OVGNet: A Unified Visual-Linguistic Framework for Open-Vocabulary Robotic Grasping

0

Sign in to get full access
Overview
This paper introduces OVGNet, a unified visual-linguistic framework for open-vocabulary robotic grasping. The key idea is to leverage large language models and computer vision techniques to enable robots to grasp a wide range of objects, even those they have not been explicitly trained on. This could significantly expand the capabilities of robotic systems in real-world environments.
Plain English Explanation
OVGNet is a new system that allows robots to pick up and manipulate a wide variety of objects, including ones they haven't seen before. Typically, robots are trained on a limited set of objects and struggle to handle anything outside of that training data. OVGNet gets around this by combining powerful language models that can understand text descriptions of objects with computer vision techniques that can identify objects in images.
The system works by first having a human provide a text description of the object the robot needs to grasp. This description is then used to guide the robot's visual perception - it can search for and recognize the object based on the linguistic information, even if it hasn't seen that exact object before. This allows the robot to grasp novel objects in an "open-vocabulary" manner, rather than being limited to a predefined set.
The key innovation is bringing together state-of-the-art language and vision models in a unified framework designed for robotic manipulation tasks. This allows the robot to leverage the rich semantic understanding of language models and the object detection capabilities of computer vision to expand its grasp repertoire far beyond what was possible with previous approaches.
Technical Explanation
The core of OVGNet is a multi-modal architecture that integrates a vision model and a language model to enable open-vocabulary grasping. The vision model is responsible for detecting and localizing objects in the robot's camera feed, while the language model encodes text descriptions of the target object.
The authors leverage the Towards Open World Grasping and Reasoning about Grasping via Multimodal Large Language Model models as the backbone for their vision and language components, respectively. These pre-trained models are then fine-tuned on robotic grasping data to adapt them to the task.
The vision and language representations are fused using a series of transformer layers, allowing the system to reason about the visual and linguistic information in a unified manner. This enables the robot to identify the target object based on the text description and generate appropriate grasping actions.
The authors evaluate OVGNet on a series of challenging robotic grasping benchmarks, showing significant improvements over prior state-of-the-art approaches, especially in terms of handling novel, unseen objects. The results demonstrate the potential of this visual-linguistic framework to unlock new capabilities for robotic manipulation in complex, real-world environments.
Critical Analysis
The OVGNet framework presents a promising approach to expanding the grasping capabilities of robotic systems, but there are a few notable limitations and areas for further research:
-
The current system relies on a human-provided text description to guide the grasping process. An interesting direction would be to explore hierarchical open-vocabulary 3D scene graphs and language for more autonomous object identification and scene understanding.
-
While the experiments demonstrate strong performance on novel objects, the robustness of the system in dynamic, cluttered environments with multiple objects is not fully explored. Integrating techniques like ThinkGrasp for strategic part-based grasping could further enhance the system's capabilities.
-
The authors do not discuss potential safety and ethical considerations around deploying such a system in the real world, such as the potential for misuse or unintended consequences. Careful evaluation of these aspects would be important before practical deployment.
-
The reliance on large, pre-trained language and vision models raises questions about the unlocking of textual and visual wisdom - the extent to which the system can truly generalize beyond its training data and understand the world in a more comprehensive, open-vocabulary manner.
Overall, OVGNet represents an exciting step forward in open-vocabulary robotic grasping, but further research is needed to address the limitations and fully realize the potential of this visual-linguistic approach.
Conclusion
The OVGNet framework introduces a novel, unified approach to enabling robots to grasp a wide range of objects, even those they have not been explicitly trained on. By leveraging state-of-the-art language models and computer vision techniques, the system can leverage rich semantic information to guide its perception and manipulation capabilities.
The key innovation is the tight integration of language and vision, allowing the robot to understand text descriptions of target objects and use that knowledge to identify and grasp them. This "open-vocabulary" grasping capability has significant implications for expanding the deployment of robotic systems in complex, real-world environments.
While the current system shows promising results, there are opportunities for further research to enhance its robustness, safety, and generalization capabilities. Nonetheless, OVGNet represents an important step forward in unlocking new frontiers for robot manipulation and interaction with the physical world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
OVGNet: A Unified Visual-Linguistic Framework for Open-Vocabulary Robotic Grasping
Li Meng, Zhao Qi, Lyu Shuchang, Wang Chunlei, Ma Yujing, Cheng Guangliang, Yang Chenguang
Recognizing and grasping novel-category objects remains a crucial yet challenging problem in real-world robotic applications. Despite its significance, limited research has been conducted in this specific domain. To address this, we seamlessly propose a novel framework that integrates open-vocabulary learning into the domain of robotic grasping, empowering robots with the capability to adeptly handle novel objects. Our contributions are threefold. Firstly, we present a large-scale benchmark dataset specifically tailored for evaluating the performance of open-vocabulary grasping tasks. Secondly, we propose a unified visual-linguistic framework that serves as a guide for robots in successfully grasping both base and novel objects. Thirdly, we introduce two alignment modules designed to enhance visual-linguistic perception in the robotic grasping process. Extensive experiments validate the efficacy and utility of our approach. Notably, our framework achieves an average accuracy of 71.2% and 64.4% on base and novel categories in our new dataset, respectively.
Read more7/19/2024

0
Towards Open-World Grasping with Large Vision-Language Models
Georgios Tziafas, Hamidreza Kasaei
The ability to grasp objects in-the-wild from open-ended language instructions constitutes a fundamental challenge in robotics. An open-world grasping system should be able to combine high-level contextual with low-level physical-geometric reasoning in order to be applicable in arbitrary scenarios. Recent works exploit the web-scale knowledge inherent in large language models (LLMs) to plan and reason in robotic context, but rely on external vision and action models to ground such knowledge into the environment and parameterize actuation. This setup suffers from two major bottlenecks: a) the LLM's reasoning capacity is constrained by the quality of visual grounding, and b) LLMs do not contain low-level spatial understanding of the world, which is essential for grasping in contact-rich scenarios. In this work we demonstrate that modern vision-language models (VLMs) are capable of tackling such limitations, as they are implicitly grounded and can jointly reason about semantics and geometry. We propose OWG, an open-world grasping pipeline that combines VLMs with segmentation and grasp synthesis models to unlock grounded world understanding in three stages: open-ended referring segmentation, grounded grasp planning and grasp ranking via contact reasoning, all of which can be applied zero-shot via suitable visual prompting mechanisms. We conduct extensive evaluation in cluttered indoor scene datasets to showcase OWG's robustness in grounding from open-ended language, as well as open-world robotic grasping experiments in both simulation and hardware that demonstrate superior performance compared to previous supervised and zero-shot LLM-based methods.
Read more7/16/2024

0
HiFi-CS: Towards Open Vocabulary Visual Grounding For Robotic Grasping Using Vision-Language Models
Vineet Bhat, Prashanth Krishnamurthy, Ramesh Karri, Farshad Khorrami
Robots interacting with humans through natural language can unlock numerous applications such as Referring Grasp Synthesis (RGS). Given a text query, RGS determines a stable grasp pose to manipulate the referred object in the robot's workspace. RGS comprises two steps: visual grounding and grasp pose estimation. Recent studies leverage powerful Vision-Language Models (VLMs) for visually grounding free-flowing natural language in real-world robotic execution. However, comparisons in complex, cluttered environments with multiple instances of the same object are lacking. This paper introduces HiFi-CS, featuring hierarchical application of Featurewise Linear Modulation (FiLM) to fuse image and text embeddings, enhancing visual grounding for complex attribute rich text queries encountered in robotic grasping. Visual grounding associates an object in 2D/3D space with natural language input and is studied in two scenarios: Closed and Open Vocabulary. HiFi-CS features a lightweight decoder combined with a frozen VLM and outperforms competitive baselines in closed vocabulary settings while being 100x smaller in size. Our model can effectively guide open-set object detectors like GroundedSAM to enhance open-vocabulary performance. We validate our approach through real-world RGS experiments using a 7-DOF robotic arm, achieving 90.33% visual grounding accuracy in 15 tabletop scenes. We include our codebase in the supplementary material.
Read more9/17/2024
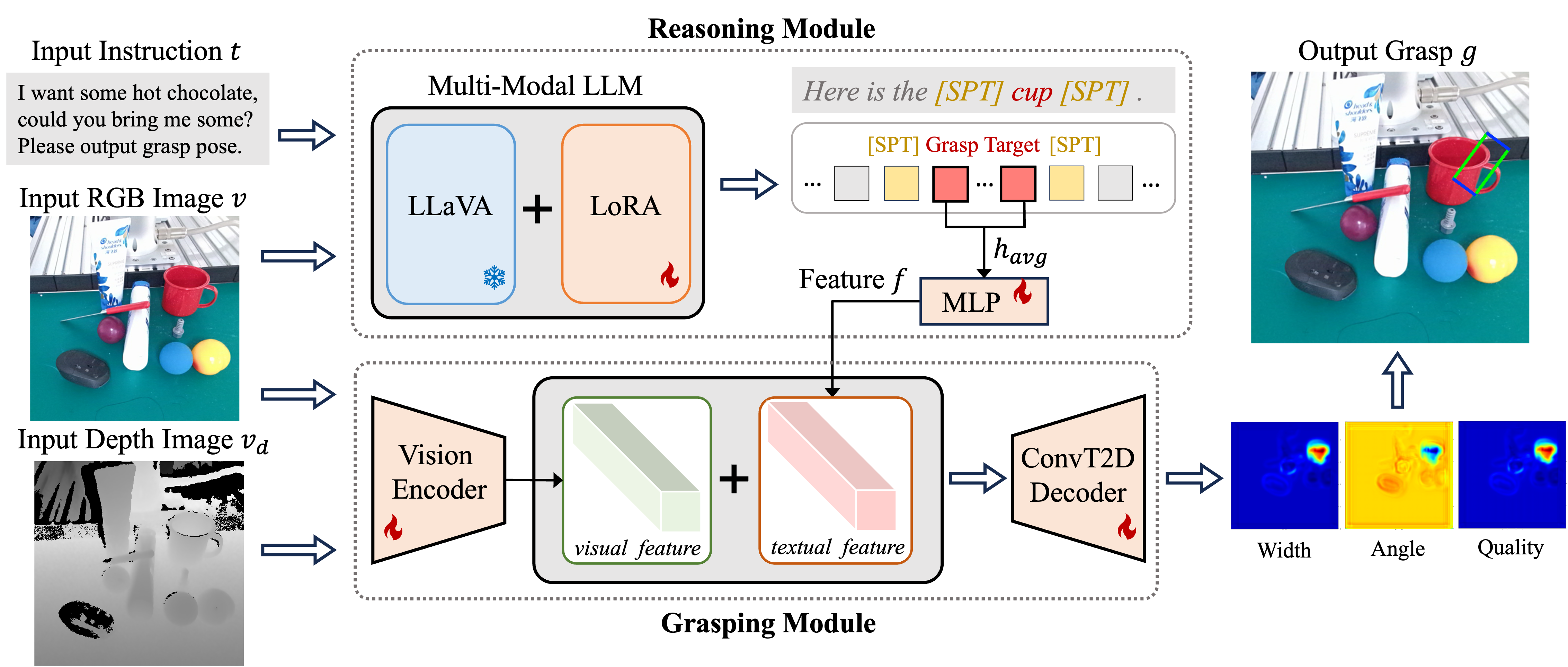
0
Reasoning Grasping via Multimodal Large Language Model
Shiyu Jin, Jinxuan Xu, Yutian Lei, Liangjun Zhang
Despite significant progress in robotic systems for operation within human-centric environments, existing models still heavily rely on explicit human commands to identify and manipulate specific objects. This limits their effectiveness in environments where understanding and acting on implicit human intentions are crucial. In this study, we introduce a novel task: reasoning grasping, where robots need to generate grasp poses based on indirect verbal instructions or intentions. To accomplish this, we propose an end-to-end reasoning grasping model that integrates a multi-modal Large Language Model (LLM) with a vision-based robotic grasping framework. In addition, we present the first reasoning grasping benchmark dataset generated from the GraspNet-1 billion, incorporating implicit instructions for object-level and part-level grasping, and this dataset will soon be available for public access. Our results show that directly integrating CLIP or LLaVA with the grasp detection model performs poorly on the challenging reasoning grasping tasks, while our proposed model demonstrates significantly enhanced performance both in the reasoning grasping benchmark and real-world experiments.
Read more4/29/2024