P2P: Part-to-Part Motion Cues Guide a Strong Tracking Framework for LiDAR Point Clouds

0
Sign in to get full access
Overview
- This paper presents a novel framework called "P2P" (Part-to-Part) for tracking LiDAR point clouds in 3D scenes.
- The key idea is to leverage part-to-part motion cues to guide a robust tracking system, which outperforms existing methods.
- The framework includes a novel part-based representation, a part-to-part association module, and a tracklet management module.
- Extensive experiments on public benchmarks demonstrate the superior performance of P2P compared to state-of-the-art tracking approaches.
Plain English Explanation
The paper introduces a new tracking system called "P2P" that is designed to work with 3D point cloud data from LiDAR sensors. The core innovation is the way the system analyzes the movement of different "parts" or sections of the 3D objects being tracked, rather than just looking at the overall motion of the entire object.
By focusing on how the individual parts of an object (like the wheels of a car or the limbs of a person) move relative to each other, the P2P framework is able to more accurately follow the objects as they move through the scene. This part-to-part motion cue provides important information that helps the tracking system maintain lock on the objects, even when they are partially occluded or undergo complex movements.
The P2P system consists of several key components. First, it has a novel way of representing the 3D objects as a collection of parts. Then, it uses a specialized module to associate these parts between consecutive frames, capturing their relative motion. Finally, the system has a tracklet management module that ties everything together to produce the final object tracks.
The researchers show through extensive testing on public benchmark datasets that the P2P framework outperforms existing state-of-the-art 3D object tracking methods. This suggests the power of leveraging part-level motion cues to enable robust and accurate tracking of objects in complex, real-world environments.
Technical Explanation
The P2P framework introduced in this paper tackles the problem of 3D object tracking in LiDAR point clouds. Unlike prior work that primarily focuses on the overall motion of entire objects, P2P exploits part-to-part motion cues to guide a strong tracking system.
At the core of the P2P approach is a novel part-based object representation. The 3D object is decomposed into semantically meaningful parts, and the relative motion between these parts is modeled over time. This part-level motion information is then leveraged in a part-to-part association module, which links corresponding object parts across frames to establish robust object tracks.
The P2P framework also includes a tracklet management module that handles tracklet initialization, continuation, and termination to produce the final 3D object trajectories. The researchers demonstrate the effectiveness of P2P through extensive experiments on public benchmarks like nuScenes and Waymo Open Dataset, where P2P outperforms state-of-the-art 3D object tracking methods.
Critical Analysis
The paper provides a compelling case for the value of part-level motion cues in 3D object tracking. By decomposing objects into semantically meaningful parts and modeling their relative motion, the P2P framework is able to maintain accurate tracks even in challenging scenarios with occlusions or complex object movements.
However, the paper does not address the potential computational overhead of the part-based representation and part-to-part association modules. While the improved tracking performance is clear, the runtime and memory efficiency of the P2P system compared to simpler, holistic tracking approaches could be an area for further investigation.
Additionally, the paper focuses on LiDAR-based 3D tracking and does not explore the potential of combining P2P with other sensor modalities, such as cameras. Integrating visual cues could further enhance the robustness and versatility of the tracking framework.
Overall, the P2P framework represents a significant advance in 3D object tracking by effectively leveraging part-level motion patterns. With continued research and optimization, this approach could have a substantial impact on applications such as autonomous driving, robot navigation, and video surveillance.
Conclusion
The P2P framework introduced in this paper offers a novel and effective solution for 3D object tracking in LiDAR point clouds. By modeling the relative motion of object parts, rather than just the overall object motion, P2P is able to maintain robust and accurate object tracks even in challenging scenarios.
The key innovations of the P2P system, including the part-based object representation, part-to-part association module, and tracklet management, demonstrate the power of leveraging part-level motion cues for 3D tracking. The superior performance of P2P on public benchmarks suggests that this part-to-part tracking approach could have a significant impact on real-world applications that rely on accurate 3D object tracking, such as self-driving cars and robotics.
While the paper raises some questions about computational efficiency and potential multimodal extensions, the core ideas behind P2P represent an important step forward in the field of 3D perception and scene understanding. As the demand for robust and reliable 3D tracking continues to grow, the P2P framework provides a promising direction for future research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
P2P: Part-to-Part Motion Cues Guide a Strong Tracking Framework for LiDAR Point Clouds
Jiahao Nie, Fei Xie, Sifan Zhou, Xueyi Zhou, Dong-Kyu Chae, Zhiwei He
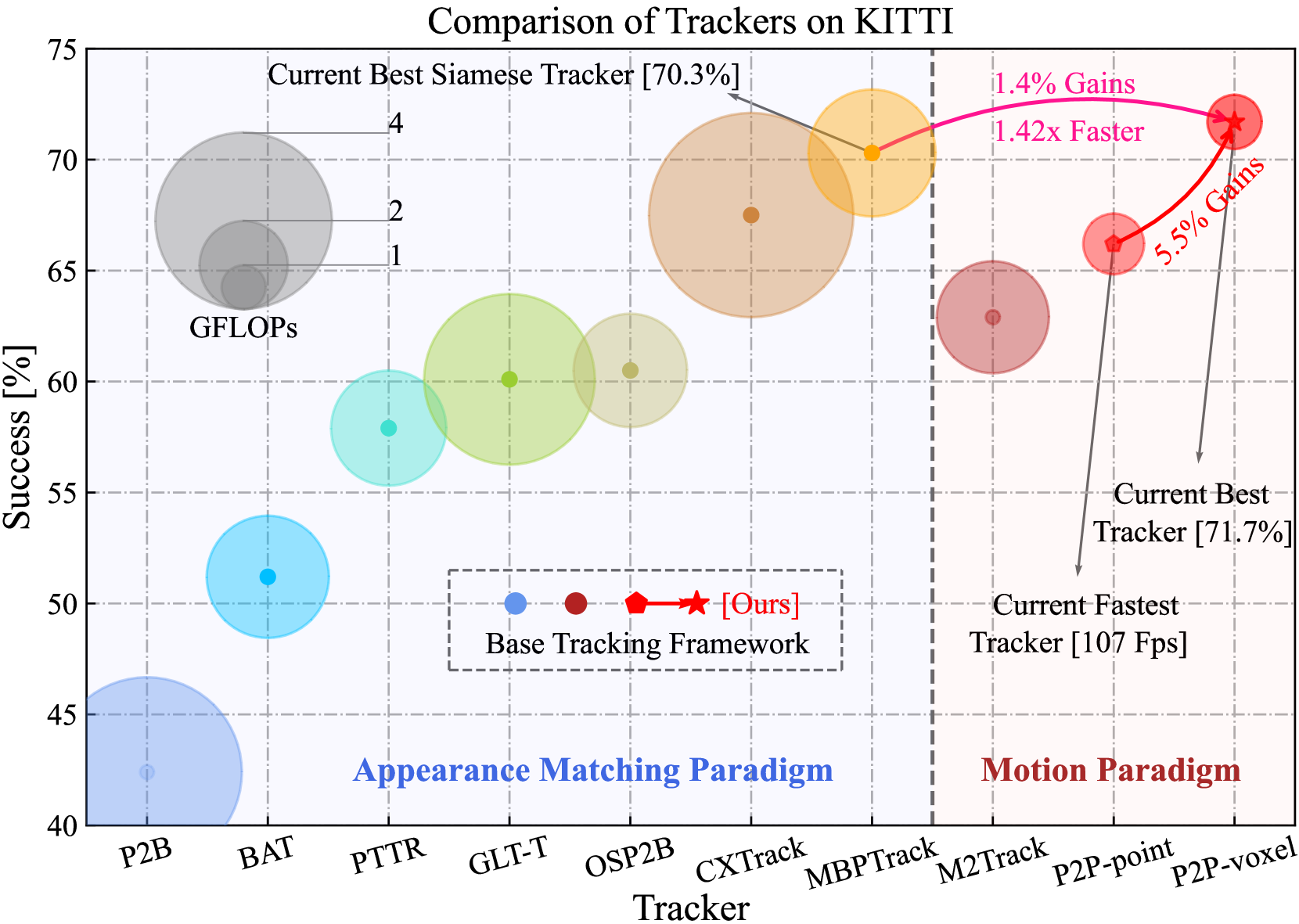
3D single object tracking (SOT) methods based on appearance matching has long suffered from insufficient appearance information incurred by incomplete, textureless and semantically deficient LiDAR point clouds. While motion paradigm exploits motion cues instead of appearance matching for tracking, it incurs complex multi-stage processing and segmentation module. In this paper, we first provide in-depth explorations on motion paradigm, which proves that (textbf{i}) it is feasible to directly infer target relative motion from point clouds across consecutive frames; (textbf{ii}) fine-grained information comparison between consecutive point clouds facilitates target motion modeling. We thereby propose to perform part-to-part motion modeling for consecutive point clouds and introduce a novel tracking framework, termed textbf{P2P}. The novel framework fuses each corresponding part information between consecutive point clouds, effectively exploring detailed information changes and thus modeling accurate target-related motion cues. Following this framework, we present P2P-point and P2P-voxel models, incorporating implicit and explicit part-to-part motion modeling by point- and voxel-based representation, respectively. Without bells and whistles, P2P-voxel sets a new state-of-the-art performance ($sim$textbf{89%}, textbf{72%} and textbf{63%} precision on KITTI, NuScenes and Waymo Open Dataset, respectively). Moreover, under the same point-based representation, P2P-point outperforms the previous motion tracker M$^2$Track by textbf{3.3%} and textbf{6.7%} on the KITTI and NuScenes, while running at a considerably high speed of textbf{107 Fps} on a single RTX3090 GPU. The source code and pre-trained models are available at url{https://github.com/haooozi/P2P}.
Read more7/10/2024

0
Towards Practical Human Motion Prediction with LiDAR Point Clouds
Xiao Han, Yiming Ren, Yichen Yao, Yujing Sun, Yuexin Ma
Human motion prediction is crucial for human-centric multimedia understanding and interacting. Current methods typically rely on ground truth human poses as observed input, which is not practical for real-world scenarios where only raw visual sensor data is available. To implement these methods in practice, a pre-phrase of pose estimation is essential. However, such two-stage approaches often lead to performance degradation due to the accumulation of errors. Moreover, reducing raw visual data to sparse keypoint representations significantly diminishes the density of information, resulting in the loss of fine-grained features. In this paper, we propose textit{LiDAR-HMP}, the first single-LiDAR-based 3D human motion prediction approach, which receives the raw LiDAR point cloud as input and forecasts future 3D human poses directly. Building upon our novel structure-aware body feature descriptor, LiDAR-HMP adaptively maps the observed motion manifold to future poses and effectively models the spatial-temporal correlations of human motions for further refinement of prediction results. Extensive experiments show that our method achieves state-of-the-art performance on two public benchmarks and demonstrates remarkable robustness and efficacy in real-world deployments.
Read more8/16/2024
0
PillarTrack: Redesigning Pillar-based Transformer Network for Single Object Tracking on Point Clouds
Weisheng Xu, Sifan Zhou, Zhihang Yuan
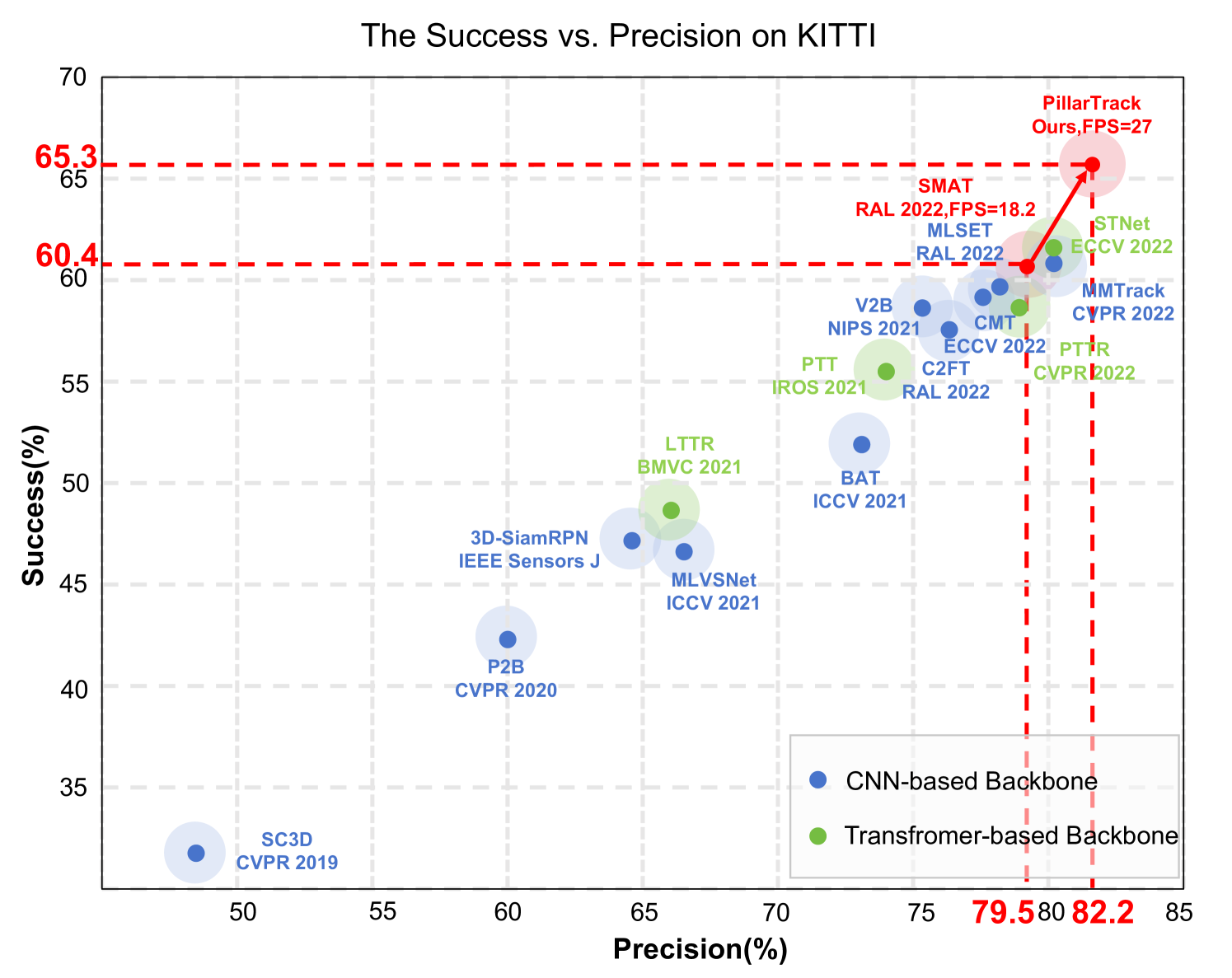
LiDAR-based 3D single object tracking (3D SOT) is a critical issue in robotics and autonomous driving. It aims to obtain accurate 3D BBox from the search area based on similarity or motion. However, existing 3D SOT methods usually follow the point-based pipeline, where the sampling operation inevitably leads to redundant or lost information, resulting in unexpected performance. To address these issues, we propose PillarTrack, a pillar-based 3D single object tracking framework. Firstly, we transform sparse point clouds into dense pillars to preserve the local and global geometrics. Secondly, we introduce a Pyramid-type Encoding Pillar Feature Encoder (PE-PFE) design to help the feature representation of each pillar. Thirdly, we present an efficient Transformer-based backbone from the perspective of modality differences. Finally, we construct our PillarTrack tracker based above designs. Extensive experiments on the KITTI and nuScenes dataset demonstrate the superiority of our proposed method. Notably, our method achieves state-of-the-art performance on the KITTI and nuScenes dataset and enables real-time tracking speed. We hope our work could encourage the community to rethink existing 3D SOT tracker designs.We will open source our code to the research community in https://github.com/StiphyJay/PillarTrack.
Read more4/12/2024
0
EasyTrack: Efficient and Compact One-stream 3D Point Clouds Tracker
Baojie Fan, Wuyang Zhou, Kai Wang, Shijun Zhou, Fengyu Xu, Jiandong Tian
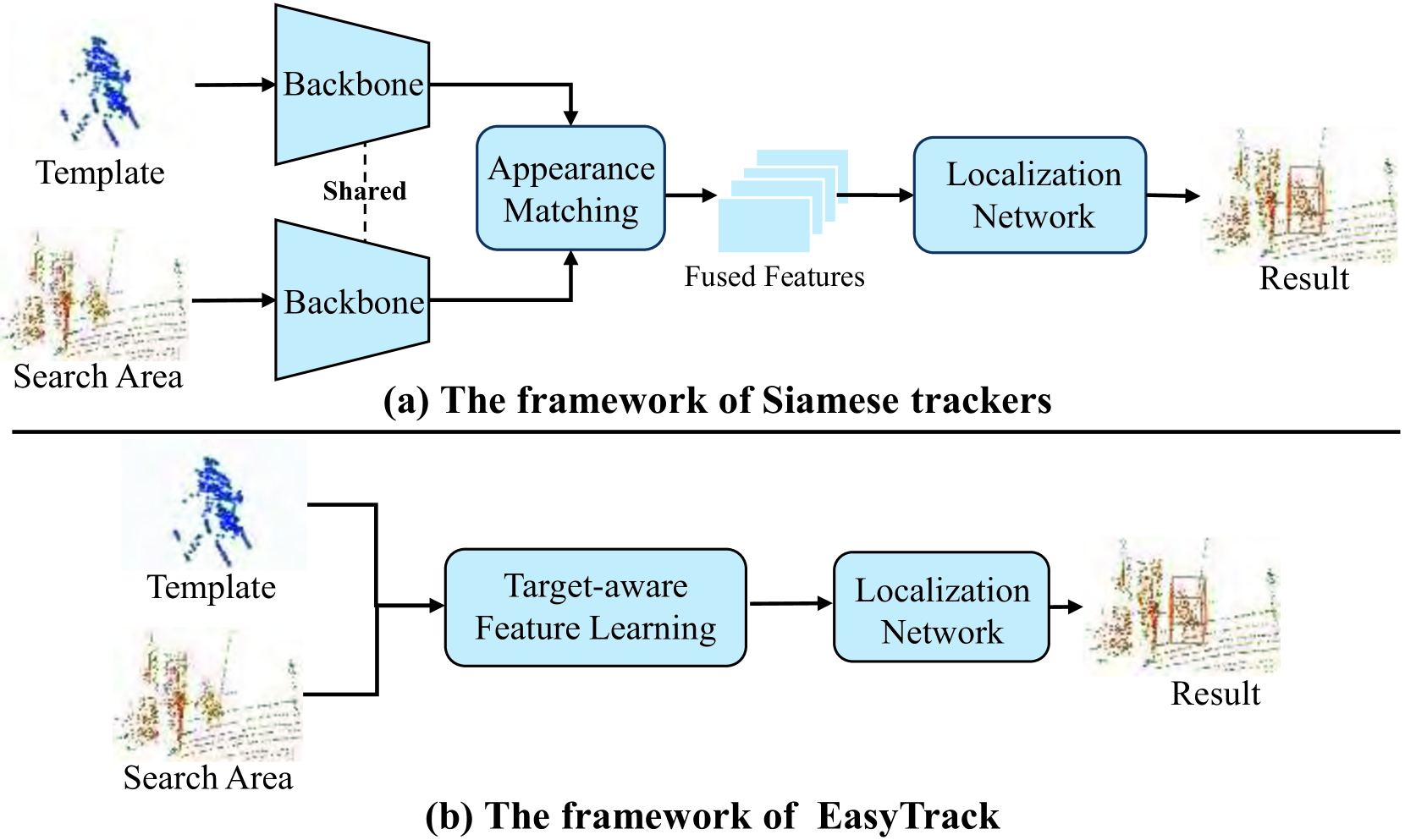
Most of 3D single object trackers (SOT) in point clouds follow the two-stream multi-stage 3D Siamese or motion tracking paradigms, which process the template and search area point clouds with two parallel branches, built on supervised point cloud backbones. In this work, beyond typical 3D Siamese or motion tracking, we propose a neat and compact one-stream transformer 3D SOT paradigm from the novel perspective, termed as textbf{EasyTrack}, which consists of three special designs: 1) A 3D point clouds tracking feature pre-training module is developed to exploit the masked autoencoding for learning 3D point clouds tracking representations. 2) A unified 3D tracking feature learning and fusion network is proposed to simultaneously learns target-aware 3D features, and extensively captures mutual correlation through the flexible self-attention mechanism. 3) A target location network in the dense bird's eye view (BEV) feature space is constructed for target classification and regression. Moreover, we develop an enhanced version named EasyTrack++, which designs the center points interaction (CPI) strategy to reduce the ambiguous targets caused by the noise point cloud background information. The proposed EasyTrack and EasyTrack++ set a new state-of-the-art performance ($textbf{18%}$, $textbf{40%}$ and $textbf{3%}$ success gains) in KITTI, NuScenes, and Waymo while runing at textbf{52.6fps} with few parameters (textbf{1.3M}). The code will be available at https://github.com/KnightApple427/Easytrack.
Read more4/15/2024