Partially Observable Contextual Bandits with Linear Payoffs

0
Sign in to get full access
Overview
- The paper proposes a framework called EMKF-Bandit for partially observable contextual bandits with linear payoffs.
- It introduces an Exponential Gradient Descent algorithm that can handle partial observability and linear payoffs.
- The algorithm is shown to achieve near-optimal regret bounds under certain assumptions.
Plain English Explanation
The paper tackles the problem of contextual bandits - a type of machine learning problem where an agent needs to repeatedly choose the best action (e.g., which product to recommend to a customer) based on some context (e.g., the customer's browsing history).
The key twist in this paper is that the agent only has partial information about the context, rather than full visibility. This makes the problem more challenging, as the agent has to learn and make decisions with incomplete information.
The proposed EMKF-Bandit framework uses an Exponential Gradient Descent algorithm to address this partial observability, while also assuming that the payoffs (i.e., the rewards for each action) have a linear relationship with the context.
The main benefit of this approach is that it can achieve near-optimal regret bounds, meaning the algorithm's performance is close to the best possible outcome, even with the constraints of partial observability and linear payoffs.
Technical Explanation
The EMKF-Bandit framework models the partially observable contextual bandit problem as follows:
- The agent receives a context vector at each round, but only has partial access to this vector.
- The agent then selects an action, and receives a linear payoff that depends on the (unobserved) full context vector and a weight vector associated with the chosen action.
- The goal is to maximize the total payoff over a sequence of rounds, while only having access to the partial context information.
The key algorithmic component is the Exponential Gradient Descent update rule, which allows the agent to learn the weight vectors for each action while handling the partial observability.
The paper provides a regret analysis that shows this algorithm can achieve near-optimal regret bounds, meaning its performance is close to the best possible outcome for this problem setting.
Critical Analysis
The paper makes some important assumptions that limit the generality of the approach:
- It assumes the payoffs have a linear relationship with the context, which may not hold in all real-world scenarios.
- It also assumes the agent only has partial access to the context, but the specific nature of this partial observability is not explored in depth.
Additionally, the regret bounds provided in the paper are asymptotic, meaning they only hold for a large number of rounds. It would be helpful to understand the algorithm's performance in the finite-time regime as well.
Further research could explore relaxing the linearity assumption, as well as analyzing different partial observability models and their impact on the algorithm's performance.
Conclusion
The EMKF-Bandit framework proposed in this paper represents an interesting approach to the partially observable contextual bandit problem with linear payoffs.
The key contribution is the Exponential Gradient Descent algorithm, which can achieve near-optimal regret bounds under the stated assumptions.
While the assumptions limit the generality of the approach, this work provides a valuable foundation for further research in this area, potentially exploring more flexible models and relaxing the linearity constraint.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Partially Observable Contextual Bandits with Linear Payoffs
Sihan Zeng, Sujay Bhatt, Alec Koppel, Sumitra Ganesh
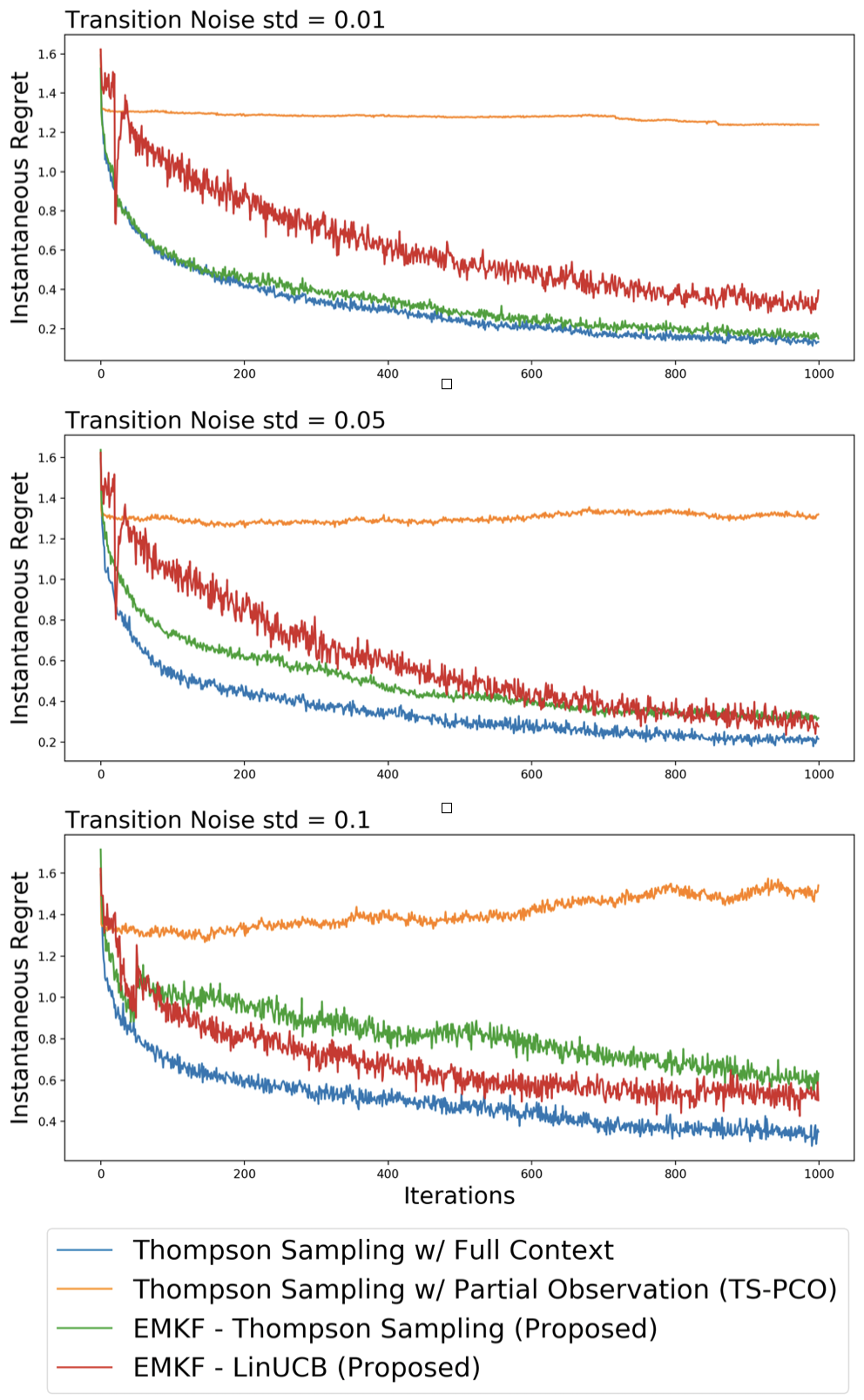
The standard contextual bandit framework assumes fully observable and actionable contexts. In this work, we consider a new bandit setting with partially observable, correlated contexts and linear payoffs, motivated by the applications in finance where decision making is based on market information that typically displays temporal correlation and is not fully observed. We make the following contributions marrying ideas from statistical signal processing with bandits: (i) We propose an algorithmic pipeline named EMKF-Bandit, which integrates system identification, filtering, and classic contextual bandit algorithms into an iterative method alternating between latent parameter estimation and decision making. (ii) We analyze EMKF-Bandit when we select Thompson sampling as the bandit algorithm and show that it incurs a sub-linear regret under conditions on filtering. (iii) We conduct numerical simulations that demonstrate the benefits and practical applicability of the proposed pipeline.
Read more9/19/2024
0
Batched Nonparametric Contextual Bandits
Rong Jiang, Cong Ma
We study nonparametric contextual bandits under batch constraints, where the expected reward for each action is modeled as a smooth function of covariates, and the policy updates are made at the end of each batch of observations. We establish a minimax regret lower bound for this setting and propose a novel batch learning algorithm that achieves the optimal regret (up to logarithmic factors). In essence, our procedure dynamically splits the covariate space into smaller bins, carefully aligning their widths with the batch size. Our theoretical results suggest that for nonparametric contextual bandits, a nearly constant number of policy updates can attain optimal regret in the fully online setting.
Read more6/12/2024
↗️
0
Contextual Bandits with Packing and Covering Constraints: A Modular Lagrangian Approach via Regression
Aleksandrs Slivkins, Xingyu Zhou, Karthik Abinav Sankararaman, Dylan J. Foster
We consider contextual bandits with linear constraints (CBwLC), a variant of contextual bandits in which the algorithm consumes multiple resources subject to linear constraints on total consumption. This problem generalizes contextual bandits with knapsacks (CBwK), allowing for packing and covering constraints, as well as positive and negative resource consumption. We provide the first algorithm for CBwLC (or CBwK) that is based on regression oracles. The algorithm is simple, computationally efficient, and statistically optimal under mild assumptions. Further, we provide the first vanishing-regret guarantees for CBwLC (or CBwK) that extend beyond the stochastic environment. We side-step strong impossibility results from prior work by identifying a weaker (and, arguably, fairer) benchmark to compare against. Our algorithm builds on LagrangeBwK (Immorlica et al., FOCS 2019), a Lagrangian-based technique for CBwK, and SquareCB (Foster and Rakhlin, ICML 2020), a regression-based technique for contextual bandits. Our analysis leverages the inherent modularity of both techniques.
Read more7/2/2024
🤯
0
Anytime-valid off-policy inference for contextual bandits
Ian Waudby-Smith, Lili Wu, Aaditya Ramdas, Nikos Karampatziakis, Paul Mineiro
Contextual bandit algorithms are ubiquitous tools for active sequential experimentation in healthcare and the tech industry. They involve online learning algorithms that adaptively learn policies over time to map observed contexts $X_t$ to actions $A_t$ in an attempt to maximize stochastic rewards $R_t$. This adaptivity raises interesting but hard statistical inference questions, especially counterfactual ones: for example, it is often of interest to estimate the properties of a hypothetical policy that is different from the logging policy that was used to collect the data -- a problem known as ``off-policy evaluation'' (OPE). Using modern martingale techniques, we present a comprehensive framework for OPE inference that relax unnecessary conditions made in some past works, significantly improving on them both theoretically and empirically. Importantly, our methods can be employed while the original experiment is still running (that is, not necessarily post-hoc), when the logging policy may be itself changing (due to learning), and even if the context distributions are a highly dependent time-series (such as if they are drifting over time). More concretely, we derive confidence sequences for various functionals of interest in OPE. These include doubly robust ones for time-varying off-policy mean reward values, but also confidence bands for the entire cumulative distribution function of the off-policy reward distribution. All of our methods (a) are valid at arbitrary stopping times (b) only make nonparametric assumptions, (c) do not require importance weights to be uniformly bounded and if they are, we do not need to know these bounds, and (d) adapt to the empirical variance of our estimators. In summary, our methods enable anytime-valid off-policy inference using adaptively collected contextual bandit data.
Read more8/19/2024