OV-NeRF: Open-vocabulary Neural Radiance Fields with Vision and Language Foundation Models for 3D Semantic Understanding

0
🧠
Sign in to get full access
Overview
- The paper introduces OV-NeRF, a method that enhances the capabilities of Neural Radiance Fields (NeRFs) in open-vocabulary 3D semantic perception tasks.
- NeRFs are a powerful representation for encoding the geometric and appearance characteristics of 3D scenes.
- Improving NeRFs for open-vocabulary semantic perception is an important focus in the field.
- Current methods that directly extract semantics from Contrastive Language-Image Pretraining (CLIP) face challenges due to noisy and view-inconsistent semantics.
Plain English Explanation
The paper presents OV-NeRF, a new approach that aims to improve the ability of Neural Radiance Fields (NeRFs) to understand the semantic content of 3D scenes. NeRFs are a powerful way to represent the geometry and appearance of 3D environments, and being able to extract semantic information from them is an important goal.
The researchers found that existing methods that try to get semantic information directly from a popular AI system called CLIP run into problems. CLIP can provide noisy and inconsistent semantic labels when applied to different views of the same 3D scene. To address this, OV-NeRF uses two key strategies:
-
Region Semantic Ranking (RSR): This technique leverages 2D mask proposals from another AI system called Segment Anything to help clean up the noisy semantics from CLIP for each individual view of the scene.
-
Cross-view Self-enhancement (CSE): This approach uses the 3D semantic information generated by the OV-NeRF model itself, rather than relying on the inconsistent 2D semantics from CLIP. This helps reduce ambiguity and improve semantic consistency across different views of the scene.
By using these two strategies, OV-NeRF is able to significantly outperform existing methods on benchmarks for 3D semantic understanding. The researchers show their approach works well across different versions of the CLIP system, demonstrating its robustness.
Technical Explanation
The core innovation of the OV-NeRF method is the use of two complementary strategies to enhance semantic field learning from NeRFs:
-
Region Semantic Ranking (RSR): This technique leverages 2D mask proposals derived from the Segment Anything (SAM) model to rectify the noisy semantics provided by CLIP for each individual training view. By focusing the semantic learning on the most relevant image regions, RSR facilitates more accurate semantic field learning.
-
Cross-view Self-enhancement (CSE): To address the challenge of view-inconsistent semantics from CLIP, CSE leverages the 3D consistent semantics generated from the well-trained OV-NeRF semantic field itself. Rather than simply using the 2D inconsistent semantics from CLIP, CSE aims to reduce ambiguity and enhance overall semantic consistency across different views by utilizing the model's own predictions.
Extensive experiments on the Replica and ScanNet datasets demonstrate that OV-NeRF outperforms current state-of-the-art methods by a significant margin, improving the mean Intersection-over-Union (mIoU) metric by 20.31% and 18.42% respectively. Furthermore, the approach exhibits consistent superior results across various CLIP configurations, verifying its robustness.
Critical Analysis
The OV-NeRF paper presents a compelling solution to the challenges of extracting consistent and accurate semantic information from NeRFs. The proposed strategies of RSR and CSE effectively address the issues of noisy and view-inconsistent semantics that plague existing methods.
However, the paper does not delve into potential limitations or caveats of the approach. For example, it would be valuable to understand the computational overhead and training time requirements of the additional components introduced by OV-NeRF, as these factors can be important considerations for real-world applications.
Additionally, the paper could benefit from a more thorough discussion of the failure cases or edge cases where OV-NeRF may struggle. Exploring the types of scenes, object categories, or viewing conditions that pose challenges for the method would help readers understand its practical limitations and guide future research.
Overall, the OV-NeRF research represents a significant advance in the field of open-vocabulary 3D semantic perception, and the use of complementary single-view and cross-view strategies is a promising direction. Further exploration of the method's robustness, efficiency, and edge cases could strengthen the contribution and provide a more comprehensive understanding of its capabilities and limitations.
Conclusion
The OV-NeRF paper introduces an innovative approach to enhance the semantic understanding capabilities of Neural Radiance Fields (NeRFs) for 3D scenes. By addressing the challenges of noisy and view-inconsistent semantics from existing methods, OV-NeRF demonstrates significant performance improvements on benchmark tasks.
The key technical contributions, Region Semantic Ranking (RSR) and Cross-view Self-enhancement (CSE), effectively leverage pre-trained vision and language models to refine and regularize the semantic field learning process. This allows OV-NeRF to outperform state-of-the-art methods and exhibit consistent performance across different CLIP configurations.
The potential implications of this research are broad, as enhancing the semantic understanding of 3D environments has numerous applications in areas such as augmented reality, robotics, and virtual reality. By bridging the gap between the powerful geometric representation of NeRFs and the rich semantic information from language models, OV-NeRF represents an important step forward in the field of open-vocabulary 3D perception.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
0
OV-NeRF: Open-vocabulary Neural Radiance Fields with Vision and Language Foundation Models for 3D Semantic Understanding
Guibiao Liao, Kaichen Zhou, Zhenyu Bao, Kanglin Liu, Qing Li
The development of Neural Radiance Fields (NeRFs) has provided a potent representation for encapsulating the geometric and appearance characteristics of 3D scenes. Enhancing the capabilities of NeRFs in open-vocabulary 3D semantic perception tasks has been a recent focus. However, current methods that extract semantics directly from Contrastive Language-Image Pretraining (CLIP) for semantic field learning encounter difficulties due to noisy and view-inconsistent semantics provided by CLIP. To tackle these limitations, we propose OV-NeRF, which exploits the potential of pre-trained vision and language foundation models to enhance semantic field learning through proposed single-view and cross-view strategies. First, from the single-view perspective, we introduce Region Semantic Ranking (RSR) regularization by leveraging 2D mask proposals derived from Segment Anything (SAM) to rectify the noisy semantics of each training view, facilitating accurate semantic field learning. Second, from the cross-view perspective, we propose a Cross-view Self-enhancement (CSE) strategy to address the challenge raised by view-inconsistent semantics. Rather than invariably utilizing the 2D inconsistent semantics from CLIP, CSE leverages the 3D consistent semantics generated from the well-trained semantic field itself for semantic field training, aiming to reduce ambiguity and enhance overall semantic consistency across different views. Extensive experiments validate our OV-NeRF outperforms current state-of-the-art methods, achieving a significant improvement of 20.31% and 18.42% in mIoU metric on Replica and ScanNet, respectively. Furthermore, our approach exhibits consistent superior results across various CLIP configurations, further verifying its robustness. Project page: https://github.com/pcl3dv/OV-NeRF.
Read more9/24/2024

0
Rethinking Open-Vocabulary Segmentation of Radiance Fields in 3D Space
Hyunjee Lee, Youngsik Yun, Jeongmin Bae, Seoha Kim, Youngjung Uh
Understanding the 3D semantics of a scene is a fundamental problem for various scenarios such as embodied agents. While NeRFs and 3DGS excel at novel-view synthesis, previous methods for understanding their semantics have been limited to incomplete 3D understanding: their segmentation results are 2D masks and their supervision is anchored at 2D pixels. This paper revisits the problem set to pursue a better 3D understanding of a scene modeled by NeRFs and 3DGS as follows. 1) We directly supervise the 3D points to train the language embedding field. It achieves state-of-the-art accuracy without relying on multi-scale language embeddings. 2) We transfer the pre-trained language field to 3DGS, achieving the first real-time rendering speed without sacrificing training time or accuracy. 3) We introduce a 3D querying and evaluation protocol for assessing the reconstructed geometry and semantics together. Code, checkpoints, and annotations will be available online. Project page: https://hyunji12.github.io/Open3DRF
Read more8/20/2024

0
NeRF-VO: Real-Time Sparse Visual Odometry with Neural Radiance Fields
Jens Naumann, Binbin Xu, Stefan Leutenegger, Xingxing Zuo
We introduce a novel monocular visual odometry (VO) system, NeRF-VO, that integrates learning-based sparse visual odometry for low-latency camera tracking and a neural radiance scene representation for fine-detailed dense reconstruction and novel view synthesis. Our system initializes camera poses using sparse visual odometry and obtains view-dependent dense geometry priors from a monocular prediction network. We harmonize the scale of poses and dense geometry, treating them as supervisory cues to train a neural implicit scene representation. NeRF-VO demonstrates exceptional performance in both photometric and geometric fidelity of the scene representation by jointly optimizing a sliding window of keyframed poses and the underlying dense geometry, which is accomplished through training the radiance field with volume rendering. We surpass SOTA methods in pose estimation accuracy, novel view synthesis fidelity, and dense reconstruction quality across a variety of synthetic and real-world datasets while achieving a higher camera tracking frequency and consuming less GPU memory.
Read more7/17/2024
0
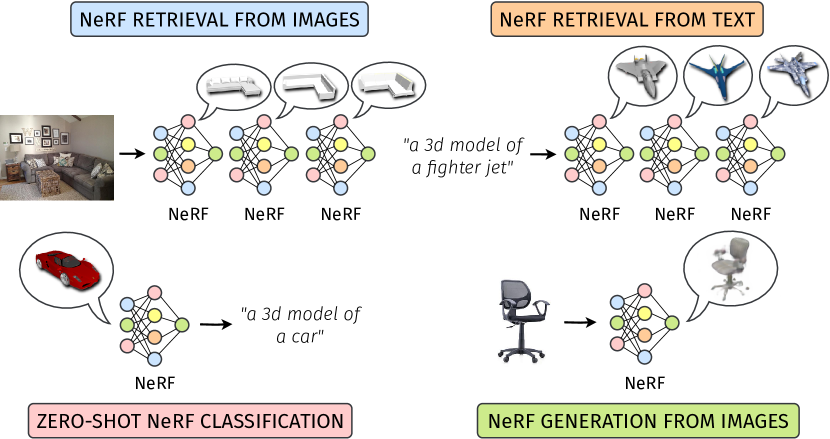
Connecting NeRFs, Images, and Text
Francesco Ballerini, Pierluigi Zama Ramirez, Roberto Mirabella, Samuele Salti, Luigi Di Stefano
Neural Radiance Fields (NeRFs) have emerged as a standard framework for representing 3D scenes and objects, introducing a novel data type for information exchange and storage. Concurrently, significant progress has been made in multimodal representation learning for text and image data. This paper explores a novel research direction that aims to connect the NeRF modality with other modalities, similar to established methodologies for images and text. To this end, we propose a simple framework that exploits pre-trained models for NeRF representations alongside multimodal models for text and image processing. Our framework learns a bidirectional mapping between NeRF embeddings and those obtained from corresponding images and text. This mapping unlocks several novel and useful applications, including NeRF zero-shot classification and NeRF retrieval from images or text.
Read more4/12/2024