Overcoming Reward Overoptimization via Adversarial Policy Optimization with Lightweight Uncertainty Estimation

0
Sign in to get full access
Overview
- The paper proposes a novel technique called "Adversarial Policy Optimization with Lightweight Uncertainty Estimation" (APOLE) to overcome the problem of reward overoptimization in reinforcement learning (RL).
- Reward overoptimization can lead to agents pursuing narrow objectives at the expense of broader considerations, which is a significant challenge in building robust and capable AI systems.
- APOLE aims to mitigate this issue by introducing an adversarial training process that encourages the RL agent to consider a wider range of potential outcomes and maintain a more balanced policy.
Plain English Explanation
The paper tackles a crucial problem in the field of reinforcement learning (RL) – reward overoptimization. This occurs when an RL agent becomes overly focused on maximizing a specific reward signal, to the detriment of other important factors. For example, an AI system designed to win a game might learn to exploit loopholes in the game mechanics, rather than developing a well-rounded and adaptable strategy.
Overcoming Reward Overoptimization via Adversarial Policy Optimization with Lightweight Uncertainty Estimation proposes a new method called APOLE to address this issue. The key idea is to introduce an "adversary" during the training process, which tries to find flaws or weaknesses in the agent's policy. This forces the agent to consider a broader range of possible scenarios and maintain a more balanced approach, rather than single-mindedly pursuing the reward.
The authors also incorporate a "lightweight uncertainty estimation" component, which helps the agent better understand the risks and tradeoffs associated with different actions. This additional information can further guide the agent towards a more robust and adaptable policy.
By using this adversarial training approach and uncertainty estimation, the researchers aim to develop RL agents that are less prone to reward overoptimization and better able to handle the complexities of real-world environments. This could have important implications for the development of safe and capable AI systems that can reliably navigate challenging situations.
Technical Explanation
The paper introduces a novel technique called "Adversarial Policy Optimization with Lightweight Uncertainty Estimation" (APOLE) to address the challenge of reward overoptimization in reinforcement learning (RL).
The core idea of APOLE is to incorporate an adversarial training process, where an "adversary" agent is trained to find flaws or weaknesses in the main RL agent's policy. This forces the RL agent to consider a broader range of potential outcomes and maintain a more balanced policy, rather than single-mindedly pursuing the reward.
A2PO: Towards Effective Offline Reinforcement Learning from Humans provides the foundation for the adversarial training component, while Entropy-Regularized Token-Level Policy Optimization for Language Models and Value-Incentivized Preference Optimization: A Unified Approach to Robust and Scalable Reward Learning inform the lightweight uncertainty estimation approach.
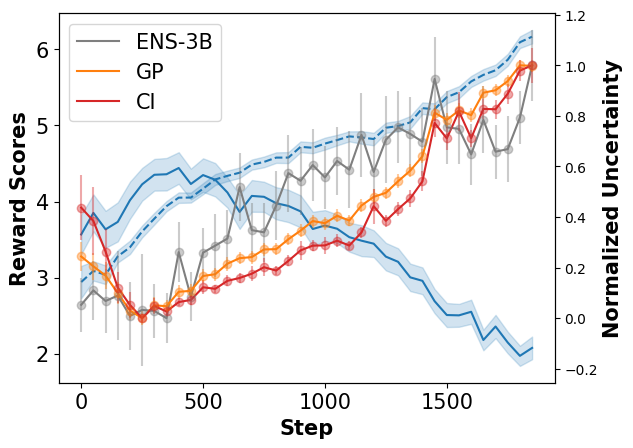
The authors conduct experiments across a range of RL environments, including simulated robotic control tasks and Atari games, to evaluate the effectiveness of APOLE in overcoming reward overoptimization. They compare APOLE to standard RL approaches, as well as other methods designed to mitigate reward overoptimization, such as Scalable Ensembling for Mitigating Reward Overoptimisation.
The results demonstrate that APOLE is able to produce RL agents with more robust and adaptable policies, better able to handle a wider range of scenarios and avoid the pitfalls of reward overoptimization. The lightweight uncertainty estimation component further enhances the agent's decision-making capabilities by providing a more nuanced understanding of the risks and tradeoffs associated with different actions.
Critical Analysis
The paper presents a well-designed and thorough investigation of the APOLE technique, with a strong grounding in relevant prior work. The authors acknowledge the limitations of their approach, such as the potential computational overhead of the adversarial training process and the challenge of scaling the method to very complex environments.
One area for further research could be the exploration of more efficient or scalable ways to implement the adversarial training component, perhaps by leveraging recent advancements in generative adversarial networks (GANs) or other adversarial learning techniques.
Additionally, while the lightweight uncertainty estimation approach seems promising, the paper does not provide a deep analysis of its specific contribution or how it interacts with the adversarial training process. A more detailed investigation of this component and its relative importance within the overall APOLE framework could be a valuable area for future work.
Overall, the paper makes a compelling case for the APOLE method as a promising approach to mitigate reward overoptimization in reinforcement learning, with the potential to contribute to the development of more robust and capable AI systems.
Conclusion
The Overcoming Reward Overoptimization via Adversarial Policy Optimization with Lightweight Uncertainty Estimation paper presents a novel technique called APOLE that aims to address the challenge of reward overoptimization in reinforcement learning. By incorporating an adversarial training process and lightweight uncertainty estimation, APOLE encourages RL agents to develop more balanced and adaptable policies, rather than single-mindedly pursuing narrow reward signals.
The experimental results demonstrate the effectiveness of APOLE in producing RL agents with improved performance and robustness across a range of environments. While the approach has some limitations, the paper highlights the importance of this problem and the potential of APOLE to contribute to the development of safer and more capable AI systems. Further research on scaling and optimizing the method could lead to even more significant advances in this critical area of AI research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Overcoming Reward Overoptimization via Adversarial Policy Optimization with Lightweight Uncertainty Estimation
Xiaoying Zhang, Jean-Francois Ton, Wei Shen, Hongning Wang, Yang Liu
We introduce Adversarial Policy Optimization (AdvPO), a novel solution to the pervasive issue of reward over-optimization in Reinforcement Learning from Human Feedback (RLHF) for Large Language Models (LLMs). Over-optimization occurs when a reward model serves as an imperfect proxy for human preference, and RL-driven policy optimization erroneously exploits reward inaccuracies. In this paper, we begin by introducing a lightweight way to quantify uncertainties in rewards, relying solely on the last layer embeddings of the reward model, without the need for computationally expensive reward ensembles. AdvPO then addresses a distributionally robust optimization problem centred around the confidence interval of the reward model's predictions for policy improvement. Through comprehensive experiments on the Anthropic HH and TL;DR summarization datasets, we illustrate the efficacy of AdvPO in mitigating the overoptimization issue, consequently resulting in enhanced performance as evaluated through human-assisted evaluation.
Read more7/10/2024
0
Provably Mitigating Overoptimization in RLHF: Your SFT Loss is Implicitly an Adversarial Regularizer
Zhihan Liu, Miao Lu, Shenao Zhang, Boyi Liu, Hongyi Guo, Yingxiang Yang, Jose Blanchet, Zhaoran Wang
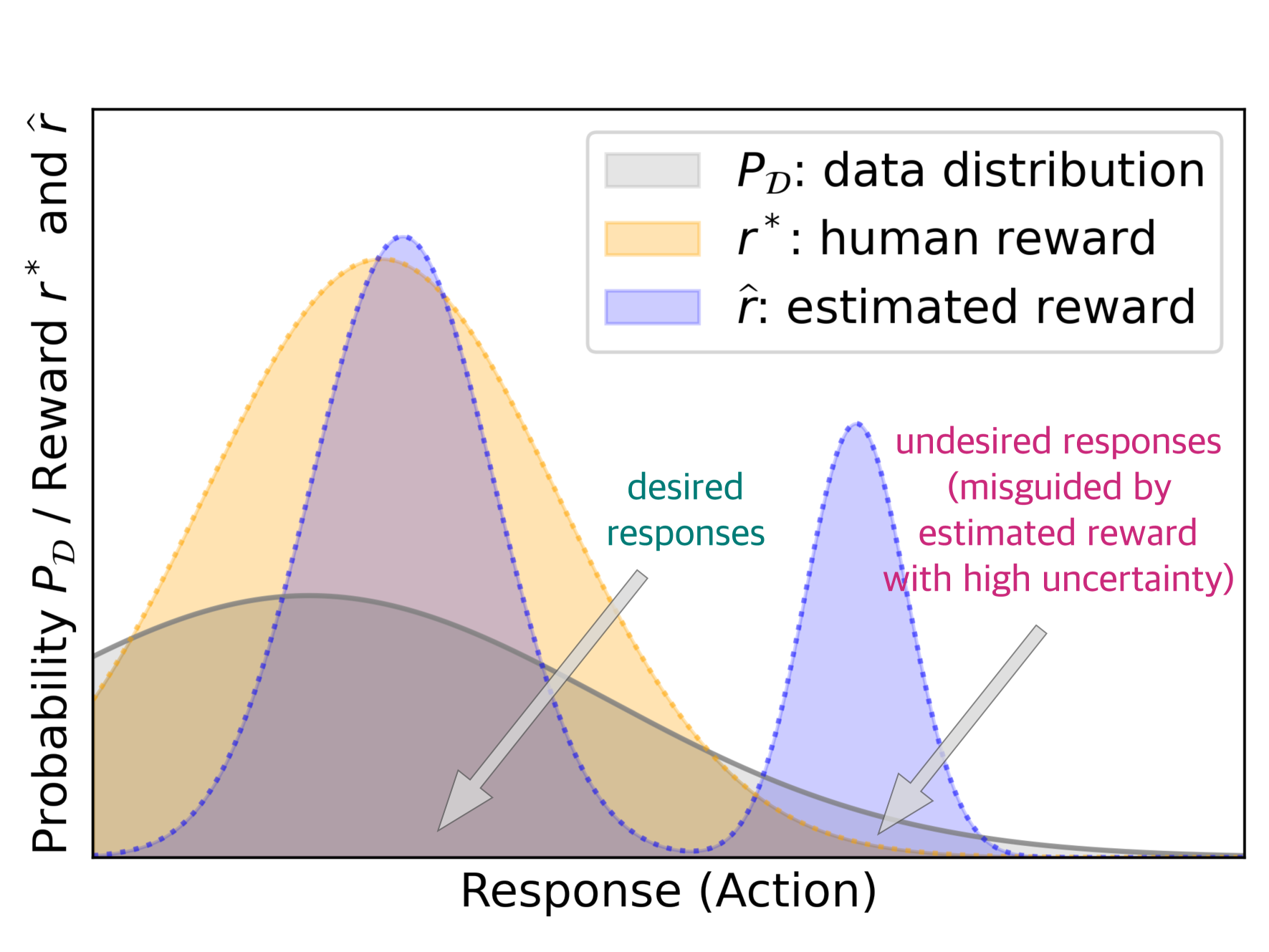
Aligning generative models with human preference via RLHF typically suffers from overoptimization, where an imperfectly learned reward model can misguide the generative model to output undesired responses. We investigate this problem in a principled manner by identifying the source of the misalignment as a form of distributional shift and uncertainty in learning human preferences. To mitigate overoptimization, we first propose a theoretical algorithm that chooses the best policy for an adversarially chosen reward model; one that simultaneously minimizes the maximum likelihood estimation of the loss and a reward penalty term. Here, the reward penalty term is introduced to prevent the policy from choosing actions with spurious high proxy rewards, resulting in provable sample efficiency of the algorithm under a partial coverage style condition. Moving from theory to practice, the proposed algorithm further enjoys an equivalent but surprisingly easy-to-implement reformulation. Using the equivalence between reward models and the corresponding optimal policy, the algorithm features a simple objective that combines: (i) a preference optimization loss that directly aligns the policy with human preference, and (ii) a supervised learning loss that explicitly imitates the policy with a (suitable) baseline distribution. In the context of aligning large language models (LLM), this objective fuses the direct preference optimization (DPO) loss with the supervised fune-tuning (SFT) loss to help mitigate the overoptimization towards undesired responses, for which we name the algorithm Regularized Preference Optimization (RPO). Experiments of aligning LLMs demonstrate the improved performance of RPO compared with DPO baselines. Our work sheds light on the interplay between preference optimization and SFT in tuning LLMs with both theoretical guarantees and empirical evidence.
Read more5/28/2024
0
A2PO: Towards Effective Offline Reinforcement Learning from an Advantage-aware Perspective
Yunpeng Qing, Shunyu liu, Jingyuan Cong, Kaixuan Chen, Yihe Zhou, Mingli Song
Offline reinforcement learning endeavors to leverage offline datasets to craft effective agent policy without online interaction, which imposes proper conservative constraints with the support of behavior policies to tackle the out-of-distribution problem. However, existing works often suffer from the constraint conflict issue when offline datasets are collected from multiple behavior policies, i.e., different behavior policies may exhibit inconsistent actions with distinct returns across the state space. To remedy this issue, recent advantage-weighted methods prioritize samples with high advantage values for agent training while inevitably ignoring the diversity of behavior policy. In this paper, we introduce a novel Advantage-Aware Policy Optimization (A2PO) method to explicitly construct advantage-aware policy constraints for offline learning under mixed-quality datasets. Specifically, A2PO employs a conditional variational auto-encoder to disentangle the action distributions of intertwined behavior policies by modeling the advantage values of all training data as conditional variables. Then the agent can follow such disentangled action distribution constraints to optimize the advantage-aware policy towards high advantage values. Extensive experiments conducted on both the single-quality and mixed-quality datasets of the D4RL benchmark demonstrate that A2PO yields results superior to the counterparts. Our code will be made publicly available.
Read more5/31/2024

0
Entropy-Regularized Token-Level Policy Optimization for Language Agent Reinforcement
Muning Wen, Junwei Liao, Cheng Deng, Jun Wang, Weinan Zhang, Ying Wen
Large Language Models (LLMs) have shown promise as intelligent agents in interactive decision-making tasks. Traditional approaches often depend on meticulously designed prompts, high-quality examples, or additional reward models for in-context learning, supervised fine-tuning, or RLHF. Reinforcement learning (RL) presents a dynamic alternative for LLMs to overcome these dependencies by engaging directly with task-specific environments. Nonetheless, it faces significant hurdles: 1) instability stemming from the exponentially vast action space requiring exploration; 2) challenges in assigning token-level credit based on action-level reward signals, resulting in discord between maximizing rewards and accurately modeling corpus data. In response to these challenges, we introduce Entropy-Regularized Token-level Policy Optimization (ETPO), an entropy-augmented RL method tailored for optimizing LLMs at the token level. At the heart of ETPO is our novel per-token soft Bellman update, designed to harmonize the RL process with the principles of language modeling. This methodology decomposes the Q-function update from a coarse action-level view to a more granular token-level perspective, backed by theoretical proof of optimization consistency. Crucially, this decomposition renders linear time complexity in action exploration. We assess the effectiveness of ETPO within a simulated environment that models data science code generation as a series of multi-step interactive tasks; results underline ETPO's potential as a robust method for refining the interactive decision-making capabilities of language agents. For a more detailed preliminary work describing our motivation for token-level decomposition and applying it in PPO methods, please refer to arXiv:2405.15821.
Read more6/7/2024