CoFiI2P: Coarse-to-Fine Correspondences for Image-to-Point Cloud Registration

0
🧪
Sign in to get full access
Overview
- Image-to-point cloud (I2P) registration is a crucial task for robots and autonomous vehicles to achieve cross-modality data fusion and localization.
- Existing I2P registration methods often converge to local optima without high-level guidance from global constraints.
- This paper introduces CoFiI2P, a novel I2P registration network that extracts correspondences in a coarse-to-fine manner to achieve the globally optimal solution.
Plain English Explanation
The paper presents a new method called CoFiI2P for aligning image data and 3D point cloud data. This is an important problem for robots and self-driving cars, as they need to be able to combine information from different sensor types to understand their surroundings and localize themselves.
Existing methods for matching image and point cloud data can easily get stuck in local optimal solutions, without considering the bigger picture. To address this, CoFiI2P uses a two-stage approach. First, it finds coarse correspondences between large regions in the image and point cloud by capturing both the similarities and differences between them. Then, it refines these correspondences to establish detailed point-level matches.
This hierarchical matching process allows CoFiI2P to find the globally optimal alignment between the image and point cloud, rather than just a local optimum. The paper demonstrates that this approach significantly outperforms the current state-of-the-art methods on a benchmark dataset.
Technical Explanation
The CoFiI2P network first processes the image and point cloud data through a Siamese encoder-decoder network to extract hierarchical features. It then employs a coarse-to-fine matching module to establish robust correspondences.
In the coarse matching phase, a novel I2P transformer module is used to capture both homogeneous and heterogeneous global information from the image and point cloud. This enables the estimation of coarse "super-point/super-pixel" matching pairs with discriminative descriptors.
In the fine matching module, detailed point/pixel pairs are established with the guidance of the coarse super-point/super-pixel correspondences. Finally, the transform matrix aligning the image and point cloud is estimated using the EPnP-RANSAC algorithm.
Critical Analysis
The paper provides a comprehensive evaluation of CoFiI2P on the KITTI dataset, demonstrating significant improvements over the current state-of-the-art methods. However, the approach is tailored to the specific task of I2P registration and may not generalize as well to other cross-modality registration problems, such as text-to-point cloud alignment.
Additionally, the paper does not address the computational complexity of the proposed method, which could be a concern for real-time applications on resource-constrained platforms. Further research may be needed to optimize the efficiency of the CoFiI2P network.
Conclusion
The CoFiI2P method represents a significant advancement in image-to-point cloud registration by leveraging a coarse-to-fine approach to achieve globally optimal alignment. This work has important implications for robots and autonomous vehicles, as it enables more robust cross-modality data fusion and localization. The promising results suggest that the coarse-to-fine registration strategy could be a valuable direction for future research in multimodal data integration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧪
0
CoFiI2P: Coarse-to-Fine Correspondences for Image-to-Point Cloud Registration
Shuhao Kang, Youqi Liao, Jianping Li, Fuxun Liang, Yuhao Li, Xianghong Zou, Fangning Li, Xieyuanli Chen, Zhen Dong, Bisheng Yang
Image-to-point cloud (I2P) registration is a fundamental task for robots and autonomous vehicles to achieve cross-modality data fusion and localization. Current I2P registration methods primarily focus on estimating correspondences at the point or pixel level, often neglecting global alignment. As a result, I2P matching can easily converge to a local optimum if it lacks high-level guidance from global constraints. To improve the success rate and general robustness, this paper introduces CoFiI2P, a novel I2P registration network that extracts correspondences in a coarse-to-fine manner. First, the image and point cloud data are processed through a two-stream encoder-decoder network for hierarchical feature extraction. Second, a coarse-to-fine matching module is designed to leverage these features and establish robust feature correspondences. Specifically, In the coarse matching phase, a novel I2P transformer module is employed to capture both homogeneous and heterogeneous global information from the image and point cloud data. This enables the estimation of coarse super-point/super-pixel matching pairs with discriminative descriptors. In the fine matching module, point/pixel pairs are established with the guidance of super-point/super-pixel correspondences. Finally, based on matching pairs, the transform matrix is estimated with the EPnP-RANSAC algorithm. Experiments conducted on the KITTI Odometry dataset demonstrate that CoFiI2P achieves impressive results, with a relative rotation error (RRE) of 1.14 degrees and a relative translation error (RTE) of 0.29 meters, while maintaining real-time speed.Additional experiments on the Nuscenes datasets confirm our method's generalizability. The project page is available at url{https://whu-usi3dv.github.io/CoFiI2P}.
Read more9/14/2024

0
MaFreeI2P: A Matching-Free Image-to-Point Cloud Registration Paradigm with Active Camera Pose Retrieval
Gongxin Yao, Xinyang Li, Yixin Xuan, Yu Pan
Image-to-point cloud registration seeks to estimate their relative camera pose, which remains an open question due to the data modality gaps. The recent matching-based methods tend to tackle this by building 2D-3D correspondences. In this paper, we reveal the information loss inherent in these methods and propose a matching-free paradigm, named MaFreeI2P. Our key insight is to actively retrieve the camera pose in SE(3) space by contrasting the geometric features between the point cloud and the query image. To achieve this, we first sample a set of candidate camera poses and construct their cost volume using the cross-modal features. Superior to matching, cost volume can preserve more information and its feature similarity implicitly reflects the confidence level of the sampled poses. Afterwards, we employ a convolutional network to adaptively formulate a similarity assessment function, where the input cost volume is further improved by filtering and pose-based weighting. Finally, we update the camera pose based on the similarity scores, and adopt a heuristic strategy to iteratively shrink the pose sampling space for convergence. Our MaFreeI2P achieves a very competitive registration accuracy and recall on the KITTI-Odometry and Apollo-DaoxiangLake datasets.
Read more8/6/2024
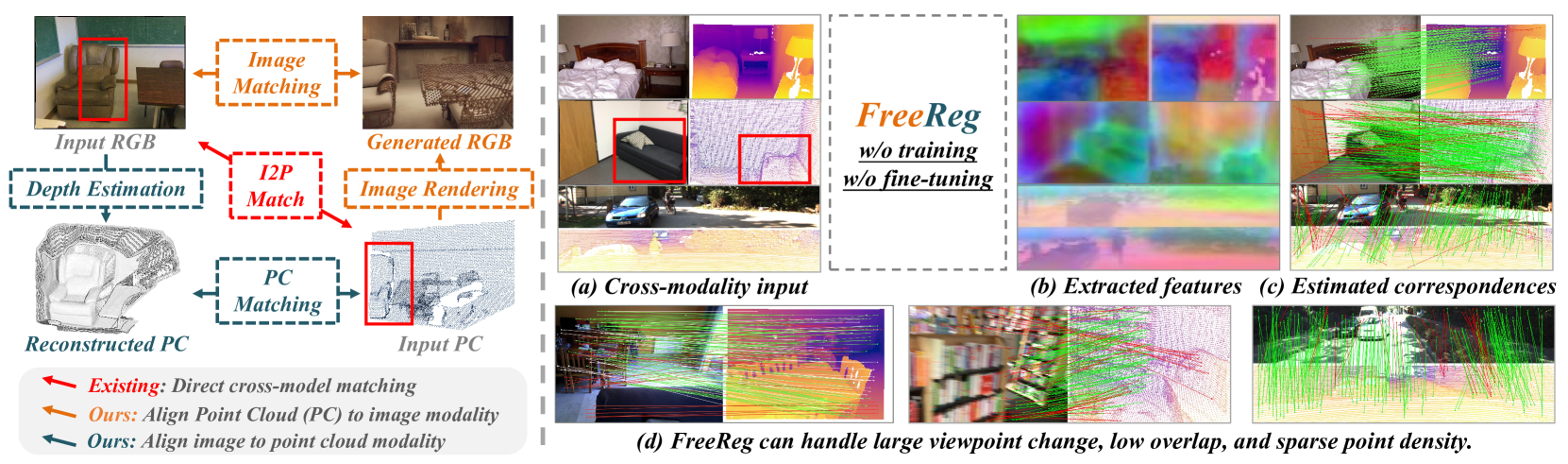
0
FreeReg: Image-to-Point Cloud Registration Leveraging Pretrained Diffusion Models and Monocular Depth Estimators
Haiping Wang, Yuan Liu, Bing Wang, Yujing Sun, Zhen Dong, Wenping Wang, Bisheng Yang
Matching cross-modality features between images and point clouds is a fundamental problem for image-to-point cloud registration. However, due to the modality difference between images and points, it is difficult to learn robust and discriminative cross-modality features by existing metric learning methods for feature matching. Instead of applying metric learning on cross-modality data, we propose to unify the modality between images and point clouds by pretrained large-scale models first, and then establish robust correspondence within the same modality. We show that the intermediate features, called diffusion features, extracted by depth-to-image diffusion models are semantically consistent between images and point clouds, which enables the building of coarse but robust cross-modality correspondences. We further extract geometric features on depth maps produced by the monocular depth estimator. By matching such geometric features, we significantly improve the accuracy of the coarse correspondences produced by diffusion features. Extensive experiments demonstrate that without any task-specific training, direct utilization of both features produces accurate image-to-point cloud registration. On three public indoor and outdoor benchmarks, the proposed method averagely achieves a 20.6 percent improvement in Inlier Ratio, a three-fold higher Inlier Number, and a 48.6 percent improvement in Registration Recall than existing state-of-the-arts.
Read more4/16/2024
⚙️
0
Learning Instance-Aware Correspondences for Robust Multi-Instance Point Cloud Registration in Cluttered Scenes
Zhiyuan Yu, Zheng Qin, Lintao Zheng, Kai Xu
Multi-instance point cloud registration estimates the poses of multiple instances of a model point cloud in a scene point cloud. Extracting accurate point correspondence is to the center of the problem. Existing approaches usually treat the scene point cloud as a whole, overlooking the separation of instances. Therefore, point features could be easily polluted by other points from the background or different instances, leading to inaccurate correspondences oblivious to separate instances, especially in cluttered scenes. In this work, we propose MIRETR, Multi-Instance REgistration TRansformer, a coarse-to-fine approach to the extraction of instance-aware correspondences. At the coarse level, it jointly learns instance-aware superpoint features and predicts per-instance masks. With instance masks, the influence from outside of the instance being concerned is minimized, such that highly reliable superpoint correspondences can be extracted. The superpoint correspondences are then extended to instance candidates at the fine level according to the instance masks. At last, an efficient candidate selection and refinement algorithm is devised to obtain the final registrations. Extensive experiments on three public benchmarks demonstrate the efficacy of our approach. In particular, MIRETR outperforms the state of the arts by 16.6 points on F1 score on the challenging ROBI benchmark. Code and models are available at https://github.com/zhiyuanYU134/MIRETR.
Read more4/9/2024