Pan-cancer gene set discovery via scRNA-seq for optimal deep learning based downstream tasks

0
🤿
Sign in to get full access
Overview
- This study investigates the use of machine learning on RNA sequencing (RNA-seq) data to improve cancer research.
- RNA-seq data is highly complex and poses challenges in pan-cancer studies (studies across multiple cancer types).
- The researchers hypothesize that gene sets derived from single-cell RNA sequencing (scRNA-seq) data will outperform those selected using bulk RNA-seq in downstream cancer analysis tasks.
Plain English Explanation
The researchers wanted to see if using gene sets from single-cell RNA sequencing data could lead to better results in various cancer analysis tasks, compared to using gene sets from traditional bulk RNA sequencing data.
RNA sequencing data is very complex, with many genes and interactions. This complexity makes it challenging to use this data effectively across different cancer types in large-scale studies. The researchers thought that by focusing on gene sets derived from single-cell data, which provides more detailed information about individual cells, they might be able to find gene sets that perform better in tasks like predicting tumor mutation burden, classifying microsatellite instability, and identifying cancer subtypes and grades.
Technical Explanation
The researchers analyzed scRNA-seq data from 181 tumor biopsies across 13 cancer types. They used an advanced technique called high-dimensional weighted gene co-expression network analysis (hdWGCNA) to identify relevant gene sets from the scRNA-seq data. These gene sets were further refined using XGBoost for feature selection.
The researchers then applied these gene sets to various downstream cancer analysis tasks using TCGA pan-cancer RNA-seq data. They compared the performance of the scRNA-seq-derived gene sets to six reference gene sets and oncogenes from OncoKB, using deep learning models such as multilayer perceptrons (MLPs) and graph neural networks (GNNs).
The results showed that the XGBoost-refined hdWGCNA gene set outperformed the other gene sets in most tasks, including tumor mutation burden assessment, microsatellite instability classification, mutation prediction, cancer subtyping, and grading. Specific genes like DPM1, BAD, and FKBP4 emerged as important pan-cancer biomarkers, with DPM1 being consistently significant across the various tasks.
Critical Analysis
The researchers acknowledge that while their approach offers a promising way to improve predictive accuracy in cancer research, there are still some limitations. For example, the study is limited to 13 cancer types, and the performance of the gene sets may vary in other cancer types. Additionally, the researchers did not conduct external validation of their findings, which would be an important next step to ensure the robustness of the results.
Furthermore, the researchers do not address the potential challenges in implementing this approach in a clinical setting, such as the availability of scRNA-seq data and the computational resources required for the advanced analysis techniques used.
Conclusion
This study presents a novel approach for feature selection in cancer genomics by integrating scRNA-seq data and advanced analysis techniques. The researchers demonstrate that gene sets derived from scRNA-seq data can outperform those selected from bulk RNA-seq in various pan-cancer analysis tasks, suggesting a path towards improving predictive accuracy in cancer research. The identification of key genes like DPM1, BAD, and FKBP4 as pan-cancer biomarkers also highlights the potential of this approach to uncover important insights for cancer diagnosis and treatment.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤿
0
Pan-cancer gene set discovery via scRNA-seq for optimal deep learning based downstream tasks
Jong Hyun Kim, Jongseong Jang
The application of machine learning to transcriptomics data has led to significant advances in cancer research. However, the high dimensionality and complexity of RNA sequencing (RNA-seq) data pose significant challenges in pan-cancer studies. This study hypothesizes that gene sets derived from single-cell RNA sequencing (scRNA-seq) data will outperform those selected using bulk RNA-seq in pan-cancer downstream tasks. We analyzed scRNA-seq data from 181 tumor biopsies across 13 cancer types. High-dimensional weighted gene co-expression network analysis (hdWGCNA) was performed to identify relevant gene sets, which were further refined using XGBoost for feature selection. These gene sets were applied to downstream tasks using TCGA pan-cancer RNA-seq data and compared to six reference gene sets and oncogenes from OncoKB evaluated with deep learning models, including multilayer perceptrons (MLPs) and graph neural networks (GNNs). The XGBoost-refined hdWGCNA gene set demonstrated higher performance in most tasks, including tumor mutation burden assessment, microsatellite instability classification, mutation prediction, cancer subtyping, and grading. In particular, genes such as DPM1, BAD, and FKBP4 emerged as important pan-cancer biomarkers, with DPM1 consistently significant across tasks. This study presents a robust approach for feature selection in cancer genomics by integrating scRNA-seq data and advanced analysis techniques, offering a promising avenue for improving predictive accuracy in cancer research.
Read more8/15/2024
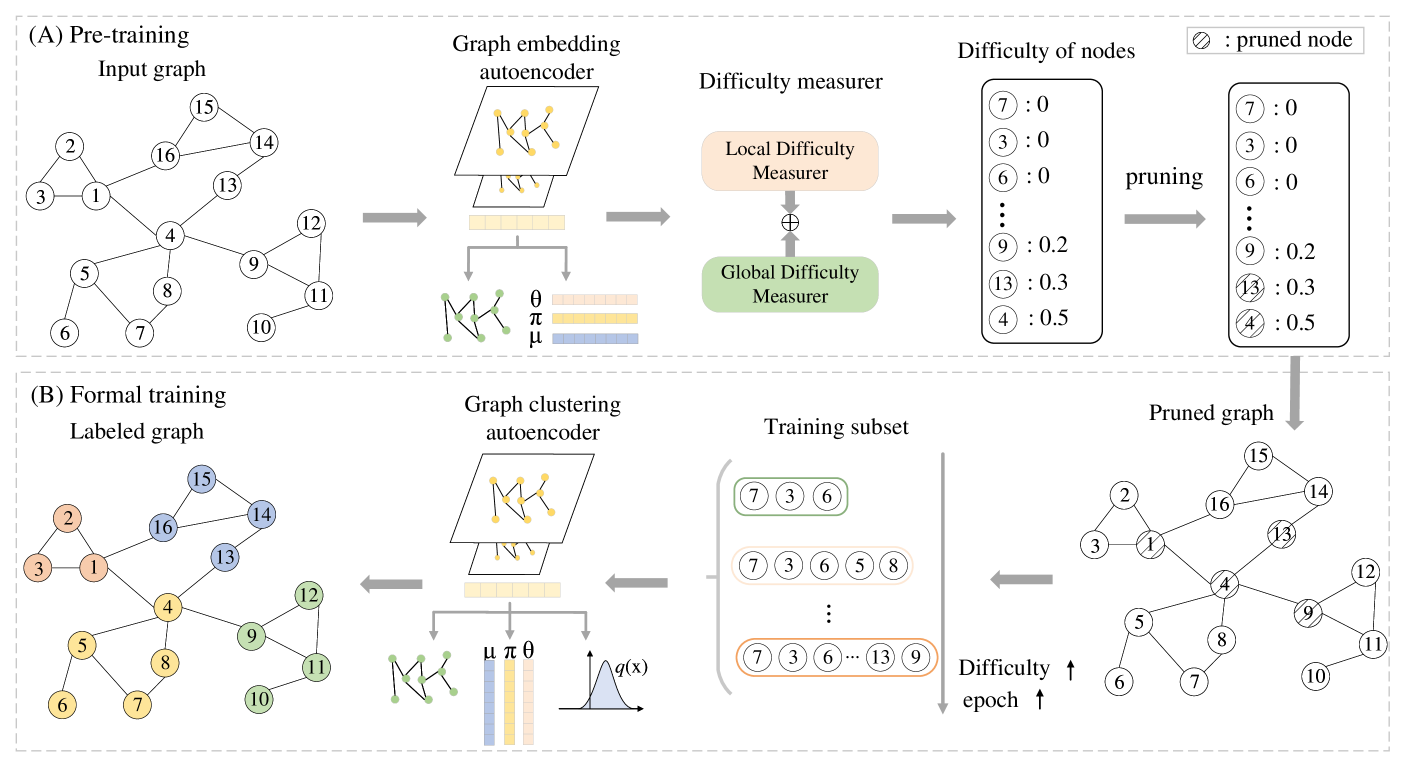
0
Single-cell Curriculum Learning-based Deep Graph Embedding Clustering
Huifa Li, Jie Fu, Xinpeng Ling, Zhiyu Sun, Kuncan Wang, Zhili Chen
The swift advancement of single-cell RNA sequencing (scRNA-seq) technologies enables the investigation of cellular-level tissue heterogeneity. Cell annotation significantly contributes to the extensive downstream analysis of scRNA-seq data. However, The analysis of scRNA-seq for biological inference presents challenges owing to its intricate and indeterminate data distribution, characterized by a substantial volume and a high frequency of dropout events. Furthermore, the quality of training samples varies greatly, and the performance of the popular scRNA-seq data clustering solution GNN could be harmed by two types of low-quality training nodes: 1) nodes on the boundary; 2) nodes that contribute little additional information to the graph. To address these problems, we propose a single-cell curriculum learning-based deep graph embedding clustering (scCLG). We first propose a Chebyshev graph convolutional autoencoder with multi-decoder (ChebAE) that combines three optimization objectives corresponding to three decoders, including topology reconstruction loss of cell graphs, zero-inflated negative binomial (ZINB) loss, and clustering loss, to learn cell-cell topology representation. Meanwhile, we employ a selective training strategy to train GNN based on the features and entropy of nodes and prune the difficult nodes based on the difficulty scores to keep the high-quality graph. Empirical results on a variety of gene expression datasets show that our model outperforms state-of-the-art methods.
Read more8/21/2024

0
Gene Regulatory Network Inference from Pre-trained Single-Cell Transcriptomics Transformer with Joint Graph Learning
Sindhura Kommu, Yizhi Wang, Yue Wang, Xuan Wang
Inferring gene regulatory networks (GRNs) from single-cell RNA sequencing (scRNA-seq) data is a complex challenge that requires capturing the intricate relationships between genes and their regulatory interactions. In this study, we tackle this challenge by leveraging the single-cell BERT-based pre-trained transformer model (scBERT), trained on extensive unlabeled scRNA-seq data, to augment structured biological knowledge from existing GRNs. We introduce a novel joint graph learning approach that combines the rich contextual representations learned by pre-trained single-cell language models with the structured knowledge encoded in GRNs using graph neural networks (GNNs). By integrating these two modalities, our approach effectively reasons over boththe gene expression level constraints provided by the scRNA-seq data and the structured biological knowledge inherent in GRNs. We evaluate our method on human cell benchmark datasets from the BEELINE study with cell type-specific ground truth networks. The results demonstrate superior performance over current state-of-the-art baselines, offering a deeper understanding of cellular regulatory mechanisms.
Read more7/26/2024
🛠️
0
Enhanced Gene Selection in Single-Cell Genomics: Pre-Filtering Synergy and Reinforced Optimization
Weiliang Zhang, Zhen Meng, Dongjie Wang, Min Wu, Kunpeng Liu, Yuanchun Zhou, Meng Xiao
Recent advancements in single-cell genomics necessitate precision in gene panel selection to interpret complex biological data effectively. Those methods aim to streamline the analysis of scRNA-seq data by focusing on the most informative genes that contribute significantly to the specific analysis task. Traditional selection methods, which often rely on expert domain knowledge, embedded machine learning models, or heuristic-based iterative optimization, are prone to biases and inefficiencies that may obscure critical genomic signals. Recognizing the limitations of traditional methods, we aim to transcend these constraints with a refined strategy. In this study, we introduce an iterative gene panel selection strategy that is applicable to clustering tasks in single-cell genomics. Our method uniquely integrates results from other gene selection algorithms, providing valuable preliminary boundaries or prior knowledge as initial guides in the search space to enhance the efficiency of our framework. Furthermore, we incorporate the stochastic nature of the exploration process in reinforcement learning (RL) and its capability for continuous optimization through reward-based feedback. This combination mitigates the biases inherent in the initial boundaries and harnesses RL's adaptability to refine and target gene panel selection dynamically. To illustrate the effectiveness of our method, we conducted detailed comparative experiments, case studies, and visualization analysis.
Read more6/12/2024