Benchmarking Machine Learning Applications on Heterogeneous Architecture using Reframe

0
⚙️
Sign in to get full access
Overview
- This paper presents a framework called Reframe for benchmarking machine learning applications on heterogeneous hardware architectures.
- Reframe is designed to simplify the process of running benchmarks, collecting performance data, and analyzing results across different hardware platforms.
- The paper demonstrates the use of Reframe to benchmark several popular machine learning models and datasets on a variety of hardware, including GPUs, Graphcore, and Cerebras systems.
Plain English Explanation
Benchmarking is the process of testing the performance of computer systems or applications to understand their capabilities and limitations. This is particularly important for machine learning, where the performance of different hardware can have a significant impact on the speed and efficiency of training and inference.
The researchers in this paper developed a tool called Reframe to make benchmarking machine learning workloads on different hardware systems easier. Reframe allows users to easily set up, run, and analyze the results of these benchmarks across a wide range of hardware, including GPUs, Graphcore, and Cerebras systems.
By simplifying the benchmarking process, Reframe can help researchers and developers better understand the performance of their machine learning models on different hardware configurations. This information can then be used to optimize the deployment of these models on the most suitable hardware, improve hardware-aware model design, and make more informed decisions about hardware investments.
Technical Explanation
The paper introduces Reframe, a framework for benchmarking machine learning applications on heterogeneous hardware architectures. Reframe is designed to simplify the process of running benchmarks, collecting performance data, and analyzing results across different hardware platforms.
Reframe provides a consistent and flexible interface for defining and running benchmarks, with support for a wide range of hardware, including GPUs, Graphcore, and Cerebras systems. The framework is built on top of Kubernetes, allowing it to be easily deployed and scaled in a variety of environments, from local development setups to large-scale HPC clusters.
The paper demonstrates the use of Reframe to benchmark several popular machine learning models and datasets, including MLPerf, on a variety of hardware configurations. The results show that Reframe can effectively capture the performance characteristics of these workloads across different architectures, providing valuable insights to guide hardware selection and model optimization.
Critical Analysis
The paper presents a comprehensive and well-designed framework for benchmarking machine learning applications on heterogeneous hardware. However, there are a few potential limitations and areas for further research that could be considered:
-
The paper does not provide a detailed comparison of Reframe's performance and capabilities against other existing benchmarking tools or frameworks. A more thorough comparative analysis could help users understand the unique strengths and weaknesses of the Reframe approach.
-
The paper focuses on a relatively narrow set of machine learning workloads and hardware platforms. Expanding the benchmarking coverage to a wider range of models, datasets, and emerging hardware technologies could further demonstrate the versatility and robustness of the Reframe framework.
-
The paper does not discuss the potential challenges or limitations of using a Kubernetes-based approach for benchmarking, such as the overhead of containerization or potential issues with resource management and isolation. Addressing these concerns could help users better understand the tradeoffs involved in using Reframe.
-
The paper could have provided more detailed guidance on how to interpret and act on the performance data collected using Reframe, particularly for users who may not be experts in system performance analysis and optimization.
Overall, the Reframe framework presented in this paper represents a valuable contribution to the field of machine learning benchmarking and deployment on heterogeneous hardware. By addressing the limitations and areas for further research, the framework could be further strengthened and become an increasingly useful tool for the research and development community.
Conclusion
The paper introduces Reframe, a framework for benchmarking machine learning applications on heterogeneous hardware architectures. Reframe simplifies the process of running benchmarks, collecting performance data, and analyzing results across a wide range of hardware platforms, including GPUs, Graphcore, and Cerebras systems.
The paper demonstrates the use of Reframe to benchmark several popular machine learning models and datasets, providing valuable insights into the performance characteristics of these workloads on different hardware configurations. By making the benchmarking process more accessible and streamlined, Reframe can help researchers and developers make more informed decisions about hardware selection, model optimization, and ultimately, the deployment of machine learning applications in real-world scenarios.
The Reframe framework represents an important step forward in the field of machine learning benchmarking and deployment, and its continued development and adoption could have significant implications for the efficiency and sustainability of AI-powered systems across various industries and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
0
Benchmarking Machine Learning Applications on Heterogeneous Architecture using Reframe
Christopher Rae, Joseph K. L. Lee, James Richings, Michele Weiland
With the rapid increase in machine learning workloads performed on HPC systems, it is beneficial to regularly perform machine learning specific benchmarks to monitor performance and identify issues. Furthermore, as part of the Edinburgh International Data Facility, EPCC currently hosts a wide range of machine learning accelerators including Nvidia GPUs, the Graphcore Bow Pod64 and Cerebras CS-2, which are managed via Kubernetes and Slurm. We extended the Reframe framework to support the Kubernetes scheduler backend, and utilise Reframe to perform machine learning benchmarks, and we discuss the preliminary results collected and challenges involved in integrating Reframe across multiple platforms and architectures.
Read more4/26/2024
0
Towards Universal Performance Modeling for Machine Learning Training on Multi-GPU Platforms
Zhongyi Lin, Ning Sun, Pallab Bhattacharya, Xizhou Feng, Louis Feng, John D. Owens
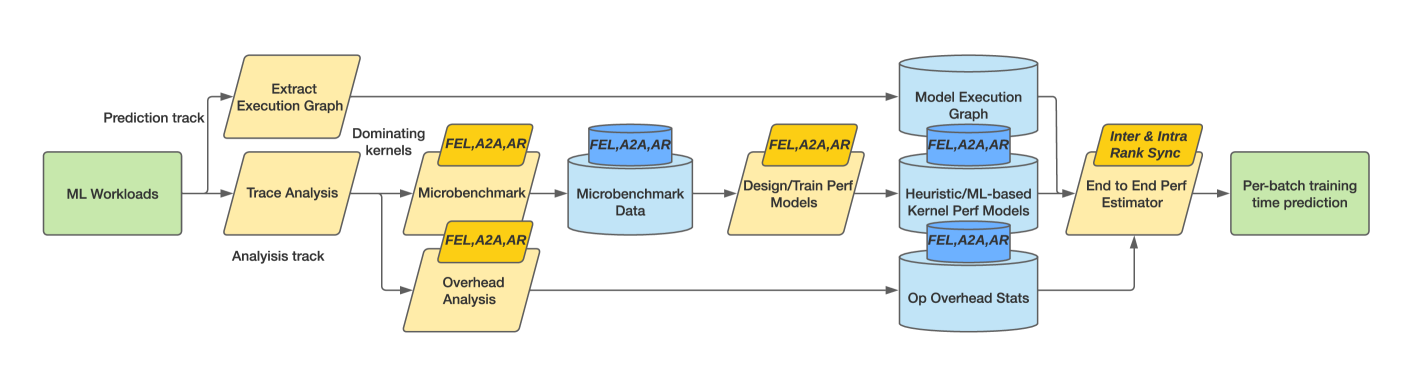
Characterizing and predicting the training performance of modern machine learning (ML) workloads on compute systems with compute and communication spread between CPUs, GPUs, and network devices is not only the key to optimization and planning but also a complex goal to achieve. The primary challenges include the complexity of synchronization and load balancing between CPUs and GPUs, the variance in input data distribution, and the use of different communication devices and topologies (e.g., NVLink, PCIe, network cards) that connect multiple compute devices, coupled with the desire for flexible training configurations. Built on top of our prior work for single-GPU platforms, we address these challenges and enable multi-GPU performance modeling by incorporating (1) data-distribution-aware performance models for embedding table lookup, and (2) data movement prediction of communication collectives, into our upgraded performance modeling pipeline equipped with inter-and intra-rank synchronization for ML workloads trained on multi-GPU platforms. Beyond accurately predicting the per-iteration training time of DLRM models with random configurations with a geomean error of 5.21% on two multi-GPU platforms, our prediction pipeline generalizes well to other types of ML workloads, such as Transformer-based NLP models with a geomean error of 3.00%. Moreover, even without actually running ML workloads like DLRMs on the hardware, it is capable of generating insights such as quickly selecting the fastest embedding table sharding configuration (with a success rate of 85%).
Read more4/30/2024

0
HPAC-ML: A Programming Model for Embedding ML Surrogates in Scientific Applications
Zane Fink, Konstantinos Parasyris, Praneet Rathi, Giorgis Georgakoudis, Harshitha Menon, Peer-Timo Bremer
Recent advancements in Machine Learning (ML) have substantially improved its predictive and computational abilities, offering promising opportunities for surrogate modeling in scientific applications. By accurately approximating complex functions with low computational cost, ML-based surrogates can accelerate scientific applications by replacing computationally intensive components with faster model inference. However, integrating ML models into these applications remains a significant challenge, hindering the widespread adoption of ML surrogates as an approximation technique in modern scientific computing. We propose an easy-to-use directive-based programming model that enables developers to seamlessly describe the use of ML models in scientific applications. The runtime support, as instructed by the programming model, performs data assimilation using the original algorithm and can replace the algorithm with model inference. Our evaluation across five benchmarks, testing over 5000 ML models, shows up to 83.6x speed improvements with minimal accuracy loss (as low as 0.01 RMSE).
Read more8/28/2024

0
Enriching the Machine Learning Workloads in BigBench
Matthias Polag, Todor Ivanov, Timo Eichhorn
In the era of Big Data and the growing support for Machine Learning, Deep Learning and Artificial Intelligence algorithms in the current software systems, there is an urgent need of standardized application benchmarks that stress test and evaluate these new technologies. Relying on the standardized BigBench (TPCx-BB) benchmark, this work enriches the improved BigBench V2 with three new workloads and expands the coverage of machine learning algorithms. Our workloads utilize multiple algorithms and compare different implementations for the same algorithm across several popular libraries like MLlib, SystemML, Scikit-learn and Pandas, demonstrating the relevance and usability of our benchmark extension.
Read more6/18/2024