Perceiver-Prompt: Flexible Speaker Adaptation in Whisper for Chinese Disordered Speech Recognition

0

Sign in to get full access
Overview
- This paper introduces a flexible speaker adaptation approach called "Perceiver-Prompt" for improving the performance of the Whisper model on Chinese disordered speech recognition.
- The proposed method leverages prompting techniques to efficiently adapt the Whisper model to different speakers, without requiring full model fine-tuning.
- The authors demonstrate the effectiveness of Perceiver-Prompt on several Chinese disordered speech datasets, achieving significant performance gains over the original Whisper model.
Plain English Explanation
The paper discusses a new way to improve the performance of the Whisper speech recognition model when dealing with speakers who have speech disorders or atypical speech patterns. The key idea is to use "prompting" techniques, which involve providing the model with additional information or instructions to help it adapt to the speaker's unique characteristics.
Typically, to adapt a speech recognition model to a new speaker, you would need to fine-tune the entire model on data from that speaker. This can be time-consuming and require a lot of data. The Perceiver-Prompt approach instead allows the model to be quickly adapted using just a short prompt, without having to retrain the entire model.
The authors tested this approach on several datasets of Chinese speakers with speech disorders, and found that it significantly improved the accuracy of the Whisper model compared to using the original, unadapted model. This suggests that Perceiver-Prompt could be a useful technique for making speech recognition systems more robust and accessible to people with diverse speech patterns.
Technical Explanation
The paper introduces a flexible speaker adaptation approach called "Perceiver-Prompt" for improving the performance of the Whisper model on Chinese disordered speech recognition. Perceiver-Prompt: Flexible Speaker Adaptation in Whisper for Chinese Disordered Speech Recognition
The key idea is to leverage prompting techniques to efficiently adapt the Whisper model to different speakers, without requiring full model fine-tuning. Keyword-Guided Adaptation for Automatic Speech Recognition The authors introduce a Perceiver-Prompt module that takes in the input audio and a speaker-specific prompt, and outputs adapted features that are then fed into the Whisper model.
The authors evaluate the Perceiver-Prompt approach on several Chinese disordered speech datasets, including CHDSP, UESTC, and KLSCDD. They demonstrate that their method significantly outperforms the original Whisper model, as well as other baseline adaptation techniques such as LORA-Whisper: Parameter-Efficient, Extensible, Multilingual ASR and a multitask training approach.
Critical Analysis
The paper provides a compelling approach for adapting the Whisper speech recognition model to handle speakers with disordered speech, a common challenge in real-world applications. The authors' use of prompting techniques is an interesting alternative to standard fine-tuning approaches, which can be time-consuming and data-intensive.
However, the paper does not address some potential limitations of the Perceiver-Prompt method. For example, it's unclear how well the approach would generalize to speakers with very different types of speech disorders, or how the performance might scale as the diversity of the speaker population increases. Do Prompts Really Prompt? Exploring Prompt Understanding
Additionally, the authors only evaluate their method on Chinese disordered speech datasets, so it's uncertain how well it would perform on other languages or dialects. Further research could explore the cross-lingual or cross-dialectal transferability of the Perceiver-Prompt approach.
Conclusion
The Perceiver-Prompt method introduced in this paper represents an innovative approach to speaker adaptation for speech recognition, particularly for users with disordered speech. By leveraging prompting techniques, the authors have demonstrated a flexible and efficient way to improve the performance of the Whisper model on challenging speech datasets.
This work has the potential to make speech recognition systems more accessible and inclusive, by allowing them to better accommodate the diverse speech patterns found in real-world scenarios. As the use of speech technology becomes more widespread, methods like Perceiver-Prompt will be increasingly important for ensuring that these systems work well for all users, regardless of their speech characteristics.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Perceiver-Prompt: Flexible Speaker Adaptation in Whisper for Chinese Disordered Speech Recognition
Yicong Jiang, Tianzi Wang, Xurong Xie, Juan Liu, Wei Sun, Nan Yan, Hui Chen, Lan Wang, Xunying Liu, Feng Tian
Disordered speech recognition profound implications for improving the quality of life for individuals afflicted with, for example, dysarthria. Dysarthric speech recognition encounters challenges including limited data, substantial dissimilarities between dysarthric and non-dysarthric speakers, and significant speaker variations stemming from the disorder. This paper introduces Perceiver-Prompt, a method for speaker adaptation that utilizes P-Tuning on the Whisper large-scale model. We first fine-tune Whisper using LoRA and then integrate a trainable Perceiver to generate fixed-length speaker prompts from variable-length inputs, to improve model recognition of Chinese dysarthric speech. Experimental results from our Chinese dysarthric speech dataset demonstrate consistent improvements in recognition performance with Perceiver-Prompt. Relative reduction up to 13.04% in CER is obtained over the fine-tuned Whisper.
Read more6/17/2024
🏅
0
PI-Whisper: An Adaptive and Incremental ASR Framework for Diverse and Evolving Speaker Characteristics
Amir Nassereldine, Dancheng Liu, Chenhui Xu, Jinjun Xiong
As edge-based automatic speech recognition (ASR) technologies become increasingly prevalent for the development of intelligent and personalized assistants, three important challenges must be addressed for these resource-constrained ASR models, i.e., adaptivity, incrementality, and inclusivity. We propose a novel ASR framework, PI-Whisper, in this work and show how it can improve an ASR's recognition capabilities adaptively by identifying different speakers' characteristics in real-time, how such an adaption can be performed incrementally without repetitive retraining, and how it can improve the equity and fairness for diverse speaker groups. More impressively, our proposed PI-Whisper framework attains all of these nice properties while still achieving state-of-the-art accuracy with up to 13.7% reduction of the word error rate (WER) with linear scalability with respect to computing resources.
Read more6/26/2024
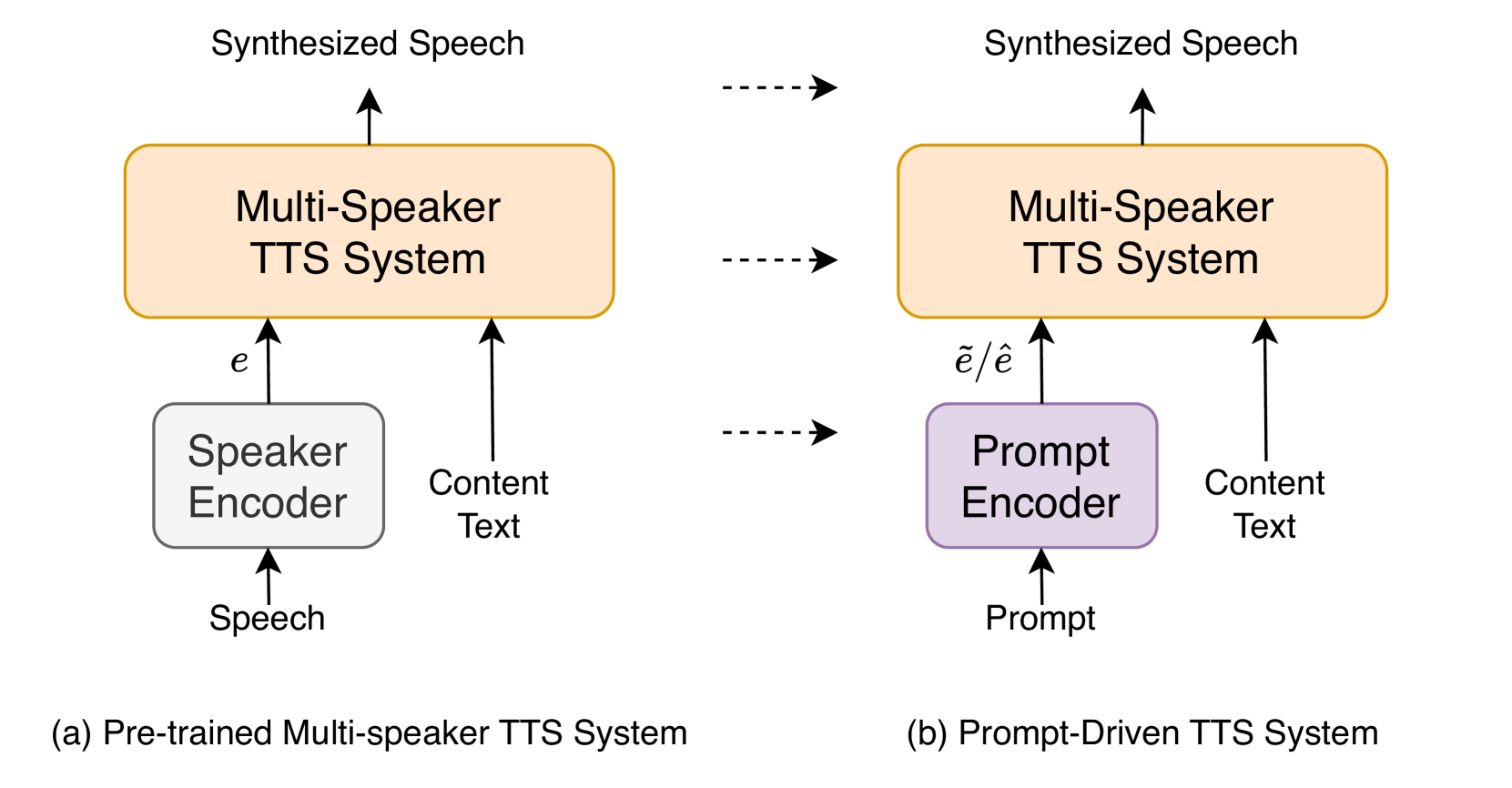
0
Generating Speakers by Prompting Listener Impressions for Pre-trained Multi-Speaker Text-to-Speech Systems
Zhengyang Chen, Xuechen Liu, Erica Cooper, Junichi Yamagishi, Yanmin Qian
This paper proposes a speech synthesis system that allows users to specify and control the acoustic characteristics of a speaker by means of prompts describing the speaker's traits of synthesized speech. Unlike previous approaches, our method utilizes listener impressions to construct prompts, which are easier to collect and align more naturally with everyday descriptions of speaker traits. We adopt the Low-rank Adaptation (LoRA) technique to swiftly tailor a pre-trained language model to our needs, facilitating the extraction of speaker-related traits from the prompt text. Besides, different from other prompt-driven text-to-speech (TTS) systems, we separate the prompt-to-speaker module from the multi-speaker TTS system, enhancing system flexibility and compatibility with various pre-trained multi-speaker TTS systems. Moreover, for the prompt-to-speaker characteristic module, we also compared the discriminative method and flow-matching based generative method and we found that combining both methods can help the system simultaneously capture speaker-related information from prompts better and generate speech with higher fidelity.
Read more6/14/2024

0
Empowering Whisper as a Joint Multi-Talker and Target-Talker Speech Recognition System
Lingwei Meng, Jiawen Kang, Yuejiao Wang, Zengrui Jin, Xixin Wu, Xunying Liu, Helen Meng
Multi-talker speech recognition and target-talker speech recognition, both involve transcription in multi-talker contexts, remain significant challenges. However, existing methods rarely attempt to simultaneously address both tasks. In this study, we propose a pioneering approach to empower Whisper, which is a speech foundation model, to tackle joint multi-talker and target-talker speech recognition tasks. Specifically, (i) we freeze Whisper and plug a Sidecar separator into its encoder to separate mixed embedding for multiple talkers; (ii) a Target Talker Identifier is introduced to identify the embedding flow of the target talker on the fly, requiring only three-second enrollment speech as a cue; (iii) soft prompt tuning for decoder is explored for better task adaptation. Our method outperforms previous methods on two- and three-talker LibriMix and LibriSpeechMix datasets for both tasks, and delivers acceptable zero-shot performance on multi-talker ASR on AishellMix Mandarin dataset.
Read more8/27/2024