Gradient Projection For Parameter-Efficient Continual Learning

0
🎲
Sign in to get full access
Overview
- Continual learning is a major challenge in machine learning, where models need to learn new tasks without forgetting previous knowledge.
- Methods based on parameter-efficient tuning (PET) have shown promising results, but still struggle with disrupting existing parameter distributions and leading to forgetting.
- The paper proposes a unified framework called Parameter Efficient Gradient Projection (PEGP) that introduces orthogonal gradient projection to different PET paradigms to effectively resist forgetting.
Plain English Explanation
Machine learning models often need to learn new tasks over time, but this can cause them to forget what they previously learned - a problem known as "catastrophic forgetting." Recent approaches based on parameter-efficient tuning (PET) have shown good results, but they still struggle with disrupting the existing parameters in a way that leads to forgetting.
The key idea in this paper is to use "gradient projection" - a mathematical technique that restricts the updates to the model's parameters in a way that preserves the knowledge from previous tasks. The authors take this concept and apply it to different PET methods, creating a unified framework called PEGP. The underlying hypothesis is that if the model's outputs for old tasks remain the same after updating, it will be able to avoid forgetting.
By incorporating this orthogonal gradient projection into PET approaches like LoRA, Prefix, and Prompt, the authors demonstrate that PEGP can effectively resist forgetting in a wide range of continual learning scenarios.
Technical Explanation
The paper proposes a unified framework called Parameter Efficient Gradient Projection (PEGP) that builds on the gradient projection methodology. Gradient projection restricts gradient updates to the orthogonal direction of the old feature space, preventing the parameter distribution from being disrupted during updates and significantly suppressing forgetting.
The authors reformulate several PET methods - Adapter, LoRA, Prefix, and Prompt - into the continual learning setting from the perspective of gradient projection. They introduce orthogonal gradient projection into these different PET paradigms and theoretically demonstrate that the orthogonal condition for the gradient can effectively resist forgetting in PET-based continual learning methods.
PEGP is the first unified method to provide an anti-forgetting mechanism with mathematical proof for these diverse tuning paradigms. The authors extensively evaluate their method using different model backbones and datasets, and the experiments show PEGP's efficiency in reducing forgetting across various incremental learning settings.
Critical Analysis
The paper makes a significant contribution by providing a unified framework that can be applied to multiple PET methods to address the challenge of catastrophic forgetting in continual learning. The theoretical analysis and mathematical demonstration of the anti-forgetting mechanism are particular strengths of the work.
However, the paper does not fully explore the limitations of the PEGP approach. For example, it would be valuable to understand how PEGP performs in scenarios with more than two or three consecutive tasks, or how it scales to large-scale models and datasets. Additionally, the authors could have discussed potential trade-offs between the overhead of the gradient projection computations and the benefits of reduced forgetting.
Further research could also investigate the interplay between PEGP and other continual learning techniques, such as adaptive methods or mixture-of-experts approaches. Combining PEGP with complementary methods may lead to even more robust and effective continual learning solutions.
Conclusion
The Parameter Efficient Gradient Projection (PEGP) framework proposed in this paper represents a significant step forward in addressing the challenge of catastrophic forgetting in continual learning. By incorporating orthogonal gradient projection into various PET methods, the authors have developed a unified approach that can effectively resist forgetting while maintaining performance on new tasks.
The theoretical analysis and experimental results demonstrate the effectiveness of PEGP, which has the potential to be a valuable tool for researchers and practitioners working on continual learning problems. While the paper does not fully explore all the limitations of the approach, it provides a strong foundation for future work in this important area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🎲
0
Gradient Projection For Parameter-Efficient Continual Learning
Jingyang Qiao, Zhizhong Zhang, Xin Tan, Yanyun Qu, Wensheng Zhang, Zhi Han, Yuan Xie
Parameter-efficient tunings (PETs) have demonstrated impressive performance and promising perspectives in training large models, while they are still confronted with a common problem: the trade-off between learning new content and protecting old knowledge, leading to zero-shot generalization collapse, and cross-modal hallucination. In this paper, we reformulate Adapter, LoRA, Prefix-tuning, and Prompt-tuning from the perspective of gradient projection, and firstly propose a unified framework called Parameter Efficient Gradient Projection (PEGP). We introduce orthogonal gradient projection into different PET paradigms and theoretically demonstrate that the orthogonal condition for the gradient can effectively resist forgetting even for large-scale models. It therefore modifies the gradient towards the direction that has less impact on the old feature space, with less extra memory space and training time. We extensively evaluate our method with different backbones, including ViT and CLIP, on diverse datasets, and experiments comprehensively demonstrate its efficiency in reducing forgetting in class, online class, domain, task, and multi-modality continual settings. The project page is available at https://dmcv-ecnu-pegp.github.io/.
Read more7/18/2024
0
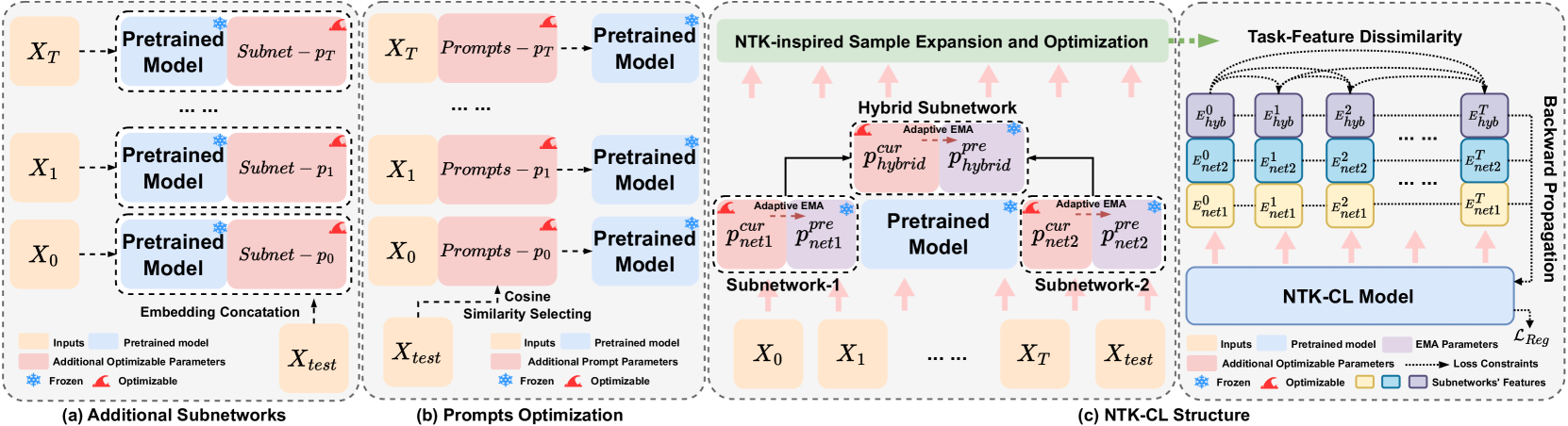
Parameter-Efficient Fine-Tuning for Continual Learning: A Neural Tangent Kernel Perspective
Jingren Liu, Zhong Ji, YunLong Yu, Jiale Cao, Yanwei Pang, Jungong Han, Xuelong Li
Parameter-efficient fine-tuning for continual learning (PEFT-CL) has shown promise in adapting pre-trained models to sequential tasks while mitigating catastrophic forgetting problem. However, understanding the mechanisms that dictate continual performance in this paradigm remains elusive. To tackle this complexity, we undertake a rigorous analysis of PEFT-CL dynamics to derive relevant metrics for continual scenarios using Neural Tangent Kernel (NTK) theory. With the aid of NTK as a mathematical analysis tool, we recast the challenge of test-time forgetting into the quantifiable generalization gaps during training, identifying three key factors that influence these gaps and the performance of PEFT-CL: training sample size, task-level feature orthogonality, and regularization. To address these challenges, we introduce NTK-CL, a novel framework that eliminates task-specific parameter storage while adaptively generating task-relevant features. Aligning with theoretical guidance, NTK-CL triples the feature representation of each sample, theoretically and empirically reducing the magnitude of both task-interplay and task-specific generalization gaps. Grounded in NTK analysis, our approach imposes an adaptive exponential moving average mechanism and constraints on task-level feature orthogonality, maintaining intra-task NTK forms while attenuating inter-task NTK forms. Ultimately, by fine-tuning optimizable parameters with appropriate regularization, NTK-CL achieves state-of-the-art performance on established PEFT-CL benchmarks. This work provides a theoretical foundation for understanding and improving PEFT-CL models, offering insights into the interplay between feature representation, task orthogonality, and generalization, contributing to the development of more efficient continual learning systems.
Read more7/25/2024
✅
0
New!Bayesian Parameter-Efficient Fine-Tuning for Overcoming Catastrophic Forgetting
Haolin Chen, Philip N. Garner
We are motivated primarily by the adaptation of text-to-speech synthesis models; however we argue that more generic parameter-efficient fine-tuning (PEFT) is an appropriate framework to do such adaptation. Nevertheless, catastrophic forgetting remains an issue with PEFT, damaging the pre-trained model's inherent capabilities. We demonstrate that existing Bayesian learning techniques can be applied to PEFT to prevent catastrophic forgetting as long as the parameter shift of the fine-tuned layers can be calculated differentiably. In a principled series of experiments on language modeling and speech synthesis tasks, we utilize established Laplace approximations, including diagonal and Kronecker-factored approaches, to regularize PEFT with the low-rank adaptation (LoRA) and compare their performance in pre-training knowledge preservation. Our results demonstrate that catastrophic forgetting can be overcome by our methods without degrading the fine-tuning performance, and using the Kronecker-factored approximation produces a better preservation of the pre-training knowledge than the diagonal ones.
Read more9/18/2024

0
HiDe-PET: Continual Learning via Hierarchical Decomposition of Parameter-Efficient Tuning
Liyuan Wang, Jingyi Xie, Xingxing Zhang, Hang Su, Jun Zhu
The deployment of pre-trained models (PTMs) has greatly advanced the field of continual learning (CL), enabling positive knowledge transfer and resilience to catastrophic forgetting. To sustain these advantages for sequentially arriving tasks, a promising direction involves keeping the pre-trained backbone frozen while employing parameter-efficient tuning (PET) techniques to instruct representation learning. Despite the popularity of Prompt-based PET for CL, its empirical design often leads to sub-optimal performance in our evaluation of different PTMs and target tasks. To this end, we propose a unified framework for CL with PTMs and PET that provides both theoretical and empirical advancements. We first perform an in-depth theoretical analysis of the CL objective in a pre-training context, decomposing it into hierarchical components namely within-task prediction, task-identity inference and task-adaptive prediction. We then present Hierarchical Decomposition PET (HiDe-PET), an innovative approach that explicitly optimizes the decomposed objective through incorporating task-specific and task-shared knowledge via mainstream PET techniques along with efficient recovery of pre-trained representations. Leveraging this framework, we delve into the distinct impacts of implementation strategy, PET technique and PET architecture, as well as adaptive knowledge accumulation amidst pronounced distribution changes. Finally, across various CL scenarios, our approach demonstrates remarkably superior performance over a broad spectrum of recent strong baselines.
Read more7/9/2024