People use fast, goal-directed simulation to reason about novel games

0

Sign in to get full access
Overview
- People use quick, goal-oriented simulations to reason about new games
- This paper proposes a computational model of "intuitive game theory" to explain human strategic reasoning
- Experiments show people can quickly learn and make strategic decisions in novel games using this approach
Plain English Explanation
Humans are remarkably adept at understanding and playing novel games, even those with complex rules. This paper suggests that we do this by using a form of fast, goal-directed simulation to reason about the game.
Rather than explicitly calculating an optimal strategy, we seem to rapidly simulate potential moves and outcomes in our minds, focusing on achieving our goals. This "intuitive game theory" allows us to quickly learn the game's dynamics and make strategic decisions, without needing to fully comprehend all the underlying rules.
The researchers demonstrate this through experiments where people play novel games and exhibit this flexible, goal-driven reasoning. Even with limited training, participants are able to learn the games' mechanics and devise effective strategies, suggesting an innate human capacity for this type of strategic thinking.
Technical Explanation
The paper proposes a computational model of "intuitive game theory" to explain how people reason about novel strategic situations. The key components are:
-
Fast, goal-directed simulation: Rather than exhaustively analyzing all possible moves, people rapidly simulate potential sequences of actions focused on achieving their objectives.
-
Outcome prediction: The simulations estimate the likely outcomes of different moves, allowing people to assess the strategic value of their options.
-
Flexible strategy selection: People dynamically adjust their strategies based on the game's evolving dynamics, exhibiting more nuanced decision-making than simple rule-following.
Experiments show that even with minimal training, people can quickly learn the mechanics of novel games and devise effective strategies using this intuitive game theory approach. This suggests humans have a remarkable capacity for flexible, goal-oriented strategic reasoning.
Critical Analysis
The paper provides a compelling account of human strategic decision-making, but it also acknowledges several limitations and open questions:
- The experiments focus on relatively simple, two-player games, so it's unclear how well the model generalizes to more complex, multi-agent scenarios.
- The simulation process is not fully specified, leaving room for further refinement and validation.
- It's uncertain whether this intuitive game theory approach is truly "fast" compared to other potential cognitive mechanisms, or if it simply appears fast due to the limitations of the experiments.
Despite these caveats, the research provides a valuable step towards understanding the remarkable human capacity for strategic reasoning, with potential implications for the design of artificial intelligence systems and our understanding of cognitive processes.
Conclusion
This paper proposes a computational model of "intuitive game theory" to explain how people reason about novel strategic situations. By using fast, goal-directed simulations to predict outcomes and flexibly select strategies, humans exhibit a remarkable capacity for learning and decision-making in complex, dynamic environments.
The research offers insights into the cognitive mechanisms underlying human strategic reasoning, with potential applications in the design of AI systems, the study of decision-making, and our understanding of the human mind. While the model has some limitations, it represents an important step towards a more comprehensive account of this fundamental aspect of human intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
People use fast, goal-directed simulation to reason about novel games
Cedegao E. Zhang, Katherine M. Collins, Lionel Wong, Adrian Weller, Joshua B. Tenenbaum
We can evaluate features of problems and their potential solutions well before we can effectively solve them. When considering a game we have never played, for instance, we might infer whether it is likely to be challenging, fair, or fun simply from hearing the game rules, prior to deciding whether to invest time in learning the game or trying to play it well. Many studies of game play have focused on optimality and expertise, characterizing how people and computational models play based on moderate to extensive search and after playing a game dozens (if not thousands or millions) of times. Here, we study how people reason about a range of simple but novel connect-n style board games. We ask people to judge how fair and how fun the games are from very little experience: just thinking about the game for a minute or so, before they have ever actually played with anyone else, and we propose a resource-limited model that captures their judgments using only a small number of partial game simulations and almost no lookahead search.
Read more7/22/2024
0
LogicGame: Benchmarking Rule-Based Reasoning Abilities of Large Language Models
Jiayi Gui, Yiming Liu, Jiale Cheng, Xiaotao Gu, Xiao Liu, Hongning Wang, Yuxiao Dong, Jie Tang, Minlie Huang
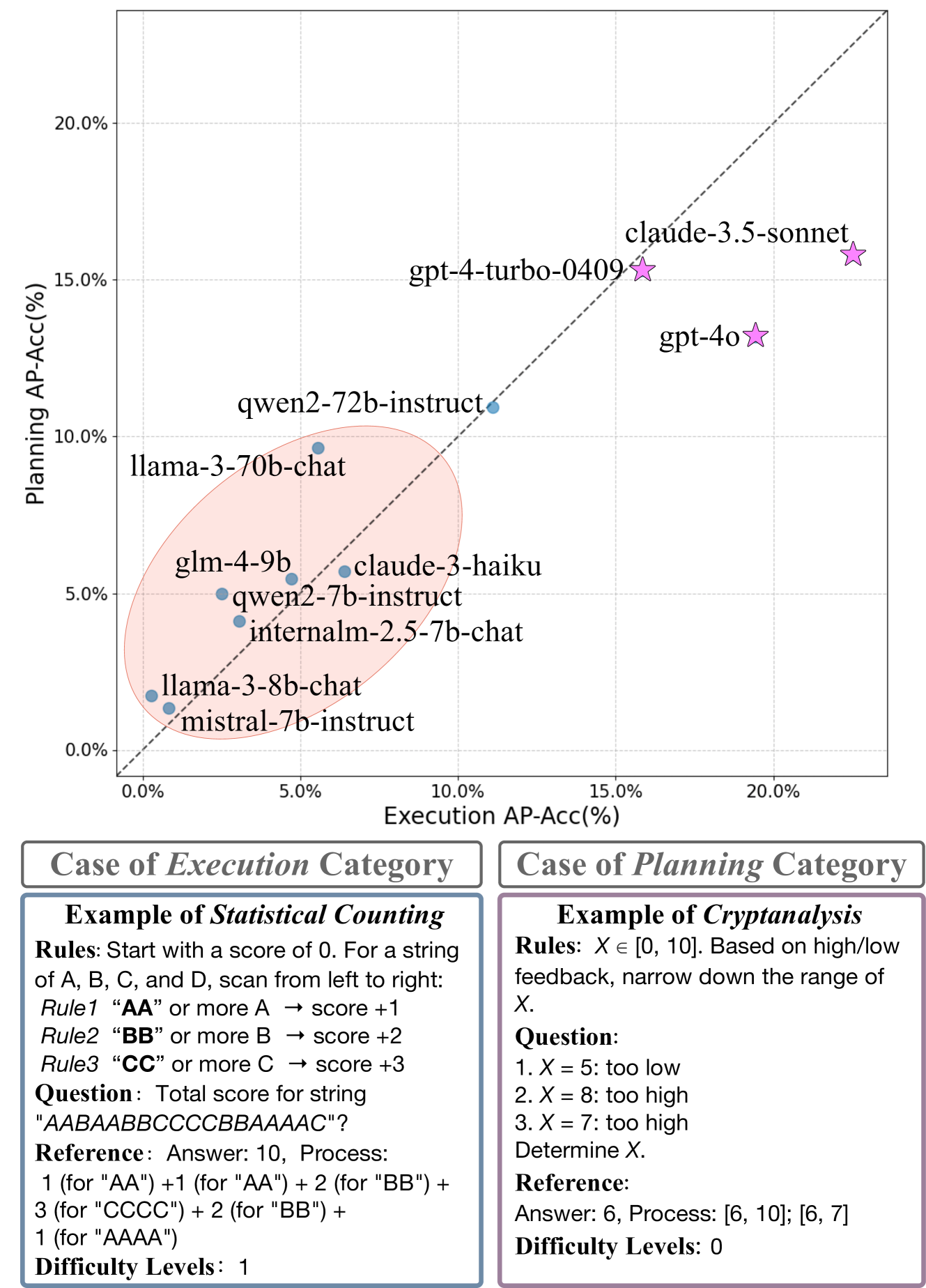
Large Language Models (LLMs) have demonstrated notable capabilities across various tasks, showcasing complex problem-solving abilities. Understanding and executing complex rules, along with multi-step planning, are fundamental to logical reasoning and critical for practical LLM agents and decision-making systems. However, evaluating LLMs as effective rule-based executors and planners remains underexplored. In this paper, we introduce LogicGame, a novel benchmark designed to evaluate the comprehensive rule understanding, execution, and planning capabilities of LLMs. Unlike traditional benchmarks, LogicGame provides diverse games that contain a series of rules with an initial state, requiring models to comprehend and apply predefined regulations to solve problems. We create simulated scenarios in which models execute or plan operations to achieve specific outcomes. These game scenarios are specifically designed to distinguish logical reasoning from mere knowledge by relying exclusively on predefined rules. This separation allows for a pure assessment of rule-based reasoning capabilities. The evaluation considers not only final outcomes but also intermediate steps, providing a comprehensive assessment of model performance. Moreover, these intermediate steps are deterministic and can be automatically verified. LogicGame defines game scenarios with varying difficulty levels, from simple rule applications to complex reasoning chains, in order to offer a precise evaluation of model performance on rule understanding and multi-step execution. Utilizing LogicGame, we test various LLMs and identify notable shortcomings in their rule-based logical reasoning abilities.
Read more9/6/2024

0
GameBench: Evaluating Strategic Reasoning Abilities of LLM Agents
Anthony Costarelli, Mat Allen, Roman Hauksson, Grace Sodunke, Suhas Hariharan, Carlson Cheng, Wenjie Li, Joshua Clymer, Arjun Yadav
Large language models have demonstrated remarkable few-shot performance on many natural language understanding tasks. Despite several demonstrations of using large language models in complex, strategic scenarios, there lacks a comprehensive framework for evaluating agents' performance across various types of reasoning found in games. To address this gap, we introduce GameBench, a cross-domain benchmark for evaluating strategic reasoning abilities of LLM agents. We focus on 9 different game environments, where each covers at least one axis of key reasoning skill identified in strategy games, and select games for which strategy explanations are unlikely to form a significant portion of models' pretraining corpuses. Our evaluations use GPT-3 and GPT-4 in their base form along with two scaffolding frameworks designed to enhance strategic reasoning ability: Chain-of-Thought (CoT) prompting and Reasoning Via Planning (RAP). Our results show that none of the tested models match human performance, and at worst GPT-4 performs worse than random action. CoT and RAP both improve scores but not comparable to human levels.
Read more7/23/2024

0
Games of Knightian Uncertainty
Spyridon Samothrakis, Dennis J. N. J. Soemers, Damian Machlanski
Arguably, for the latter part of the late 20th and early 21st centuries, games have been seen as the drosophila of AI. Games are a set of exciting testbeds, whose solutions (in terms of identifying optimal players) would lead to machines that would possess some form of general intelligence, or at the very least help us gain insights toward building intelligent machines. Following impressive successes in traditional board games like Go, Chess, and Poker, but also video games like the Atari 2600 collection, it is clear that this is not the case. Games have been attacked successfully, but we are nowhere near AGI developments (or, as harsher critics might say, useful AI developments!). In this short vision paper, we argue that for game research to become again relevant to the AGI pathway, we need to be able to address textit{Knightian uncertainty} in the context of games, i.e. agents need to be able to adapt to rapid changes in game rules on the fly with no warning, no previous data, and no model access.
Read more6/28/2024