TD3 Based Collision Free Motion Planning for Robot Navigation
2405.15460
0
0
📉
Abstract
This paper addresses the challenge of collision-free motion planning in automated navigation within complex environments. Utilizing advancements in Deep Reinforcement Learning (DRL) and sensor technologies like LiDAR, we propose the TD3-DWA algorithm, an innovative fusion of the traditional Dynamic Window Approach (DWA) with the Twin Delayed Deep Deterministic Policy Gradient (TD3). This hybrid algorithm enhances the efficiency of robotic path planning by optimizing the sampling interval parameters of DWA to effectively navigate around both static and dynamic obstacles. The performance of the TD3-DWA algorithm is validated through various simulation experiments, demonstrating its potential to significantly improve the reliability and safety of autonomous navigation systems.
Create account to get full access
Overview
- This paper proposes a new algorithm called TD3-DWA for collision-free motion planning in autonomous navigation.
- The algorithm combines the traditional Dynamic Window Approach (DWA) with the Twin Delayed Deep Deterministic Policy Gradient (TD3) from deep reinforcement learning.
- The goal is to optimize the sampling interval parameters of DWA to enable robots to navigate around both static and dynamic obstacles more effectively.
- The performance of the TD3-DWA algorithm is evaluated through various simulation experiments.
Plain English Explanation
The paper addresses the challenge of helping robots navigate safely through complex environments without colliding with obstacles. To do this, the researchers developed a new algorithm that combines two existing techniques: the Dynamic Window Approach (DWA) and deep reinforcement learning.
The Dynamic Window Approach is a method that robots can use to plan their movements and avoid obstacles. It works by considering the robot's current speed and direction, and then calculating the best way to adjust these to navigate around any obstacles. The deep reinforcement learning part of the new algorithm helps optimize the DWA's parameters so that the robot can make even better decisions about how to move.
By fusing these two techniques together, the researchers created the TD3-DWA algorithm, which allows robots to plan their paths more efficiently and reliably, even when navigating around both stationary and moving obstacles. They tested this algorithm in computer simulations and found that it performed very well, suggesting it could be a valuable tool for improving the safety and capabilities of autonomous navigation systems.
Technical Explanation
The paper proposes the TD3-DWA algorithm, which combines the Dynamic Window Approach (DWA) with the Twin Delayed Deep Deterministic Policy Gradient (TD3) from deep reinforcement learning. The goal is to optimize the sampling interval parameters of the DWA to enhance the robot's ability to navigate around both static and dynamic obstacles.
The DWA is a widely used method for robot motion planning that considers the robot's kinematic constraints and the surrounding obstacles to generate safe trajectories. The TD3 is a deep reinforcement learning algorithm that can learn optimal control policies from interaction with the environment. By integrating these two approaches, the TD3-DWA algorithm can leverage the strengths of both techniques to improve the efficiency and reliability of autonomous navigation.
The performance of the TD3-DWA algorithm is evaluated through extensive simulation experiments involving various scenarios with both static and dynamic obstacles. The results demonstrate that the proposed algorithm can significantly outperform the standalone DWA in terms of path length, travel time, and collision avoidance. This suggests that the TD3-DWA has the potential to enhance the safety and capabilities of real-world autonomous navigation systems.
Critical Analysis
The paper provides a thorough evaluation of the TD3-DWA algorithm through simulation experiments, but it does not address some potential limitations or areas for further research.
One concern is the reliance on LiDAR sensors, which may not be available or practical in all real-world autonomous navigation applications. It would be valuable to explore how the algorithm could be adapted to work with other sensor modalities, such as vision-based perception or sensor fusion.
Additionally, the paper does not explore the algorithm's performance in more complex, dynamic environments with unpredictable obstacle motion or changes in the environment. Further research could investigate the robustness of the TD3-DWA approach in these more challenging scenarios.
Overall, the proposed TD3-DWA algorithm represents an interesting and promising step forward in collision-free motion planning for autonomous navigation. However, additional research and real-world testing would be beneficial to better understand the algorithm's limitations and further refine its capabilities.
Conclusion
This paper presents the TD3-DWA algorithm, which combines the Dynamic Window Approach with deep reinforcement learning to optimize robot navigation in complex environments. The key innovation is the fusion of these two techniques, which allows the algorithm to more effectively plan collision-free paths around both static and dynamic obstacles.
The simulation results demonstrate the potential of the TD3-DWA algorithm to significantly improve the reliability and safety of autonomous navigation systems. While the paper does not address all possible limitations, it provides a valuable contribution to the field of robotics and autonomous vehicle research. Further development and real-world testing of this approach could lead to more robust and capable navigation systems that can safely navigate a wide range of environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Real-time Motion Planning for autonomous vehicles in dynamic environments
Mohammad Dehghani Tezerjani, Dominic Carrillo, Deyuan Qu, Sudip Dhakal, Amir Mirzaeinia, Qing Yang
0
0
Recent advancements in self-driving car technologies have enabled them to navigate autonomously through various environments. However, one of the critical challenges in autonomous vehicle operation is trajectory planning, especially in dynamic environments with moving obstacles. This research aims to tackle this challenge by proposing a robust algorithm tailored for autonomous cars operating in dynamic environments with moving obstacles. The algorithm introduces two main innovations. Firstly, it defines path density by adjusting the number of waypoints along the trajectory, optimizing their distribution for accuracy in curved areas and reducing computational complexity in straight sections. Secondly, it integrates hierarchical motion planning algorithms, combining global planning with an enhanced $A^*$ graph-based method and local planning using the time elastic band algorithm with moving obstacle detection considering different motion models. The proposed algorithm is adaptable for different vehicle types and mobile robots, making it versatile for real-world applications. Simulation results demonstrate its effectiveness across various conditions, promising safer and more efficient navigation for autonomous vehicles in dynamic environments. These modifications significantly improve trajectory planning capabilities, addressing a crucial aspect of autonomous vehicle technology.
6/6/2024
💬
DREAM: Decentralized Real-time Asynchronous Probabilistic Trajectory Planning for Collision-free Multi-Robot Navigation in Cluttered Environments
Bask{i}n c{S}enbac{s}lar, Gaurav S. Sukhatme
0
0
Collision-free navigation in cluttered environments with static and dynamic obstacles is essential for many multi-robot tasks. Dynamic obstacles may also be interactive, i.e., their behavior varies based on the behavior of other entities. We propose a novel representation for interactive behavior of dynamic obstacles and a decentralized real-time multi-robot trajectory planning algorithm allowing inter-robot collision avoidance as well as static and dynamic obstacle avoidance. Our planner simulates the behavior of dynamic obstacles, accounting for interactivity. We account for the perception inaccuracy of static and prediction inaccuracy of dynamic obstacles. We handle asynchronous planning between teammates and message delays, drops, and re-orderings. We evaluate our algorithm in simulations using 25400 random cases and compare it against three state-of-the-art baselines using 2100 random cases. Our algorithm achieves up to 1.68x success rate using as low as 0.28x time in single-robot, and up to 2.15x success rate using as low as 0.36x time in multi-robot cases compared to the best baseline. We implement our planner on real quadrotors to show its real-world applicability.
5/21/2024

Interactive-FAR:Interactive, Fast and Adaptable Routing for Navigation Among Movable Obstacles in Complex Unknown Environments
Botao He, Guofei Chen, Wenshan Wang, Ji Zhang, Cornelia Fermuller, Yiannis Aloimonos
0
0
This paper introduces a real-time algorithm for navigating complex unknown environments cluttered with movable obstacles. Our algorithm achieves fast, adaptable routing by actively attempting to manipulate obstacles during path planning and adjusting the global plan from sensor feedback. The main contributions include an improved dynamic Directed Visibility Graph (DV-graph) for rapid global path searching, a real-time interaction planning method that adapts online from new sensory perceptions, and a comprehensive framework designed for interactive navigation in complex unknown or partially known environments. Our algorithm is capable of replanning the global path in several milliseconds. It can also attempt to move obstacles, update their affordances, and adapt strategies accordingly. Extensive experiments validate that our algorithm reduces the travel time by 33%, achieves up to 49% higher path efficiency, and runs faster than traditional methods by orders of magnitude in complex environments. It has been demonstrated to be the most efficient solution in terms of speed and efficiency for interactive navigation in environments of such complexity. We also open-source our code in the docker demo to facilitate future research.
4/12/2024
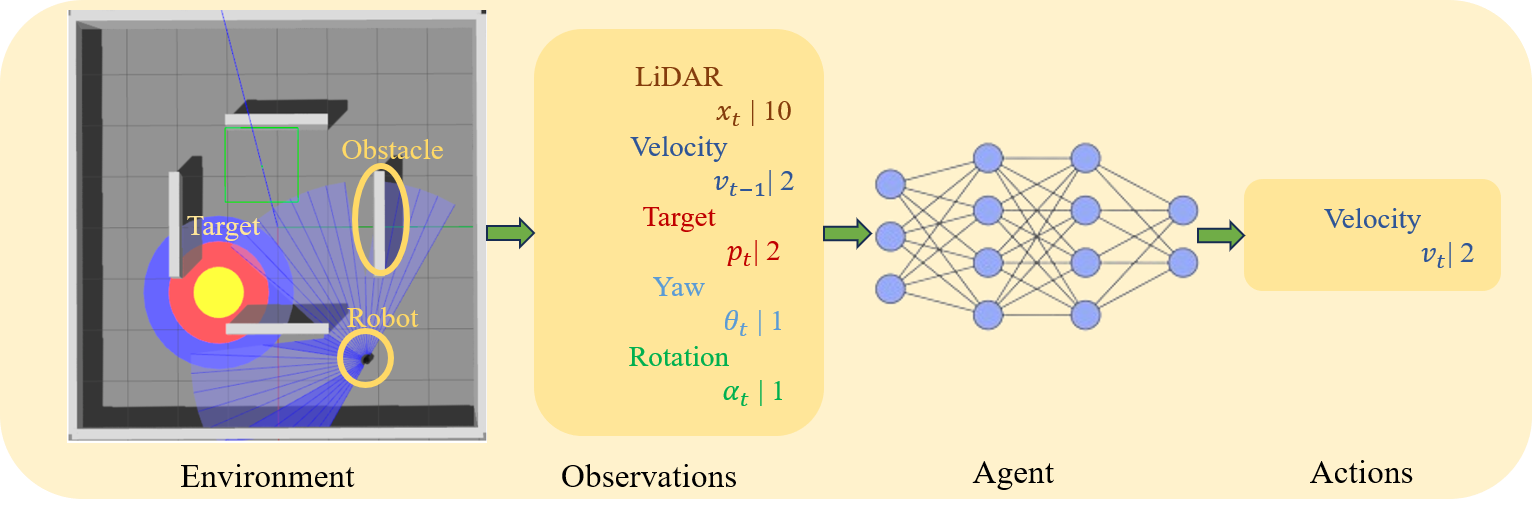
Deep Reinforcement Learning with Enhanced PPO for Safe Mobile Robot Navigation
Hamid Taheri, Seyed Rasoul Hosseini
0
0
Collision-free motion is essential for mobile robots. Most approaches to collision-free and efficient navigation with wheeled robots require parameter tuning by experts to obtain good navigation behavior. This study investigates the application of deep reinforcement learning to train a mobile robot for autonomous navigation in a complex environment. The robot utilizes LiDAR sensor data and a deep neural network to generate control signals guiding it toward a specified target while avoiding obstacles. We employ two reinforcement learning algorithms in the Gazebo simulation environment: Deep Deterministic Policy Gradient and proximal policy optimization. The study introduces an enhanced neural network structure in the Proximal Policy Optimization algorithm to boost performance, accompanied by a well-designed reward function to improve algorithm efficacy. Experimental results conducted in both obstacle and obstacle-free environments underscore the effectiveness of the proposed approach. This research significantly contributes to the advancement of autonomous robotics in complex environments through the application of deep reinforcement learning.
5/28/2024