Parameter-Efficient Fine-Tuning for Continual Learning: A Neural Tangent Kernel Perspective

0
Sign in to get full access
Overview
- Parameter-Efficient Fine-Tuning for Continual Learning: A Neural Tangent Kernel Perspective
- Explores a parameter-efficient fine-tuning approach for continual learning, leveraging the neural tangent kernel (NTK) framework
- Aims to maintain model generalization while minimizing the number of updated parameters during fine-tuning
Plain English Explanation
The paper introduces a novel approach to continual learning, which is the ability for an AI model to learn new tasks without forgetting what it has learned before. The key idea is to use parameter-efficient fine-tuning, where only a small subset of a model's parameters are updated during training on a new task, rather than fine-tuning the entire model.
The researchers leverage the neural tangent kernel (NTK) framework to analyze how parameter-efficient fine-tuning affects the model's generalization capabilities. The NTK provides a way to understand the dynamics of neural network training and how changes to the model parameters impact its behavior.
The main advantage of this approach is that it can maintain the model's generalization performance on previous tasks while only updating a small number of parameters. This is important for continual learning scenarios where the model needs to adapt to new tasks without forgetting what it has learned before.
Technical Explanation
The paper proposes a parameter-efficient fine-tuning method for continual learning, where only a subset of the model's parameters are updated during fine-tuning on a new task. This is in contrast to the standard fine-tuning approach, where all parameters are updated.
The researchers analyze this approach through the lens of the neural tangent kernel (NTK). The NTK provides a way to understand the dynamics of neural network training and how changes to the model parameters impact its behavior. By leveraging the NTK, the authors show that parameter-efficient fine-tuning can maintain the model's generalization performance on previous tasks while only updating a small number of parameters.
The key insight is that the NTK can be decomposed into two components: a static component that captures the model's prior knowledge, and a dynamic component that captures the changes during fine-tuning. By carefully selecting the parameters to update, the authors demonstrate that the static component can be preserved, ensuring that the model retains its knowledge of previous tasks.
The paper includes experiments on various benchmark datasets and tasks, showing that the proposed parameter-efficient fine-tuning approach outperforms standard fine-tuning in terms of continual learning performance while using significantly fewer updated parameters.
Critical Analysis
The paper provides a solid theoretical foundation for understanding the behavior of parameter-efficient fine-tuning through the lens of the neural tangent kernel. The authors demonstrate the effectiveness of their approach on several benchmark tasks, which is a strength of the work.
However, the paper does not address potential limitations or caveats of the proposed method. For example, the performance of parameter-efficient fine-tuning may depend on the specific architecture and task, and the optimal subset of parameters to update may not be trivial to determine in practice.
Additionally, the paper does not explore the computational and memory efficiency of the method, which could be important considerations in real-world applications. Further research could investigate the trade-offs between the number of updated parameters, computational cost, and model performance.
Conclusion
This paper presents a novel approach to continual learning that leverages the neural tangent kernel to enable parameter-efficient fine-tuning. By carefully selecting the parameters to update, the method can maintain a model's generalization performance on previous tasks while only updating a small subset of its parameters.
The theoretical analysis and experimental results suggest that this approach has the potential to be a valuable tool for deploying AI models in real-world scenarios where continual learning is a key requirement. However, further research is needed to address potential limitations and explore the practical implications of the method.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Parameter-Efficient Fine-Tuning for Continual Learning: A Neural Tangent Kernel Perspective
Jingren Liu, Zhong Ji, YunLong Yu, Jiale Cao, Yanwei Pang, Jungong Han, Xuelong Li
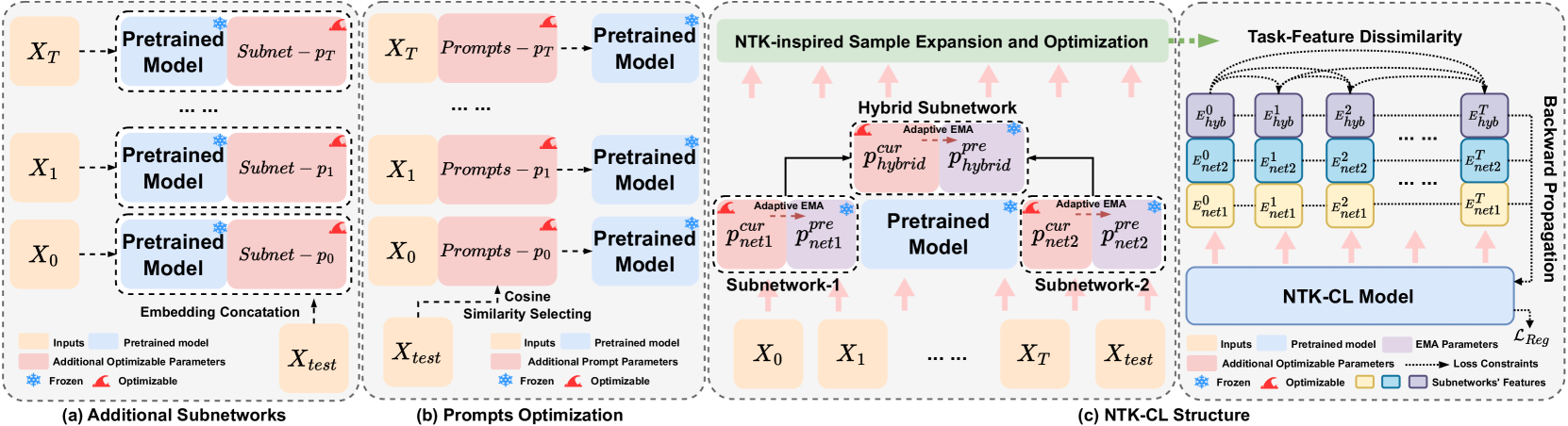
Parameter-efficient fine-tuning for continual learning (PEFT-CL) has shown promise in adapting pre-trained models to sequential tasks while mitigating catastrophic forgetting problem. However, understanding the mechanisms that dictate continual performance in this paradigm remains elusive. To tackle this complexity, we undertake a rigorous analysis of PEFT-CL dynamics to derive relevant metrics for continual scenarios using Neural Tangent Kernel (NTK) theory. With the aid of NTK as a mathematical analysis tool, we recast the challenge of test-time forgetting into the quantifiable generalization gaps during training, identifying three key factors that influence these gaps and the performance of PEFT-CL: training sample size, task-level feature orthogonality, and regularization. To address these challenges, we introduce NTK-CL, a novel framework that eliminates task-specific parameter storage while adaptively generating task-relevant features. Aligning with theoretical guidance, NTK-CL triples the feature representation of each sample, theoretically and empirically reducing the magnitude of both task-interplay and task-specific generalization gaps. Grounded in NTK analysis, our approach imposes an adaptive exponential moving average mechanism and constraints on task-level feature orthogonality, maintaining intra-task NTK forms while attenuating inter-task NTK forms. Ultimately, by fine-tuning optimizable parameters with appropriate regularization, NTK-CL achieves state-of-the-art performance on established PEFT-CL benchmarks. This work provides a theoretical foundation for understanding and improving PEFT-CL models, offering insights into the interplay between feature representation, task orthogonality, and generalization, contributing to the development of more efficient continual learning systems.
Read more7/25/2024

0
FeTT: Continual Class Incremental Learning via Feature Transformation Tuning
Sunyuan Qiang, Xuxin Lin, Yanyan Liang, Jun Wan, Du Zhang
Continual learning (CL) aims to extend deep models from static and enclosed environments to dynamic and complex scenarios, enabling systems to continuously acquire new knowledge of novel categories without forgetting previously learned knowledge. Recent CL models have gradually shifted towards the utilization of pre-trained models (PTMs) with parameter-efficient fine-tuning (PEFT) strategies. However, continual fine-tuning still presents a serious challenge of catastrophic forgetting due to the absence of previous task data. Additionally, the fine-tune-then-frozen mechanism suffers from performance limitations due to feature channels suppression and insufficient training data in the first CL task. To this end, this paper proposes feature transformation tuning (FeTT) model to non-parametrically fine-tune backbone features across all tasks, which not only operates independently of CL training data but also smooths feature channels to prevent excessive suppression. Then, the extended ensemble strategy incorporating different PTMs with FeTT model facilitates further performance improvement. We further elaborate on the discussions of the fine-tune-then-frozen paradigm and the FeTT model from the perspectives of discrepancy in class marginal distributions and feature channels. Extensive experiments on CL benchmarks validate the effectiveness of our proposed method.
Read more5/21/2024

0
Parameter Efficient Fine Tuning: A Comprehensive Analysis Across Applications
Charith Chandra Sai Balne, Sreyoshi Bhaduri, Tamoghna Roy, Vinija Jain, Aman Chadha
The rise of deep learning has marked significant progress in fields such as computer vision, natural language processing, and medical imaging, primarily through the adaptation of pre-trained models for specific tasks. Traditional fine-tuning methods, involving adjustments to all parameters, face challenges due to high computational and memory demands. This has led to the development of Parameter Efficient Fine-Tuning (PEFT) techniques, which selectively update parameters to balance computational efficiency with performance. This review examines PEFT approaches, offering a detailed comparison of various strategies highlighting applications across different domains, including text generation, medical imaging, protein modeling, and speech synthesis. By assessing the effectiveness of PEFT methods in reducing computational load, speeding up training, and lowering memory usage, this paper contributes to making deep learning more accessible and adaptable, facilitating its wider application and encouraging innovation in model optimization. Ultimately, the paper aims to contribute towards insights into PEFT's evolving landscape, guiding researchers and practitioners in overcoming the limitations of conventional fine-tuning approaches.
Read more4/23/2024

0
Parameter-Efficient Fine-Tuning for Large Models: A Comprehensive Survey
Zeyu Han, Chao Gao, Jinyang Liu, Jeff Zhang, Sai Qian Zhang
Large models represent a groundbreaking advancement in multiple application fields, enabling remarkable achievements across various tasks. However, their unprecedented scale comes with significant computational costs. These models, often consisting of billions of parameters, require vast amounts of computational resources for execution. Especially, the expansive scale and computational demands pose considerable challenges when customizing them for particular downstream tasks, particularly over the hardware platforms constrained by computational capabilities. Parameter Efficient Fine-Tuning (PEFT) provides a practical solution by efficiently adapt the large models over the various downstream tasks. In particular, PEFT refers to the process of adjusting the parameters of a pre-trained large models to adapt it to a specific task while minimizing the number of additional parameters introduced or computational resources required. This approach is particularly important when dealing with large language models with high parameter counts, as fine-tuning these models from scratch can be computationally expensive and resource-intensive, posing considerable challenges in the supporting system platform design. In this survey, we present comprehensive studies of various PEFT algorithms, examining their performance and computational overhead. Moreover, we provide an overview of applications developed using different PEFT algorithms and discuss common techniques employed to mitigate computation costs for PEFT. In addition to the algorithmic perspective, we overview various real-world system designs to investigate the implementation costs associated with different PEFT algorithms. This survey serves as an indispensable resource for researchers aiming to understand both the PEFT algorithm and its system implementation, offering detailed insights into recent advancements and practical applications.
Read more4/30/2024