Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation

0
Sign in to get full access
Overview
- This paper presents a novel approach for hierarchical open-vocabulary 3D scene graphs, which can be used for language-grounded robot navigation.
- The key idea is to create a structured representation of 3D scenes that can be linked to natural language descriptions, enabling robots to understand and interact with their environments more effectively.
- The proposed method outperforms existing approaches on various benchmark tasks, demonstrating its potential for practical applications in robotics and beyond.
Plain English Explanation
This research paper introduces a new way to represent 3D scenes that robots can understand and use for navigation. The core idea is to create a hierarchical open-vocabulary 3D scene graph, which is a structured way of describing the different objects, their relationships, and the overall layout of a 3D environment.
The key advantage of this approach is that it allows robots to connect the visual information they see in the world to the natural language descriptions that humans use to communicate about those spaces. By mapping high-level semantic regions in indoor environments, the robot can understand the meaning and purpose of different areas, rather than just seeing a collection of objects.
This could be particularly useful for language-grounded robot navigation, where the robot needs to interpret instructions like "go to the kitchen" or "find the book on the table." By mapping online open vocabulary, the robot can connect the language to the 3D scene it perceives, allowing it to navigate more effectively.
The researchers demonstrate that their approach outperforms existing methods on various benchmark tasks, suggesting it could have practical applications in robotics and other domains that require understanding and interacting with complex 3D environments.
Technical Explanation
The core of the proposed method is the hierarchical open-vocabulary 3D scene graph, which represents a 3D environment as a structured collection of objects, their attributes, and the relationships between them. This allows for a more open-set 3D semantic instance maps compared to previous approaches.
The key innovations include:
-
Hierarchical Representation: The scene graph is organized into a hierarchy, with high-level semantic regions (e.g., kitchen, living room) at the top, and individual objects (e.g., table, chair) at the lower levels. This mirrors how humans typically describe 3D spaces.
-
Open Vocabulary: The system uses an open-ended vocabulary to label the objects and regions, rather than a fixed set of predefined categories. This allows it to be more expressive and adaptable to different environments.
-
Language Grounding: The system learns to associate the visual elements of the 3D scene with their corresponding natural language descriptions, enabling language-based interaction and navigation.
The researchers evaluate their approach on several benchmark tasks, including 3D scene understanding, object detection, and language-based navigation. They demonstrate significant improvements over existing methods, particularly in terms of the system's ability to generalize to new environments and understand complex language instructions.
Critical Analysis
One potential limitation of the proposed approach is that it relies on having access to high-quality 3D scene data, which can be challenging to obtain, especially for real-world environments. The researchers mention the need for indoor-outdoor 3D scene graph generation to further expand the system's capabilities.
Additionally, while the open-vocabulary approach is a strength, it also introduces some challenges in terms of maintaining consistency and resolving ambiguities in the language grounding. The researchers acknowledge this and suggest that further work is needed to address these issues.
Another area for potential improvement is the system's ability to handle dynamic environments and changes over time. The current approach focuses on static 3D scenes, but real-world environments are often in flux, with objects being moved or added. Extending the system to handle these types of changes could be an important area for future research.
Overall, the hierarchical open-vocabulary 3D scene graph represents a promising step forward in the field of language-grounded robot navigation and understanding. By bridging the gap between visual and linguistic representations of 3D spaces, it has the potential to enable more natural and effective interactions between humans and robots.
Conclusion
The research presented in this paper introduces a novel approach for hierarchical open-vocabulary 3D scene graphs, which can be used to enable language-grounded robot navigation. By creating a structured representation of 3D environments that can be linked to natural language descriptions, the proposed method allows robots to better understand and interact with their surroundings.
The key innovations, including the hierarchical organization, open vocabulary, and language grounding, have been shown to outperform existing methods on various benchmark tasks. While there are still some limitations and areas for further research, this work represents an important step forward in bridging the gap between visual and linguistic representations of 3D spaces, with promising implications for practical applications in robotics and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hierarchical Open-Vocabulary 3D Scene Graphs for Language-Grounded Robot Navigation
Abdelrhman Werby, Chenguang Huang, Martin Buchner, Abhinav Valada, Wolfram Burgard
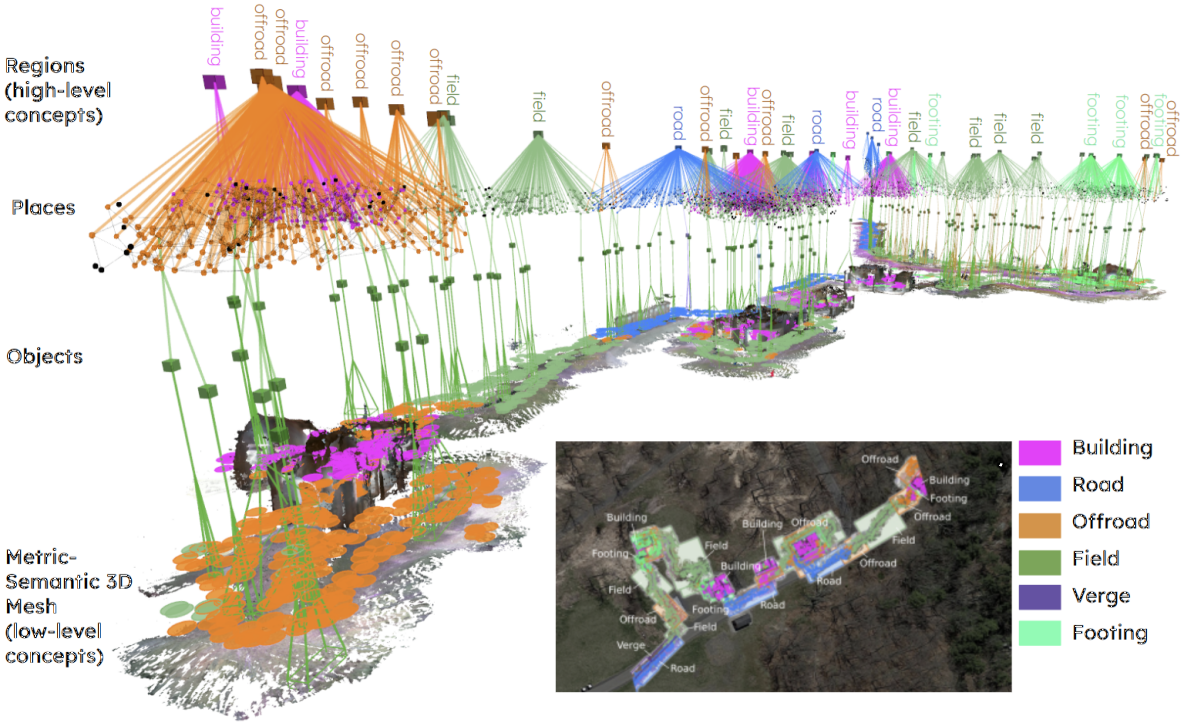
Recent open-vocabulary robot mapping methods enrich dense geometric maps with pre-trained visual-language features. While these maps allow for the prediction of point-wise saliency maps when queried for a certain language concept, large-scale environments and abstract queries beyond the object level still pose a considerable hurdle, ultimately limiting language-grounded robotic navigation. In this work, we present HOV-SG, a hierarchical open-vocabulary 3D scene graph mapping approach for language-grounded robot navigation. Leveraging open-vocabulary vision foundation models, we first obtain state-of-the-art open-vocabulary segment-level maps in 3D and subsequently construct a 3D scene graph hierarchy consisting of floor, room, and object concepts, each enriched with open-vocabulary features. Our approach is able to represent multi-story buildings and allows robotic traversal of those using a cross-floor Voronoi graph. HOV-SG is evaluated on three distinct datasets and surpasses previous baselines in open-vocabulary semantic accuracy on the object, room, and floor level while producing a 75% reduction in representation size compared to dense open-vocabulary maps. In order to prove the efficacy and generalization capabilities of HOV-SG, we showcase successful long-horizon language-conditioned robot navigation within real-world multi-storage environments. We provide code and trial video data at http://hovsg.github.io/.
Read more6/4/2024
0
Indoor and Outdoor 3D Scene Graph Generation via Language-Enabled Spatial Ontologies
Jared Strader, Nathan Hughes, William Chen, Alberto Speranzon, Luca Carlone
This paper proposes an approach to build 3D scene graphs in arbitrary indoor and outdoor environments. Such extension is challenging; the hierarchy of concepts that describe an outdoor environment is more complex than for indoors, and manually defining such hierarchy is time-consuming and does not scale. Furthermore, the lack of training data prevents the straightforward application of learning-based tools used in indoor settings. To address these challenges, we propose two novel extensions. First, we develop methods to build a spatial ontology defining concepts and relations relevant for indoor and outdoor robot operation. In particular, we use a Large Language Model (LLM) to build such an ontology, thus largely reducing the amount of manual effort required. Second, we leverage the spatial ontology for 3D scene graph construction using Logic Tensor Networks (LTN) to add logical rules, or axioms (e.g., a beach contains sand), which provide additional supervisory signals at training time thus reducing the need for labelled data, providing better predictions, and even allowing predicting concepts unseen at training time. We test our approach in a variety of datasets, including indoor, rural, and coastal environments, and show that it leads to a significant increase in the quality of the 3D scene graph generation with sparsely annotated data.
Read more4/26/2024

0
O2V-Mapping: Online Open-Vocabulary Mapping with Neural Implicit Representation
Muer Tie, Julong Wei, Zhengjun Wang, Ke Wu, Shansuai Yuan, Kaizhao Zhang, Jie Jia, Jieru Zhao, Zhongxue Gan, Wenchao Ding
Online construction of open-ended language scenes is crucial for robotic applications, where open-vocabulary interactive scene understanding is required. Recently, neural implicit representation has provided a promising direction for online interactive mapping. However, implementing open-vocabulary scene understanding capability into online neural implicit mapping still faces three challenges: lack of local scene updating ability, blurry spatial hierarchical semantic segmentation and difficulty in maintaining multi-view consistency. To this end, we proposed O2V-mapping, which utilizes voxel-based language and geometric features to create an open-vocabulary field, thus allowing for local updates during online training process. Additionally, we leverage a foundational model for image segmentation to extract language features on object-level entities, achieving clear segmentation boundaries and hierarchical semantic features. For the purpose of preserving consistency in 3D object properties across different viewpoints, we propose a spatial adaptive voxel adjustment mechanism and a multi-view weight selection method. Extensive experiments on open-vocabulary object localization and semantic segmentation demonstrate that O2V-mapping achieves online construction of language scenes while enhancing accuracy, outperforming the previous SOTA method.
Read more4/11/2024
0
From Pixels to Graphs: Open-Vocabulary Scene Graph Generation with Vision-Language Models
Rongjie Li, Songyang Zhang, Dahua Lin, Kai Chen, Xuming He
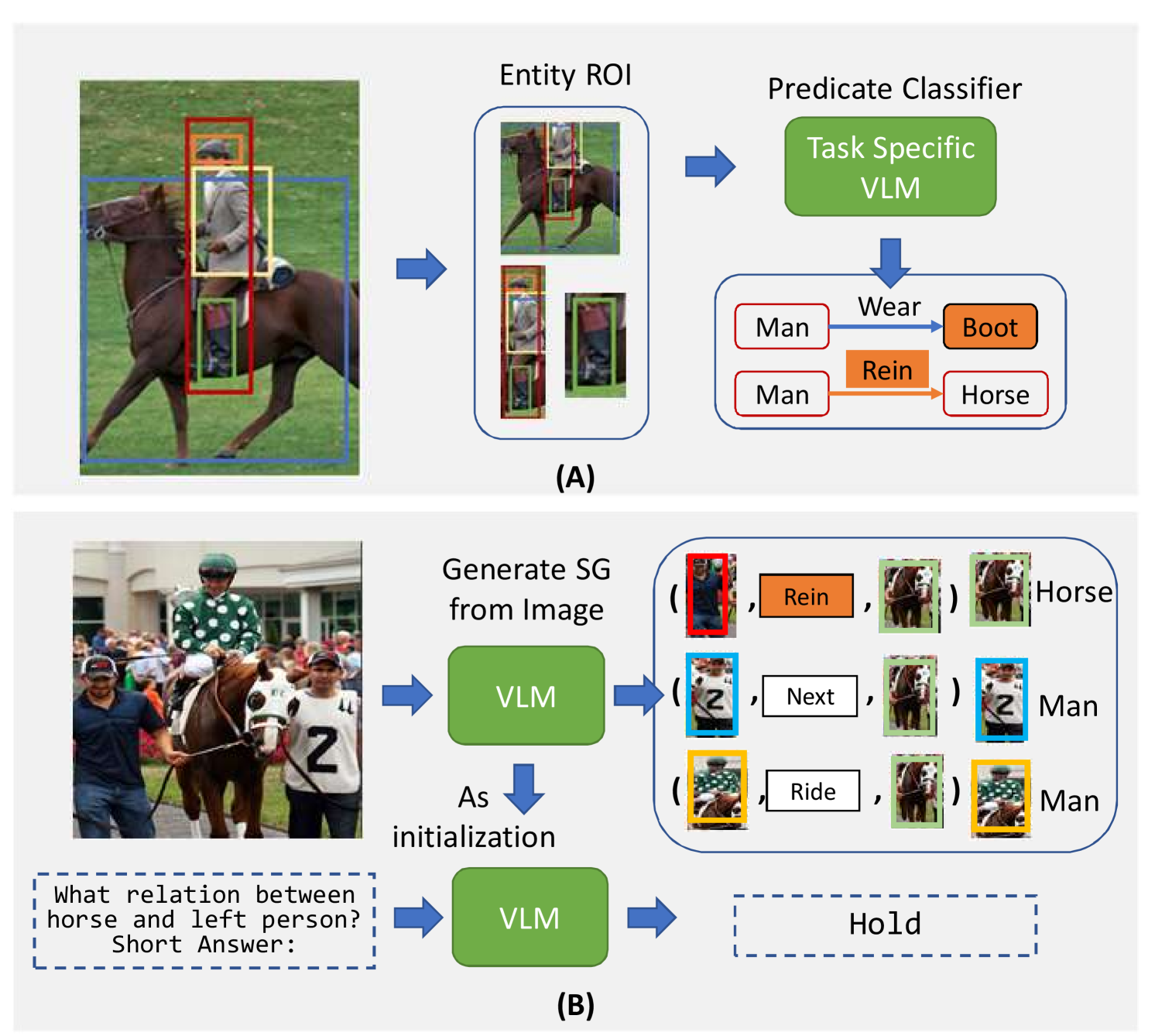
Scene graph generation (SGG) aims to parse a visual scene into an intermediate graph representation for downstream reasoning tasks. Despite recent advancements, existing methods struggle to generate scene graphs with novel visual relation concepts. To address this challenge, we introduce a new open-vocabulary SGG framework based on sequence generation. Our framework leverages vision-language pre-trained models (VLM) by incorporating an image-to-graph generation paradigm. Specifically, we generate scene graph sequences via image-to-text generation with VLM and then construct scene graphs from these sequences. By doing so, we harness the strong capabilities of VLM for open-vocabulary SGG and seamlessly integrate explicit relational modeling for enhancing the VL tasks. Experimental results demonstrate that our design not only achieves superior performance with an open vocabulary but also enhances downstream vision-language task performance through explicit relation modeling knowledge.
Read more4/9/2024