Efficient Pareto Manifold Learning with Low-Rank Structure

0

Sign in to get full access
Overview
- Explains a method for efficiently learning the Pareto manifold in multi-objective optimization problems
- Leverages a low-rank structure to enable fast and scalable Pareto set approximation
- Demonstrates improved performance on various multi-objective benchmark tasks
Plain English Explanation
The paper describes a new approach for solving multi-objective optimization problems, which are tasks where multiple, often conflicting objectives need to be optimized simultaneously. In these scenarios, there is typically not a single optimal solution, but rather a set of Pareto optimal solutions, each representing a different tradeoff between the objectives.
The key idea of the proposed method is to leverage the low-rank structure that often exists in the Pareto manifold, the set of all Pareto optimal solutions. By exploiting this low-rank structure, the method can learn the Pareto manifold more efficiently and generate high-quality Pareto set approximations even for high-dimensional problems. This is achieved through a novel optimization algorithm that alternates between learning a low-rank representation of the Pareto manifold and updating the individual objectives.
The authors demonstrate the effectiveness of their approach on a variety of multi-objective benchmark tasks, where it outperforms existing methods in terms of the quality of the Pareto set approximation and the computational efficiency.
Technical Explanation
The paper proposes a method called Efficient Pareto Manifold Learning (EPML) for approximating the Pareto set in multi-objective optimization problems. The key insight is that the Pareto manifold often exhibits a low-rank structure, which can be leveraged to enable efficient and scalable Pareto set approximation.
The EPML algorithm alternates between two main steps:
- Pareto Manifold Learning: The algorithm learns a low-rank representation of the Pareto manifold using a novel objective function that encourages the learned representation to capture the true Pareto set.
- Objective Update: The individual objective functions are updated to improve the quality of the Pareto set approximation.
By exploiting the low-rank structure of the Pareto manifold, EPML can generate high-quality Pareto set approximations more efficiently than existing methods, particularly for high-dimensional problems. The authors evaluate EPML on a range of multi-objective benchmark tasks and demonstrate its superior performance in terms of both the quality of the Pareto set approximation and the computational efficiency.
Critical Analysis
The paper makes a valuable contribution by proposing a novel method for efficiently learning the Pareto manifold in multi-objective optimization problems. The key strength of the EPML approach is its ability to leverage the low-rank structure of the Pareto manifold, which enables it to scale well to high-dimensional problems.
However, the paper does not address some potential limitations of the proposed method. For example, the low-rank assumption may not hold for all types of multi-objective optimization problems, and the performance of EPML may degrade in such cases. Additionally, the paper does not provide a detailed analysis of the computational complexity of the algorithm, which is an important consideration for real-world applications.
Further research could explore the robustness of EPML to violations of the low-rank assumption, as well as investigate ways to improve the algorithm's scalability and computational efficiency for even larger-scale problems.
Conclusion
The Efficient Pareto Manifold Learning (EPML) method proposed in this paper represents an important step forward in the field of multi-objective optimization. By exploiting the low-rank structure of the Pareto manifold, EPML can generate high-quality Pareto set approximations more efficiently than existing approaches, particularly for high-dimensional problems.
The successful application of EPML to a range of multi-objective benchmark tasks suggests that it could have significant implications for real-world applications, such as robotics, engineering design, and resource allocation, where optimizing multiple, often conflicting objectives is a crucial challenge. Further research to address the potential limitations of the method and explore its broader applicability would be a valuable next step.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Pareto Manifold Learning with Low-Rank Structure
Weiyu Chen, James T. Kwok
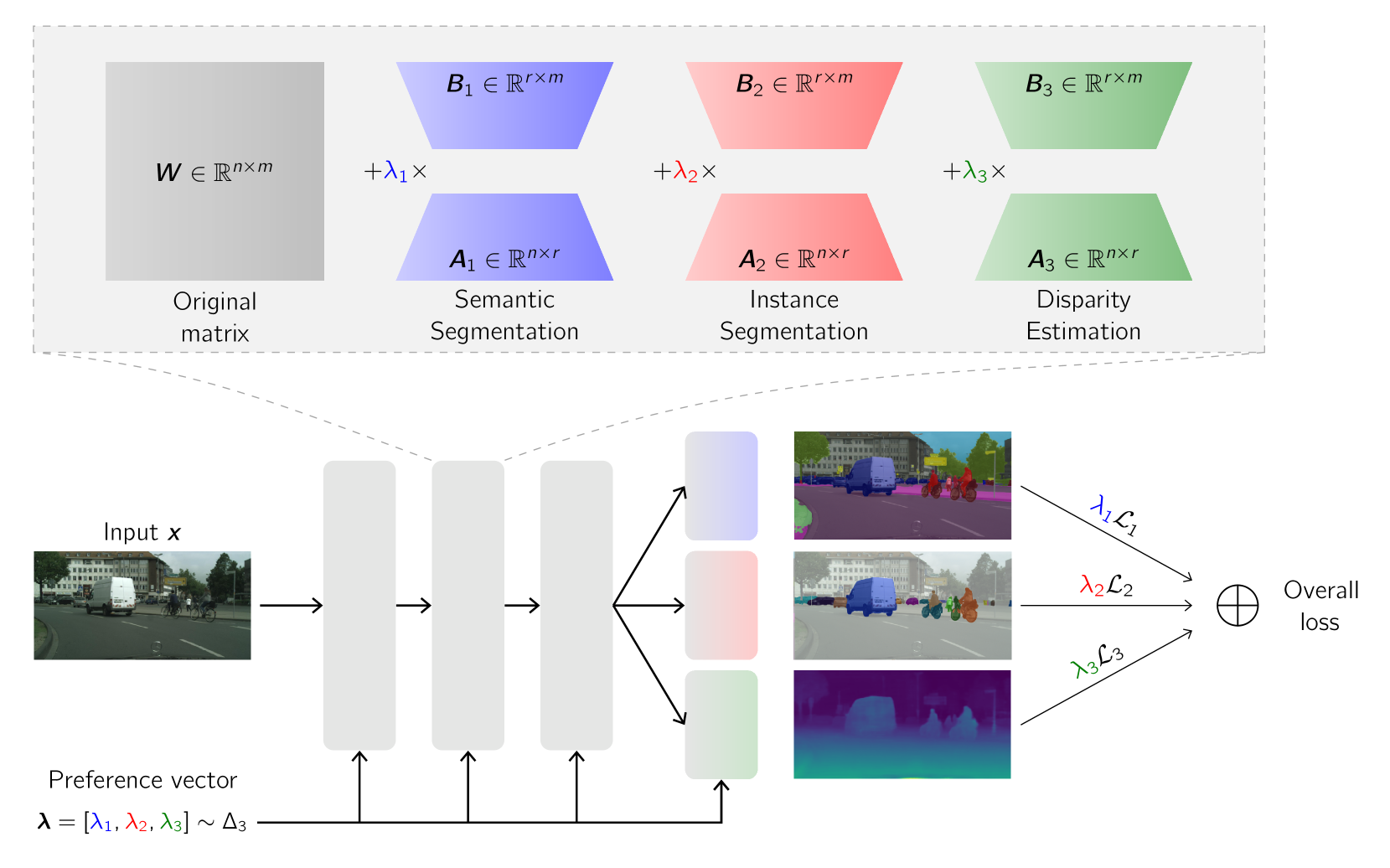
Multi-task learning, which optimizes performance across multiple tasks, is inherently a multi-objective optimization problem. Various algorithms are developed to provide discrete trade-off solutions on the Pareto front. Recently, continuous Pareto front approximations using a linear combination of base networks have emerged as a compelling strategy. However, it suffers from scalability issues when the number of tasks is large. To address this issue, we propose a novel approach that integrates a main network with several low-rank matrices to efficiently learn the Pareto manifold. It significantly reduces the number of parameters and facilitates the extraction of shared features. We also introduce orthogonal regularization to further bolster performance. Extensive experimental results demonstrate that the proposed approach outperforms state-of-the-art baselines, especially on datasets with a large number of tasks.
Read more7/31/2024
0
Pareto Low-Rank Adapters: Efficient Multi-Task Learning with Preferences
Nikolaos Dimitriadis, Pascal Frossard, Francois Fleuret
Dealing with multi-task trade-offs during inference can be addressed via Pareto Front Learning (PFL) methods that parameterize the Pareto Front with a single model, contrary to traditional Multi-Task Learning (MTL) approaches that optimize for a single trade-off which has to be decided prior to training. However, recent PFL methodologies suffer from limited scalability, slow convergence and excessive memory requirements compared to MTL approaches while exhibiting inconsistent mappings from preference space to objective space. In this paper, we introduce PaLoRA, a novel parameter-efficient method that augments the original model with task-specific low-rank adapters and continuously parameterizes the Pareto Front in their convex hull. Our approach dedicates the original model and the adapters towards learning general and task-specific features, respectively. Additionally, we propose a deterministic sampling schedule of preference vectors that reinforces this division of labor, enabling faster convergence and scalability to real world networks. Our experimental results show that PaLoRA outperforms MTL and PFL baselines across various datasets, scales to large networks and provides a continuous parameterization of the Pareto Front, reducing the memory overhead $23.8-31.7$ times compared with competing PFL baselines in scene understanding benchmarks.
Read more7/12/2024

0
Towards Efficient Pareto Set Approximation via Mixture of Experts Based Model Fusion
Anke Tang, Li Shen, Yong Luo, Shiwei Liu, Han Hu, Bo Du
Solving multi-objective optimization problems for large deep neural networks is a challenging task due to the complexity of the loss landscape and the expensive computational cost of training and evaluating models. Efficient Pareto front approximation of large models enables multi-objective optimization for various tasks such as multi-task learning and trade-off analysis. Existing algorithms for learning Pareto set, including (1) evolutionary, hypernetworks, and hypervolume-maximization methods, are computationally expensive and have restricted scalability to large models; (2) Scalarization algorithms, where a separate model is trained for each objective ray, which is inefficient for learning the entire Pareto set and fails to capture the objective trade-offs effectively. Inspired by the recent success of model merging, we propose a practical and scalable approach to Pareto set learning problem via mixture of experts (MoE) based model fusion. By ensembling the weights of specialized single-task models, the MoE module can effectively capture the trade-offs between multiple objectives and closely approximate the entire Pareto set of large neural networks. Once the routers are learned and a preference vector is set, the MoE module can be unloaded, thus no additional computational cost is introduced during inference. We conduct extensive experiments on vision and language tasks using large-scale models such as CLIP-ViT and GPT-2. The experimental results demonstrate that our method efficiently approximates the entire Pareto front of large models. Using only hundreds of trainable parameters of the MoE routers, our method even has lower memory usage compared to linear scalarization and algorithms that learn a single Pareto optimal solution, and are scalable to both the number of objectives and the size of the model.
Read more6/17/2024

0
Preference-Optimized Pareto Set Learning for Blackbox Optimization
Zhang Haishan, Diptesh Das, Koji Tsuda
Multi-Objective Optimization (MOO) is an important problem in real-world applications. However, for a non-trivial problem, no single solution exists that can optimize all the objectives simultaneously. In a typical MOO problem, the goal is to find a set of optimum solutions (Pareto set) that trades off the preferences among objectives. Scalarization in MOO is a well-established method for finding a finite set approximation of the whole Pareto set (PS). However, in real-world experimental design scenarios, it's beneficial to obtain the whole PS for flexible exploration of the design space. Recently Pareto set learning (PSL) has been introduced to approximate the whole PS. PSL involves creating a manifold representing the Pareto front of a multi-objective optimization problem. A naive approach includes finding discrete points on the Pareto front through randomly generated preference vectors and connecting them by regression. However, this approach is computationally expensive and leads to a poor PS approximation. We propose to optimize the preference points to be distributed evenly on the Pareto front. Our formulation leads to a bilevel optimization problem that can be solved by e.g. differentiable cross-entropy methods. We demonstrated the efficacy of our method for complex and difficult black-box MOO problems using both synthetic and real-world benchmark data.
Read more8/20/2024