Towards Efficient Pareto Set Approximation via Mixture of Experts Based Model Fusion
2406.09770
0
0

Abstract
Solving multi-objective optimization problems for large deep neural networks is a challenging task due to the complexity of the loss landscape and the expensive computational cost of training and evaluating models. Efficient Pareto front approximation of large models enables multi-objective optimization for various tasks such as multi-task learning and trade-off analysis. Existing algorithms for learning Pareto set, including (1) evolutionary, hypernetworks, and hypervolume-maximization methods, are computationally expensive and have restricted scalability to large models; (2) Scalarization algorithms, where a separate model is trained for each objective ray, which is inefficient for learning the entire Pareto set and fails to capture the objective trade-offs effectively. Inspired by the recent success of model merging, we propose a practical and scalable approach to Pareto set learning problem via mixture of experts (MoE) based model fusion. By ensembling the weights of specialized single-task models, the MoE module can effectively capture the trade-offs between multiple objectives and closely approximate the entire Pareto set of large neural networks. Once the routers are learned and a preference vector is set, the MoE module can be unloaded, thus no additional computational cost is introduced during inference. We conduct extensive experiments on vision and language tasks using large-scale models such as CLIP-ViT and GPT-2. The experimental results demonstrate that our method efficiently approximates the entire Pareto front of large models. Using only hundreds of trainable parameters of the MoE routers, our method even has lower memory usage compared to linear scalarization and algorithms that learn a single Pareto optimal solution, and are scalable to both the number of objectives and the size of the model.
Create account to get full access
Overview
- This paper proposes a novel method for efficiently approximating the Pareto set, which is the set of optimal solutions for multi-objective optimization problems.
- The method uses a mixture of expert models, where each expert is responsible for a different region of the Pareto set, and a gating network that determines which expert to use for a given input.
- The authors demonstrate that this approach outperforms existing methods for Pareto set approximation on several benchmark problems.
Plain English Explanation
In many real-world problems, there are multiple objectives that need to be optimized, and there is often no single solution that is the best for all objectives. Instead, there is a set of Pareto optimal solutions, where improving one objective would require sacrificing another.
The authors of this paper have developed a new way to efficiently approximate the Pareto set. Their approach uses a mixture of expert models, where each expert is responsible for a different region of the Pareto set. A gating network then determines which expert to use for a given input.
This is similar to how a team of specialists might work together to solve a complex problem, with each specialist focusing on a different aspect of the problem. By dividing the task in this way, the authors' approach can more efficiently explore the Pareto set and find good solutions.
The authors show that their method outperforms existing techniques for Pareto set approximation on several benchmark problems. This suggests that their approach could be useful for a wide range of real-world multi-objective optimization problems, such as designing products that balance multiple desirable features or merging multiple machine learning models to get the best of each.
Technical Explanation
The key idea behind the authors' approach is to use a mixture of experts model to approximate the Pareto set. Each expert is responsible for a different region of the Pareto set, and a gating network determines which expert to use for a given input.
The authors propose two variants of their method. In the first, the experts are trained independently, and the gating network is trained to select the appropriate expert for each input. In the second, the experts and the gating network are trained jointly using a geometry-aware loss function that encourages the experts to cover different regions of the Pareto set.
The authors evaluate their method on several benchmark multi-objective optimization problems, including problems from the ZDT and DTLZ test suites. They show that their approach outperforms existing methods, such as NSGA-II and MOEA/D, in terms of both the quality and diversity of the Pareto set approximations.
Critical Analysis
The authors acknowledge that their method has some limitations. For example, the performance of the method may depend on the complexity of the Pareto set and the number of experts used. Additionally, the joint training approach may be computationally more expensive than the independent training approach.
One potential issue that the authors do not address is the interpretability of the experts. In a real-world application, it may be important to understand why each expert is making a particular recommendation, which could be difficult to determine from a black-box model.
Overall, the authors' approach appears to be a promising step towards more efficient Pareto set approximation, but further research may be needed to address some of the potential limitations and make the method more robust and interpretable.
Conclusion
This paper presents a novel method for efficiently approximating the Pareto set in multi-objective optimization problems. By using a mixture of expert models, the authors are able to better explore the Pareto set and find good solutions. The authors demonstrate the effectiveness of their approach on several benchmark problems, and the method could be useful for a wide range of real-world applications where multiple objectives need to be balanced.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Provably Effective Method for Pruning Experts in Fine-tuned Sparse Mixture-of-Experts
Mohammed Nowaz Rabbani Chowdhury, Meng Wang, Kaoutar El Maghraoui, Naigang Wang, Pin-Yu Chen, Christopher Carothers
0
0
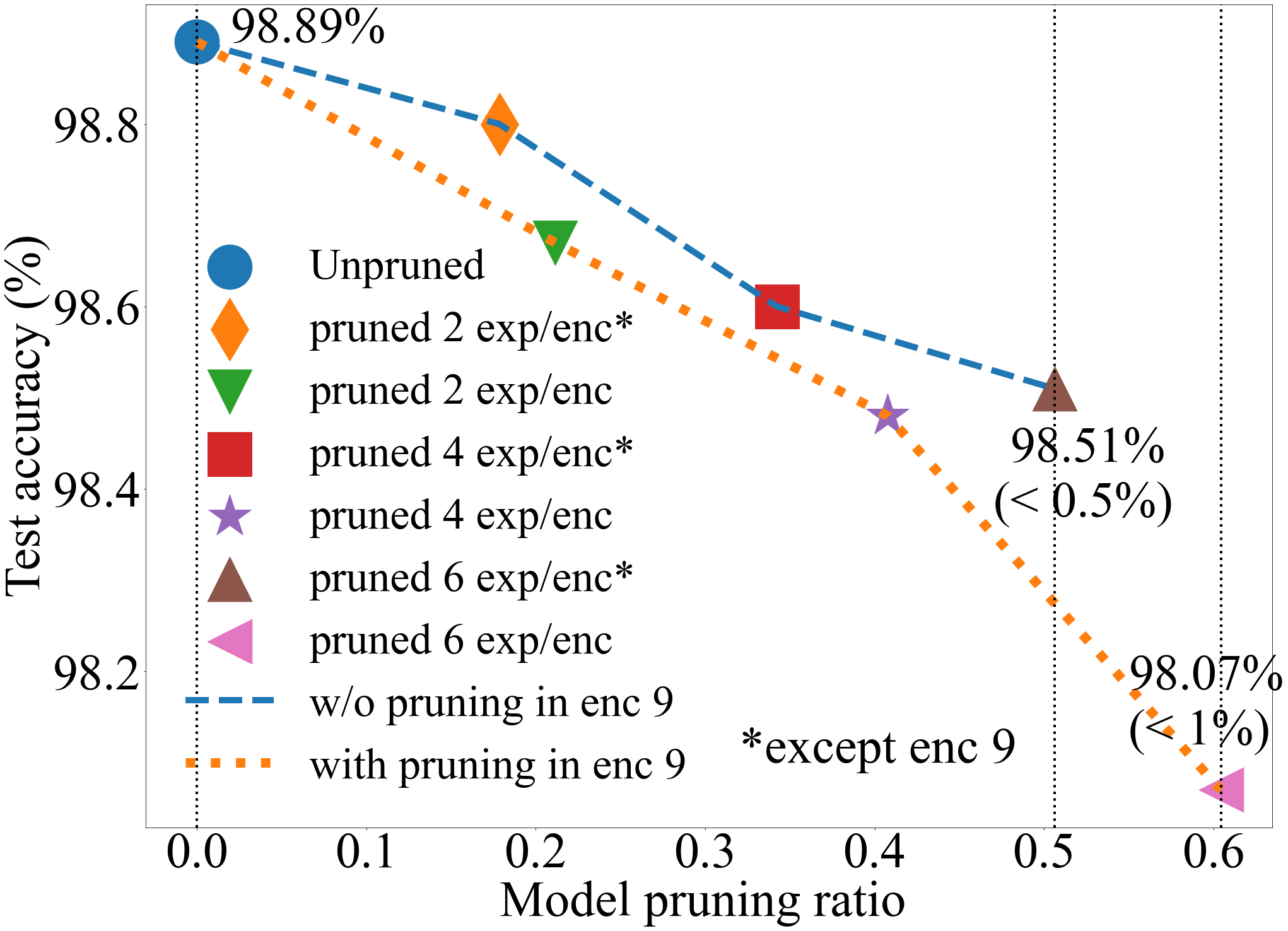
The sparsely gated mixture of experts (MoE) architecture sends different inputs to different subnetworks, i.e., experts, through trainable routers. MoE reduces the training computation significantly for large models, but its deployment can be still memory or computation expensive for some downstream tasks. Model pruning is a popular approach to reduce inference computation, but its application in MoE architecture is largely unexplored. To the best of our knowledge, this paper provides the first provably efficient technique for pruning experts in finetuned MoE models. We theoretically prove that prioritizing the pruning of the experts with a smaller change of the routers l2 norm from the pretrained model guarantees the preservation of test accuracy, while significantly reducing the model size and the computational requirements. Although our theoretical analysis is centered on binary classification tasks on simplified MoE architecture, our expert pruning method is verified on large vision MoE models such as VMoE and E3MoE finetuned on benchmark datasets such as CIFAR10, CIFAR100, and ImageNet.
5/31/2024
HyperMoE: Towards Better Mixture of Experts via Transferring Among Experts
Hao Zhao, Zihan Qiu, Huijia Wu, Zili Wang, Zhaofeng He, Jie Fu
0
0
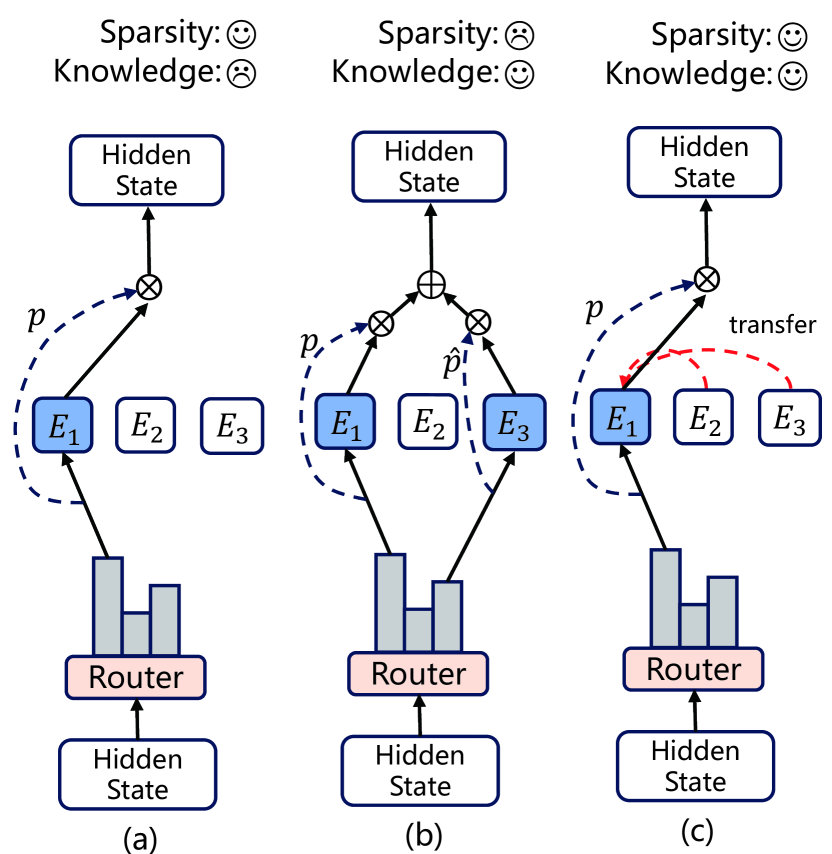
The Mixture of Experts (MoE) for language models has been proven effective in augmenting the capacity of models by dynamically routing each input token to a specific subset of experts for processing. Despite the success, most existing methods face a challenge for balance between sparsity and the availability of expert knowledge: enhancing performance through increased use of expert knowledge often results in diminishing sparsity during expert selection. To mitigate this contradiction, we propose HyperMoE, a novel MoE framework built upon Hypernetworks. This framework integrates the computational processes of MoE with the concept of knowledge transferring in multi-task learning. Specific modules generated based on the information of unselected experts serve as supplementary information, which allows the knowledge of experts not selected to be used while maintaining selection sparsity. Our comprehensive empirical evaluations across multiple datasets and backbones establish that HyperMoE significantly outperforms existing MoE methods under identical conditions concerning the number of experts.
5/22/2024
🧠
Towards Geometry-Aware Pareto Set Learning for Neural Multi-Objective Combinatorial Optimization
Yongfan Lu, Zixiang Di, Bingdong Li, Shengcai Liu, Hong Qian, Peng Yang, Ke Tang, Aimin Zhou
0
0
Multi-objective combinatorial optimization (MOCO) problems are prevalent in various real-world applications. Most existing neural MOCO methods rely on problem decomposition to transform an MOCO problem into a series of singe-objective combinatorial optimization (SOCO) problems. However, these methods often approximate partial regions of the Pareto front and spend excessive time on diversity enhancement because of ambiguous decomposition and time-consuming precise hypervolume calculation. To address these limitations, we design a Geometry-Aware Pareto set Learning algorithm named GAPL, which provides a novel geometric perspective for neural MOCO via a Pareto attention model based on hypervolume expectation maximization. In addition, we propose a hypervolume residual update strategy to enable the Pareto attention model to capture both local and non-local information of the Pareto set/front. We also design a novel inference approach to further improve quality of the solution set and speed up hypervolume calculation. Experimental results on three classic MOCO problems demonstrate that our GAPL outperforms several state-of-the-art baselines via superior decomposition and efficient diversity enhancement.
5/27/2024

Intuition-aware Mixture-of-Rank-1-Experts for Parameter Efficient Finetuning
Yijiang Liu, Rongyu Zhang, Huanrui Yang, Kurt Keutzer, Yuan Du, Li Du, Shanghang Zhang
0
0
Large Language Models (LLMs) have demonstrated significant potential in performing multiple tasks in multimedia applications, ranging from content generation to interactive entertainment, and artistic creation. However, the diversity of downstream tasks in multitask scenarios presents substantial adaptation challenges for LLMs. While traditional methods often succumb to knowledge confusion on their monolithic dense models, Mixture-of-Experts (MoE) has been emerged as a promising solution with its sparse architecture for effective task decoupling. Inspired by the principles of human cognitive neuroscience, we design a novel framework texttt{Intuition-MoR1E} that leverages the inherent semantic clustering of instances to mimic the human brain to deal with multitask, offering implicit guidance to router for optimized feature allocation. Moreover, we introduce cutting-edge Rank-1 Experts formulation designed to manage a spectrum of intuitions, demonstrating enhanced parameter efficiency and effectiveness in multitask LLM finetuning. Extensive experiments demonstrate that Intuition-MoR1E achieves superior efficiency and 2.15% overall accuracy improvement across 14 public datasets against other state-of-the-art baselines.
4/16/2024