Provably Mitigating Overoptimization in RLHF: Your SFT Loss is Implicitly an Adversarial Regularizer
2405.16436
0
0
Abstract
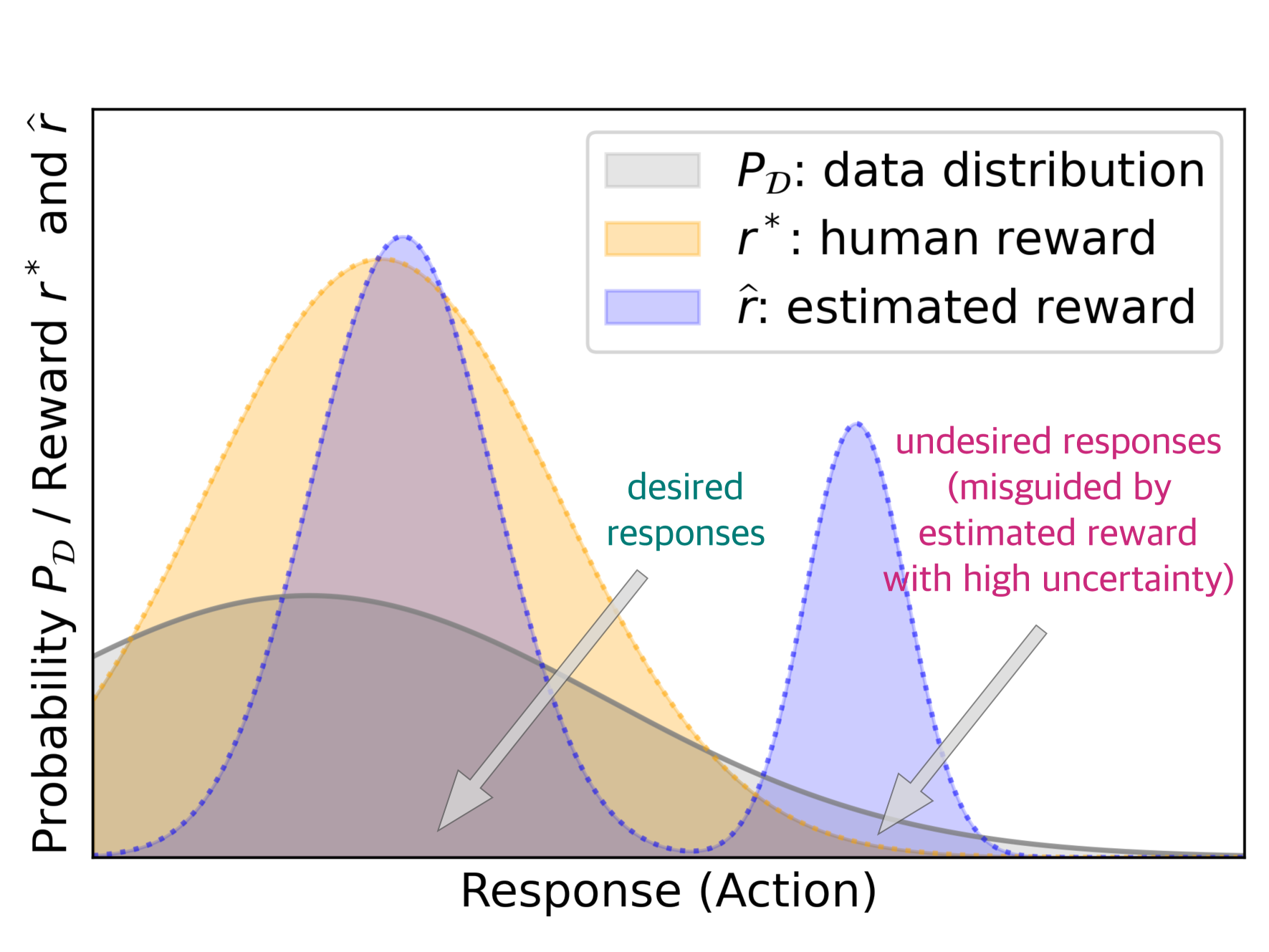
Aligning generative models with human preference via RLHF typically suffers from overoptimization, where an imperfectly learned reward model can misguide the generative model to output undesired responses. We investigate this problem in a principled manner by identifying the source of the misalignment as a form of distributional shift and uncertainty in learning human preferences. To mitigate overoptimization, we first propose a theoretical algorithm that chooses the best policy for an adversarially chosen reward model; one that simultaneously minimizes the maximum likelihood estimation of the loss and a reward penalty term. Here, the reward penalty term is introduced to prevent the policy from choosing actions with spurious high proxy rewards, resulting in provable sample efficiency of the algorithm under a partial coverage style condition. Moving from theory to practice, the proposed algorithm further enjoys an equivalent but surprisingly easy-to-implement reformulation. Using the equivalence between reward models and the corresponding optimal policy, the algorithm features a simple objective that combines: (i) a preference optimization loss that directly aligns the policy with human preference, and (ii) a supervised learning loss that explicitly imitates the policy with a (suitable) baseline distribution. In the context of aligning large language models (LLM), this objective fuses the direct preference optimization (DPO) loss with the supervised fune-tuning (SFT) loss to help mitigate the overoptimization towards undesired responses, for which we name the algorithm Regularized Preference Optimization (RPO). Experiments of aligning LLMs demonstrate the improved performance of RPO compared with DPO baselines. Our work sheds light on the interplay between preference optimization and SFT in tuning LLMs with both theoretical guarantees and empirical evidence.
Create account to get full access
Overview
- This paper explores the problem of overoptimization in Reinforcement Learning with Human Feedback (RLHF), a popular technique for aligning large language models with human preferences.
- The authors show that the standard RLHF loss function, which aims to maximize the reward from a human-provided reward model, can implicitly act as an adversarial regularizer, helping to mitigate overoptimization.
- They provide a theoretical analysis to explain this phenomenon and demonstrate its empirical benefits on various tasks.
Plain English Explanation
When training AI models using Reinforcement Learning with Human Feedback (RLHF), the goal is to align the model's behavior with human preferences. This is often done by having humans provide feedback or ratings on the model's outputs, and then using that feedback to train the model to generate more desirable responses.
However, one key challenge with this approach is the risk of "overoptimization" - where the model becomes too focused on maximizing the feedback score, potentially at the expense of other important qualities like truthfulness, safety, or robustness. This paper from AIModels.FYI explores the issue of overoptimization in more depth.
The authors of this paper show that the standard RLHF loss function, which aims to maximize the reward from a human-provided reward model, can actually help mitigate this overoptimization problem. They provide a theoretical analysis to explain why this is the case, and demonstrate the empirical benefits of this effect on various tasks.
The key insight is that the RLHF loss function acts as an implicit "adversarial regularizer" - it encourages the model to find solutions that are robust to perturbations in the reward function, which helps prevent it from becoming overly specialized or brittle. This relates to the concept of "direct preference optimization" explored in another AIModels.FYI paper.
By understanding this property of the RLHF loss, the authors suggest that it can be leveraged to improve the safety and robustness of AI systems trained using this approach. This could be particularly useful for developing large language models that need to be aligned with human values and preferences while maintaining reliability and trustworthiness.
Technical Explanation
The paper provides a theoretical analysis to show that the standard RLHF loss function, which aims to maximize the reward from a human-provided reward model, can act as an implicit adversarial regularizer, helping to mitigate overoptimization.
The key insight is that the RLHF loss encourages the model to find solutions that are robust to perturbations in the reward function. This is because the reward model used in RLHF is itself an imperfect approximation of human preferences, and so the model must learn to be robust to potential errors or biases in this reward model.
The authors formalize this idea using a game-theoretic framework, showing that the RLHF optimization problem can be viewed as a two-player game between the model and an "adversary" that is trying to perturb the reward function. They prove that the optimal solution to this game corresponds to a model that is robust to such perturbations, which helps prevent overoptimization.
To demonstrate the empirical benefits of this effect, the authors conduct experiments on a variety of tasks, including language modeling, dialogue, and reinforcement learning. They show that models trained using the standard RLHF approach often outperform models trained with other methods, particularly in terms of safety and robustness.
The authors also discuss the limitations of their analysis and suggest directions for future research, such as exploring the role of the reward model architecture and the potential for explicitly incorporating adversarial training into the RLHF framework.
Critical Analysis
The authors provide a compelling theoretical and empirical analysis of the overoptimization problem in RLHF, and the role that the standard RLHF loss function can play in mitigating this issue. The key insight - that the RLHF loss acts as an implicit adversarial regularizer - is both technically insightful and practically relevant for the development of safe and robust AI systems.
However, the paper also acknowledges several important caveats and limitations. For example, the analysis assumes that the reward model used in RLHF is an imperfect approximation of human preferences, but it does not address the challenges of how to actually construct such a reward model in practice. The "Learn Your Reference Model Real Good" paper from AIModels.FYI discusses some of these challenges in more depth.
Additionally, while the empirical results are promising, the experiments are relatively limited in scope and do not necessarily generalize to more complex or open-ended tasks. Further research would be needed to fully understand the broader applicability and limitations of the proposed approach.
Another potential concern is the potential for the RLHF loss to introduce other forms of bias or unintended consequences, such as the "algorithmic bias" issues explored in another AIModels.FYI paper. The authors do not address these potential downsides in depth.
Overall, this paper makes a valuable contribution to the understanding of overoptimization in RLHF and provides a promising direction for future research and development. However, as with any complex and rapidly evolving field, there are still many open questions and challenges that will need to be carefully navigated as the technology continues to advance.
Conclusion
This paper presents an important insight into the problem of overoptimization in Reinforcement Learning with Human Feedback (RLHF), a widely used technique for aligning large language models with human preferences. The authors show that the standard RLHF loss function can actually act as an implicit adversarial regularizer, helping to mitigate overoptimization by encouraging the model to be robust to perturbations in the reward function.
This finding has significant practical implications for the development of safe and reliable AI systems, as overoptimization is a key challenge in this domain. By understanding and leveraging the properties of the RLHF loss, researchers and practitioners may be able to create more robust and trustworthy models that can better align with human values and preferences.
While the paper acknowledges several important limitations and caveats, it represents an important step forward in our understanding of the complex dynamics at play in RLHF. As the field of AI alignment continues to evolve, research like this will be crucial for ensuring that these powerful technologies are developed and deployed in a responsible and beneficial manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Getting More Juice Out of the SFT Data: Reward Learning from Human Demonstration Improves SFT for LLM Alignment
Jiaxiang Li, Siliang Zeng, Hoi-To Wai, Chenliang Li, Alfredo Garcia, Mingyi Hong
0
0
Aligning human preference and value is an important requirement for contemporary foundation models. State-of-the-art techniques such as Reinforcement Learning from Human Feedback (RLHF) often consist of two stages: 1) supervised fine-tuning (SFT), where the model is fine-tuned by learning from human demonstration data; 2) Preference learning, where preference data is used to learn a reward model, which is in turn used by a reinforcement learning (RL) step to fine-tune the model. Such reward model serves as a proxy to human preference, and it is critical to guide the RL step towards improving the model quality. In this work, we argue that the SFT stage significantly benefits from learning a reward model as well. Instead of using the human demonstration data directly via supervised learning, we propose to leverage an Inverse Reinforcement Learning (IRL) technique to (explicitly or implicitly) build an reward model, while learning the policy model. This approach leads to new SFT algorithms that are not only efficient to implement, but also promote the ability to distinguish between the preferred and non-preferred continuations. Moreover, we identify a connection between the proposed IRL based approach, and certain self-play approach proposed recently, and showed that self-play is a special case of modeling a reward-learning agent. Theoretically, we show that the proposed algorithms converge to the stationary solutions of the IRL problem. Empirically, we align 1B and 7B models using proposed methods and evaluate them on a reward benchmark model and the HuggingFace Open LLM Leaderboard. The proposed methods show significant performance improvement over existing SFT approaches. Our results indicate that it is beneficial to explicitly or implicitly leverage reward learning throughout the entire alignment process.
5/30/2024
Online Merging Optimizers for Boosting Rewards and Mitigating Tax in Alignment
Keming Lu, Bowen Yu, Fei Huang, Yang Fan, Runji Lin, Chang Zhou
0
0
Effectively aligning Large Language Models (LLMs) with human-centric values while preventing the degradation of abilities acquired through Pre-training and Supervised Fine-tuning (SFT) poses a central challenge in Reinforcement Learning from Human Feedback (RLHF). In this paper, we first discover that interpolating RLHF and SFT model parameters can adjust the trade-off between human preference and basic capabilities, thereby reducing the alignment tax at the cost of alignment reward. Inspired by this, we propose integrating the RL policy and SFT models at each optimization step in RLHF to continuously regulate the training direction, introducing the Online Merging Optimizer. Specifically, we merge gradients with the parameter differences between SFT and pretrained models, effectively steering the gradient towards maximizing rewards in the direction of SFT optimization. We demonstrate that our optimizer works well with different LLM families, such as Qwen and LLaMA, across various model sizes ranging from 1.8B to 8B, various RLHF algorithms like DPO and KTO, and existing model merging methods. It significantly enhances alignment reward while mitigating alignment tax, achieving higher overall performance across 14 benchmarks.
5/29/2024
Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-Constraint
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
0
0
This paper studies the alignment process of generative models with Reinforcement Learning from Human Feedback (RLHF). We first identify the primary challenges of existing popular methods like offline PPO and offline DPO as lacking in strategical exploration of the environment. Then, to understand the mathematical principle of RLHF, we consider a standard mathematical formulation, the reverse-KL regularized contextual bandit for RLHF. Despite its widespread practical application, a rigorous theoretical analysis of this formulation remains open. We investigate its behavior in three distinct settings -- offline, online, and hybrid -- and propose efficient algorithms with finite-sample theoretical guarantees. Moving towards practical applications, our framework, with a robust approximation of the information-theoretical policy improvement oracle, naturally gives rise to several novel RLHF algorithms. This includes an iterative version of the Direct Preference Optimization (DPO) algorithm for online settings, and a multi-step rejection sampling strategy for offline scenarios. Our empirical evaluations on real-world alignment experiment of large language model demonstrate that these proposed methods significantly surpass existing strong baselines, such as DPO and Rejection Sampling Optimization (RSO), showcasing the connections between solid theoretical foundations and their potent practical implementations.
5/2/2024

Direct Preference Optimization With Unobserved Preference Heterogeneity
Keertana Chidambaram, Karthik Vinay Seetharaman, Vasilis Syrgkanis
0
0
RLHF has emerged as a pivotal step in aligning language models with human objectives and values. It typically involves learning a reward model from human preference data and then using reinforcement learning to update the generative model accordingly. Conversely, Direct Preference Optimization (DPO) directly optimizes the generative model with preference data, skipping reinforcement learning. However, both RLHF and DPO assume uniform preferences, overlooking the reality of diverse human annotators. This paper presents a new method to align generative models with varied human preferences. We propose an Expectation-Maximization adaptation to DPO, generating a mixture of models based on latent preference types of the annotators. We then introduce a min-max regret ensemble learning model to produce a single generative method to minimize worst-case regret among annotator subgroups with similar latent factors. Our algorithms leverage the simplicity of DPO while accommodating diverse preferences. Experimental results validate the effectiveness of our approach in producing equitable generative policies.
5/27/2024