on large-scale systems. In this paper, we present Union, a workload manager that provides an automatic framework to facilitate hybrid workload simulation in CODES. Furthermore, we use Union, along with CODES, to investigate various hybrid workloads composed of traditional simulation applications and emerging learning applications on two dragonfly systems. The experiment results show that both message latency and communication time are important performance metrics to evaluate network interference. Network interference on HPC applications is more reflected by the message latency variation, whereas ML application performance depends more on the communication time.
Read more4/5/2024

0
LuWu: An End-to-End In-Network Out-of-Core Optimizer for 100B-Scale Model-in-Network Data-Parallel Training on Distributed GPUs
Mo Sun, Zihan Yang, Changyue Liao, Yingtao Li, Fei Wu, Zeke Wang
The recent progress made in large language models (LLMs) has brought tremendous application prospects to the world. The growing model size demands LLM training on multiple GPUs, while data parallelism is the most popular distributed training strategy due to its simplicity, efficiency, and scalability. Current systems adopt the model-sharded data parallelism to enable memory-efficient training, however, existing model-sharded data-parallel systems fail to efficiently utilize GPU on a commodity GPU cluster with 100 Gbps (or 200 Gbps) inter-GPU bandwidth due to 1) severe interference between collective operation and GPU computation and 2) heavy CPU optimizer overhead. Recent works propose in-network aggregation (INA) to relieve the network bandwidth pressure in data-parallel training, but they are incompatible with model sharding due to the network design. To this end, we propose LuWu, a novel in-network optimizer that enables efficient model-in-network data-parallel training of a 100B-scale model on distributed GPUs. Such new data-parallel paradigm keeps a similar communication pattern as model-sharded data parallelism but with a centralized in-network optimizer execution. The key idea is to offload the entire optimizer states and parameters from GPU workers onto an in-network optimizer node and to offload the entire collective communication from GPU-implemented NCCL to SmartNIC-SmartSwitch co-optimization. The experimental results show that LuWu outperforms the state-of-the-art training system by 3.98x when training on a 175B model on an 8-worker cluster.
Read more9/4/2024
0
Towards Universal Performance Modeling for Machine Learning Training on Multi-GPU Platforms
Zhongyi Lin, Ning Sun, Pallab Bhattacharya, Xizhou Feng, Louis Feng, John D. Owens
Characterizing and predicting the training performance of modern machine learning (ML) workloads on compute systems with compute and communication spread between CPUs, GPUs, and network devices is not only the key to optimization and planning but also a complex goal to achieve. The primary challenges include the complexity of synchronization and load balancing between CPUs and GPUs, the variance in input data distribution, and the use of different communication devices and topologies (e.g., NVLink, PCIe, network cards) that connect multiple compute devices, coupled with the desire for flexible training configurations. Built on top of our prior work for single-GPU platforms, we address these challenges and enable multi-GPU performance modeling by incorporating (1) data-distribution-aware performance models for embedding table lookup, and (2) data movement prediction of communication collectives, into our upgraded performance modeling pipeline equipped with inter-and intra-rank synchronization for ML workloads trained on multi-GPU platforms. Beyond accurately predicting the per-iteration training time of DLRM models with random configurations with a geomean error of 5.21% on two multi-GPU platforms, our prediction pipeline generalizes well to other types of ML workloads, such as Transformer-based NLP models with a geomean error of 3.00%. Moreover, even without actually running ML workloads like DLRMs on the hardware, it is capable of generating insights such as quickly selecting the fastest embedding table sharding configuration (with a success rate of 85%).
Read more4/30/2024

0
LLMServingSim: A HW/SW Co-Simulation Infrastructure for LLM Inference Serving at Scale
Jaehong Cho, Minsu Kim, Hyunmin Choi, Guseul Heo, Jongse Park
Recently, there has been an extensive research effort in building efficient large language model (LLM) inference serving systems. These efforts not only include innovations in the algorithm and software domains but also constitute developments of various hardware acceleration techniques. Nevertheless, there is a lack of simulation infrastructure capable of accurately modeling versatile hardware-software behaviors in LLM serving systems without extensively extending the simulation time. This paper aims to develop an effective simulation tool, called LLMServingSim, to support future research in LLM serving systems. In designing LLMServingSim, we focus on two limitations of existing simulators: (1) they lack consideration of the dynamic workload variations of LLM inference serving due to its autoregressive nature, and (2) they incur repetitive simulations without leveraging algorithmic redundancies in LLMs. To address these limitations, LLMServingSim simulates the LLM serving in the granularity of iterations, leveraging the computation redundancies across decoder blocks and reusing the simulation results from previous iterations. Additionally, LLMServingSim provides a flexible framework that allows users to plug in any accelerator compiler-and-simulation stacks for exploring various system designs with heterogeneous processors. Our experiments demonstrate that LLMServingSim produces simulation results closely following the performance behaviors of real GPU-based LLM serving system with less than 14.7% error rate, while offering 91.5x faster simulation speed compared to existing accelerator simulators.
Read more8/13/2024